基于TensorFlow图像数据的深度网络标注、建模与训练
model
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.RandomRotation(0.1),
layers.RandomZoom(0.1),
]
)
model = Sequential([
data_augmentation,
layers.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes, name="outputs")
])

卷积网络

传统的神经网络使用矩阵乘法来建立输入与输出的连接关系。其中,参数矩阵中每一个单独的参数都描述了一个输入单元与一个输出单元间的交互。这意味着每一个输出单元与每一个输入单元都产生交互。然而,卷积网络具有稀疏交互(sparse interactions)(也叫做稀疏连接(sparse connectivity)或者稀疏权重(sparse weights))的特征。这是使核的大小远小于输入的大小来达到的。举个例子,当处理一张图像时,输入的图像可能包含成千上万个像素点,但是我们可以通过只占用几十到上百个像素点的核来检测一些小的有意义的特征,例如图像的边缘。这意味着我们需要存储的参数更少,不仅减少了模型的存储需求,而且提高了它的统计效率。这也意味着为了得到输出我们只需要更少的计算量。这些效率上的提高往往是很显著的。如果有m个输入和n个输出,那么矩阵乘法需要mn个参数并且相应算法的时间复杂度为O(mn)(对于每一个例子)。如果我们限制每一个输出拥有的连接数为k,那么稀疏的连接方法只需要kn个参数以及O(kn)的运行时间。在很多实际应用中,只需保持k比m小几个数量级,就能在机器学习的任务中取得好的表现。
边缘检测

边缘检测的效率。右边的图像是通过先获得原始图像中的每个像素,然后减去左边相邻像素的值而形成的。这个操作给出了输入图像中所有垂直方向上的边缘的强度,对目标检测来说是有用的。两个图像的高度均为280个像素。输入图像的宽度为320个像素,而输出图像的宽度为319个像素。这个变换可以通过包含两个元素的卷积核来描述,使用卷积需要319x280x3=267,960次浮点运算(每个输出像素需要两次乘法和一次加法)。为了用矩阵乘法描述相同的变换,需要280x(320+319)x319=57,075,480次浮点运算,将小的局部区域上的相同线性变换应用到整个输入上,卷积是描述这种变换的极其有效的方法。
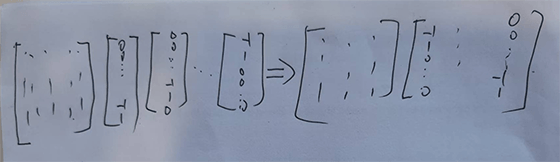
池化

池化函数使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。例如,最大池化(max pooling)函数(Zhou and Chellappa,1988)给出相邻矩形区域内的最大值。其他常用的池化函数包括相邻矩形区域内的平均值、L2范数以及基于据中心像素距离的加权平均函数。 不管采用什么样的池化函数,当输入作出少量平移时,池化能够帮助输入的表示近似不变(invariant)。对于平移的不变性是指当我们对输入进行少量平移时,经过池化函数后的大多数输出并不会发生改变。图9.8用了一个例子来说明这是如何实现的。局部平移不变性是一个很有用的性质,尤其是当我们关心某个特征是否出现而不关心它出现的具体位置时。例如,当判定一张图像中是否包含人脸时,我们并不需要知道眼睛的精确像素位置,我们只需要知道有一只眼睛在脸的左边,有一只在右边就行了。但在一些其他领域,保存特征的具体位置却很重要。例如当我们想要寻找一个由两条边相交而成的拐角时,我们就需要很好地保存边的位置来判定它们是否相交。
x = np.array([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]])
x = np.reshape(x, [1, 3, 3, 1])
max_pool_2d = keras.layers.MaxPooling2D(padding="same")
max_pool_2d(x)
结果:
x=
array([[[[1.],
[2.],
[3.]],
[[4.],
[5.],
[6.]],
[[7.],
[8.],
[9.]]]])
max_pool_2d(x) =
<tf.Tensor: shape=(1, 2, 2, 1), dtype=float32, numpy=
array([[[[5.],
[6.]],
[[8.],
[9.]]]], dtype=float32)>
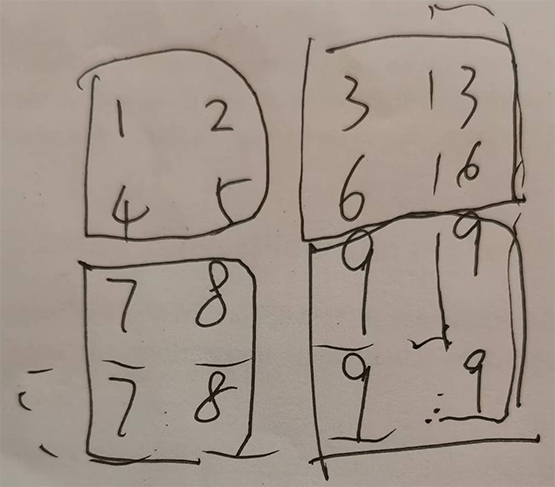
可视化

Q/A
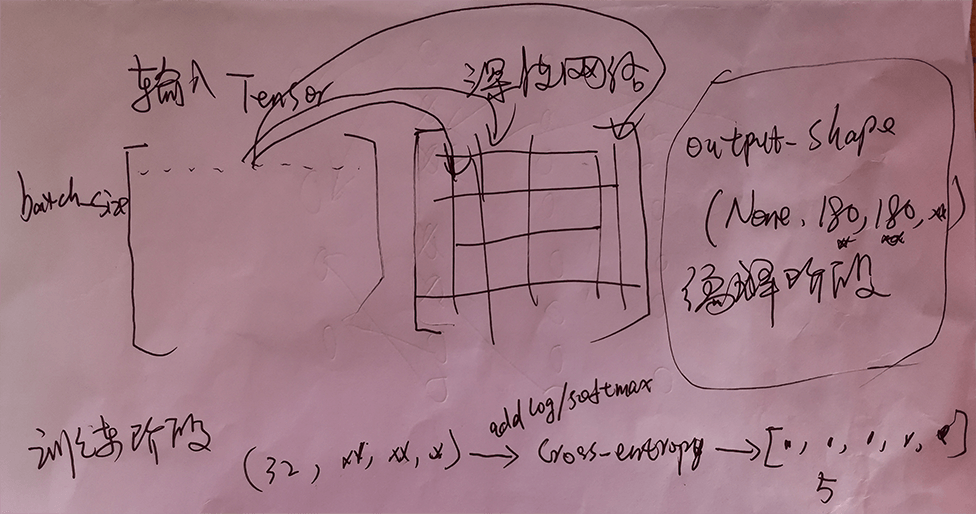
1.图像是否会失真(原始图像尺寸和image_size并不完全一致)
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
2.训练会得到什么结果
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)) -->
layers.Rescaling(1/255, input_shape=(img_height, img_width, 3))
3.数据增强并没有改变输入数据集,但是为什么能起到改善过拟合的作用
4.dropout是否可能形成中间层的闭环、即没有输入会经过dropout后的网络
5.train_ds共92个batch,每次从train_ds取出1个batch用于训练,1个epoch共反向传播调参92次,两个epoch中这92个batch的数据完全一致吗?是一致更好还是不一致更好?
6.哪些层的输出可能会出现负数,而哪些层的输出可定不会出现负数
7.训练出的结果是否可能出现几乎无泛化能力,即模型预测结果正确率极低?如果有,在不改变数据集和模型的情况下,是在什么情况下训练出来的
8.为什么每层输出均有一个名为None的维度,这个维度在训练和预测时有什么实际意义
9.dropout层并不会改变输入维度(shape size),据此推测dropout层是如何实现的
10.如何计算每一层输出维度与参数(Trainable params)个数
其他
seed
在tensorflow中,很多函数中都会有seed参数,意为"种子"。这里seed实际上代表着随机数的序号。该序号与每个随机数相对应,相当于随机数固定存放在数组中,而seed参数则相当于随机数在数组中的下标索引。如果设置了seed的值,则每次执行程序所产生的随机数或者随机序列均相等,即都为同一个随机数或者随机序列。原因是,每次执行程序都会产生同一个位置处(seed的值)的随机数或者随机序列。如果没有设置seed参数的取值,那么每次执行程序所产生的随机数或者随机序列均不等。
Flatten层
Flatten层用来将输入"压平",即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。 从vgg16网络中可以看出,但是在后来的网络中用GlobalAveragePooling2D代替了flatten层,可以从vgg16与inceptionV3网络对比看出。从参数的对比可以看出,显然这种改进大大的减少了参数的使用量,避免了过拟合现象。
Dense
Dense即全连接层
ReLU

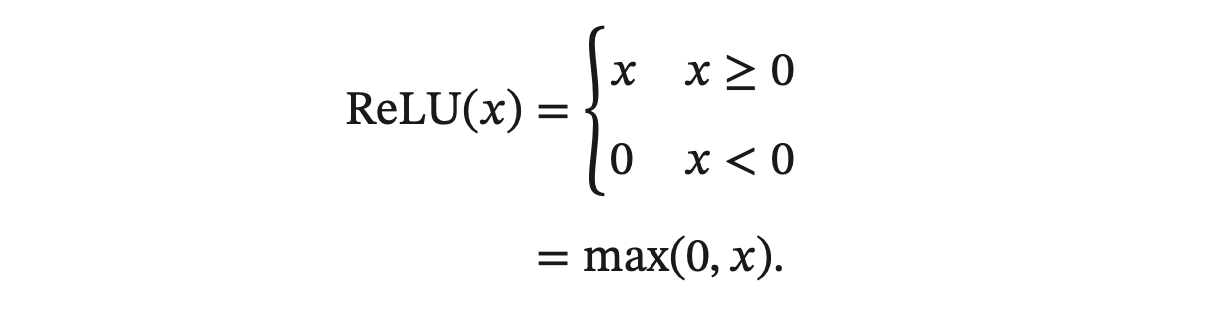
conv2d中padding=same规则介绍
dataset shuffle(洗牌)
train_ds.cache().shuffle(1000)
.shuffle(1000): This method shuffles the elements of the dataset.
The argument 1000 specifies the buffer_size.
The shuffle operation maintains a buffer of buffer_size elements and randomly samples from this buffer.
A larger buffer_size generally leads to better shuffling,
as it allows for a wider range of elements to be chosen from.
However, a very large buffer_size can consume significant memory.
The optimal buffer_size depends on the dataset size and available memory.
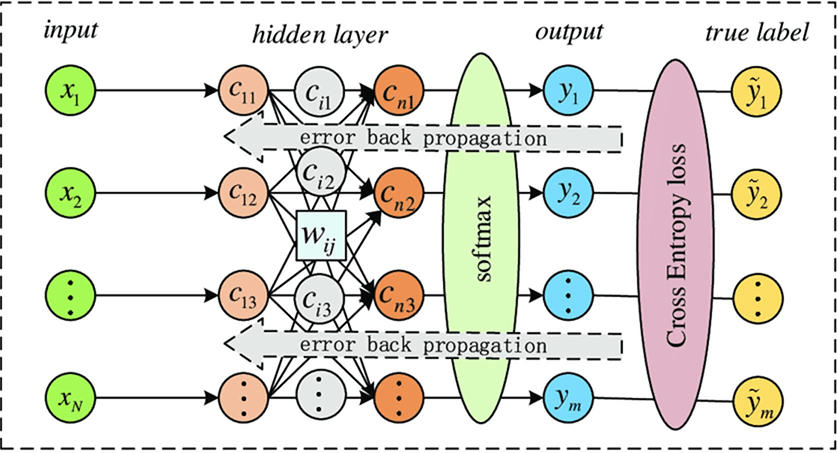
sparse/binary_categorical_crossentropy
交叉熵:衡量真实分布和预测分布之间的差异性、凸、梯度不易饱和性(输出值接近0/1时,均方误差的梯度非常小)
1、二元分类

2、多分类
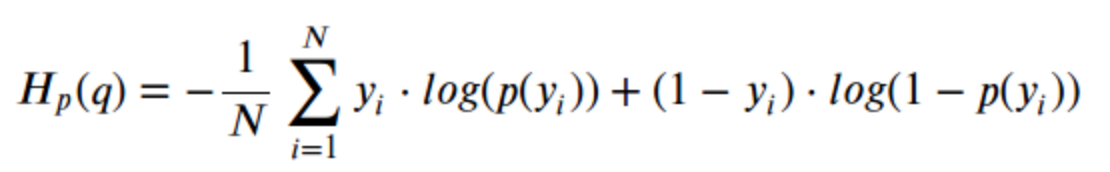
from_logits=True:在model尾端增加一softmax层,
layer_output_shape
深度学习
任务抽象
数据集:D={x1, x2,…,xm},d个属性 xi=(xi1,xi2,xi3,…,xid)ϵχ(输入空间)ϵ样本空间Ð
训练集:{(x1,y1), (x2,y2),…(xm,ym)},yiϵγ(标记空间、输出空间)
学习/训练 f: χ→γ,对于二分任务γ={0,1},对于多分类|γ|>2,对于回归任务γ=R。
监督学习:分类与回归;无监督学习:聚类。
泛化能力、独立同分布。
天下没有免费午餐


DL
深度神经网络的目标并不是完美地给大脑建模,而是受到神经科学中生物神经元计算功能观测的启发,但更多的则来自数学与软件工程学的指引;其目标是为了实现泛化(以已知预测未知)、使用数值计算方法而设计出来的函数近似机。












深度学习
任务抽象
数据集:D={x1, x2,…,xm},d个属性 xi=(xi1,xi2,xi3,…,xid)ϵχ(输入空间)ϵ样本空间Ð
训练集:{(x1,y1), (x2,y2),…(xm,ym)},yiϵγ(标记空间、输出空间)
学习/训练 f: χ→γ,对于二分任务γ={0,1},对于多分类|γ|>2,对于回归任务γ=R。
监督学习:分类与回归;无监督学习:聚类。
泛化能力、独立同分布。
天下没有免费午餐
DL
深度神经网络的目标并不是完美地给大脑建模,而是受到神经科学中生物神经元计算功能观测的启发,但更多的则来自数学与软件工程学的指引;其目标是为了实现泛化(以已知预测未知)、使用数值计算方法而设计出来的函数近似机。
基于TensorFlow图像数据的深度网络标注、建模与训练
model
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.RandomRotation(0.1),
layers.RandomZoom(0.1),
]
)
model = Sequential([
data_augmentation,
layers.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes, name="outputs")
])
卷积网络
传统的神经网络使用矩阵乘法来建立输入与输出的连接关系。其中,参数矩阵中每一个单独的参数都描述了一个输入单元与一个输出单元间的交互。这意味着每一个输出单元与每一个输入单元都产生交互。然而,卷积网络具有稀疏交互(sparse interactions)(也叫做稀疏连接(sparse connectivity)或者稀疏权重(sparse weights))的特征。这是使核的大小远小于输入的大小来达到的。举个例子,当处理一张图像时,输入的图像可能包含成千上万个像素点,但是我们可以通过只占用几十到上百个像素点的核来检测一些小的有意义的特征,例如图像的边缘。这意味着我们需要存储的参数更少,不仅减少了模型的存储需求,而且提高了它的统计效率。这也意味着为了得到输出我们只需要更少的计算量。这些效率上的提高往往是很显著的。如果有m个输入和n个输出,那么矩阵乘法需要mn个参数并且相应算法的时间复杂度为O(mn)(对于每一个例子)。如果我们限制每一个输出拥有的连接数为k,那么稀疏的连接方法只需要kn个参数以及O(kn)的运行时间。在很多实际应用中,只需保持k比m小几个数量级,就能在机器学习的任务中取得好的表现。
边缘检测
边缘检测的效率。右边的图像是通过先获得原始图像中的每个像素,然后减去左边相邻像素的值而形成的。这个操作给出了输入图像中所有垂直方向上的边缘的强度,对目标检测来说是有用的。两个图像的高度均为280个像素。输入图像的宽度为320个像素,而输出图像的宽度为319个像素。这个变换可以通过包含两个元素的卷积核来描述,使用卷积需要319x280x3=267,960次浮点运算(每个输出像素需要两次乘法和一次加法)。为了用矩阵乘法描述相同的变换,需要280x(320+319)x319=57,075,480次浮点运算,将小的局部区域上的相同线性变换应用到整个输入上,卷积是描述这种变换的极其有效的方法。
池化
池化函数使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。例如,最大池化(max pooling)函数(Zhou and Chellappa,1988)给出相邻矩形区域内的最大值。其他常用的池化函数包括相邻矩形区域内的平均值、L2范数以及基于据中心像素距离的加权平均函数。 不管采用什么样的池化函数,当输入作出少量平移时,池化能够帮助输入的表示近似不变(invariant)。对于平移的不变性是指当我们对输入进行少量平移时,经过池化函数后的大多数输出并不会发生改变。图9.8用了一个例子来说明这是如何实现的。局部平移不变性是一个很有用的性质,尤其是当我们关心某个特征是否出现而不关心它出现的具体位置时。例如,当判定一张图像中是否包含人脸时,我们并不需要知道眼睛的精确像素位置,我们只需要知道有一只眼睛在脸的左边,有一只在右边就行了。但在一些其他领域,保存特征的具体位置却很重要。例如当我们想要寻找一个由两条边相交而成的拐角时,我们就需要很好地保存边的位置来判定它们是否相交。
x = np.array([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]])
x = np.reshape(x, [1, 3, 3, 1])
max_pool_2d = keras.layers.MaxPooling2D(padding="same")
max_pool_2d(x)
结果:
x=
array([[[[1.],
[2.],
[3.]],
[[4.],
[5.],
[6.]],
[[7.],
[8.],
[9.]]]])
max_pool_2d(x) =
<tf.Tensor: shape=(1, 2, 2, 1), dtype=float32, numpy=
array([[[[5.],
[6.]],
[[8.],
[9.]]]], dtype=float32)>
可视化
Q/A
1.图像是否会失真(原始图像尺寸和image_size并不完全一致)
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
2.训练会得到什么结果
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)) -->
layers.Rescaling(1/255, input_shape=(img_height, img_width, 3))
3.数据增强并没有改变输入数据集,但是为什么能起到改善过拟合的作用
4.dropout是否可能形成中间层的闭环、即没有输入会经过dropout后的网络
5.train_ds共92个batch,每次从train_ds取出1个batch用于训练,1个epoch共反向传播调参92次,两个epoch中这92个batch的数据完全一致吗?是一致更好还是不一致更好?
6.哪些层的输出可能会出现负数,而哪些层的输出可定不会出现负数
7.训练出的结果是否可能出现几乎无泛化能力,即模型预测结果正确率极低?如果有,在不改变数据集和模型的情况下,是在什么情况下训练出来的
8.为什么每层输出均有一个名为None的维度,这个维度在训练和预测时有什么实际意义
9.dropout层并不会改变输入维度(shape size),据此推测dropout层是如何实现的
10.如何计算每一层输出维度与参数(Trainable params)个数
其他
seed
在tensorflow中,很多函数中都会有seed参数,意为"种子"。这里seed实际上代表着随机数的序号。该序号与每个随机数相对应,相当于随机数固定存放在数组中,而seed参数则相当于随机数在数组中的下标索引。如果设置了seed的值,则每次执行程序所产生的随机数或者随机序列均相等,即都为同一个随机数或者随机序列。原因是,每次执行程序都会产生同一个位置处(seed的值)的随机数或者随机序列。如果没有设置seed参数的取值,那么每次执行程序所产生的随机数或者随机序列均不等。
Flatten层
Flatten层用来将输入"压平",即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。 从vgg16网络中可以看出,但是在后来的网络中用GlobalAveragePooling2D代替了flatten层,可以从vgg16与inceptionV3网络对比看出。从参数的对比可以看出,显然这种改进大大的减少了参数的使用量,避免了过拟合现象。
Dense
Dense即全连接层
ReLU
conv2d中padding=same规则介绍
dataset shuffle(洗牌)
train_ds.cache().shuffle(1000)
.shuffle(1000): This method shuffles the elements of the dataset.
The argument 1000 specifies the buffer_size.
The shuffle operation maintains a buffer of buffer_size elements and randomly samples from this buffer.
A larger buffer_size generally leads to better shuffling,
as it allows for a wider range of elements to be chosen from.
However, a very large buffer_size can consume significant memory.
The optimal buffer_size depends on the dataset size and available memory.
sparse/binary_categorical_crossentropy
交叉熵:衡量真实分布和预测分布之间的差异性、凸、梯度不易饱和性(输出值接近0/1时,均方误差的梯度非常小)
1、二元分类
2、多分类
from_logits=True:在model尾端增加一softmax层,
layer_output_shape
学苑网课中心
松鼠学苑发展历程

主营业务

She教研解决方案
1、远端浏览器,从Google、GitHub、Maven等获取技术资源不再有羁绊。
2、基于Devfile的、一键式、无差别构建,基于账号的隔离独享环境,基于浏览器的全新开发模式,让你和你的 小伙伴的软件工程环境精准的一致,而且能随心所欲的创建一个新的属于你的环境。
3、全系列、分步骤镜像,让你的大数据能够从任一成功阶段继续,从裸Linux到Zookeeper、Hadoop、Tez、 Hive、Spark、Oozie、HBase,到Kafka、Flink、Ambari,All in One的Jupyter,最新版本的TensorFlow, 使用你擅长的任一语言,Python、Java、Scala、R、Julia。
4、无需任何配置,只要bind任一端口,你的应用便自动地expose出去,自动配置域名。
She平台架构

She是构建在docker/k8s之上、用于软件开发调试的大数据平台,平 台本身是架构在大数据集群之上的分布式系统,包括三层:计算资源管 理层、She核心调度层、应用层,应用层集合了所有课程环境,Devfile 和Workspace是其中两个核心概念:
1.Devfile是开展某项软件类开发任务所需环境的定义,那么将这个草稿 建设起来的就是Workspace,即Workspace是物理的、而Devfile是逻辑 的、是静态的:Workspace包括了物理上运行的各容器或物理机实体、端 口、命名等一干看得见摸得着的资源,所以Devfile定义了某个实训任务 的资源需求情况,如CPU、GPU、Memory、Disk等,而运行中的Work space的则实际占有了这些资源,因此,从这个意义上看,具体的实训 任务决定了She平台的硬件配置需求。
2.Devfile是She平台的预置环境,即其对应的Workspace中已经安装了 一系列版本号确定的工具,这些工具集的选择是根据这项开发任务的通 用需求而定的,是通用的;但是我们可以根据需要卸载、升级、安装相 应工具。
HFS三节点集群拓扑结构

为了降低实训成本,我们以三节点为例搭建HFS集群,但这个集群理论上可以水平扩展到10万点的规模。