关于课程环境
- 这里的大数据集群的配置和企业生产环境保持一致,如HA(高可用)、核心功能组件、主要服务(daemon);与之相对应的是需要消耗一定量的内存。
- 大数据环境说明如下,其中后面的集群均会包含前面的组件,如Hive集群会包含Hive、Tez、Hadoop、ZooKeeper、SSHEnv:
Centos7C1/C2/C3: 三台裸服务器。
SSHEnvC1/C2/C3: 配置root用户和hadoop用户ssh免密登录。
ZooKeeperC1/C2/C3: 搭建了ZooKeeper集群。
HadoopC1/C2/C3: 搭建了Hadoop集群。
TezC2/C2/C3: 搭建了带Tez的Hadoop集群。
HiveC1/C2/C3: 搭建了Hive集群。
SparkC1/C2/C3: 搭建了Spark集群。
OozieC1/C2/C3: 搭建了Oozie集群。
HBaseC1/C2/C3: 搭建了HBase集群。
KafkaC1/C2/C3: 搭建了Kafka集群。
RedisC1/C2/C3: 搭建了Redis集群。
FlumeSqoopC1/C2/C3: 搭建了Flume/Sqoop集群。
ElasticsearchC1/C2/C3: 搭建了Elasticsearch集群。
FlinkC1/C2/C3: 搭建了Flink集群。
HudiC1/C2/C3: 搭建了Hudi集群。
SolrC1/C2/C3: 搭建了Solr集群。
AtlasC1/C2/C3: 搭建了Atlas集群。
BigDataWithLoadedDataC1/C2/C3: 集成了除Solr/Atlas组件之外的集群、并加载了相应的数据集,具体数据集参考应用案例。
-
同一个角色(C1、C2、C3)的服务器只能创建一个,如HadoopC1和ZooKeeperC1不能同时创建成功,但HadoopC1和ZooKeeperC2能同时创建成功、尽管这么做没有意义。
-
数据可视化环境参考"数据可视化分析"章节说明。
She平台高校版学生端网络设置
学生通过PC个人电脑的Chrome浏览器登录She平台高校版、具体网址由授课老师发布(但肯定不同于She平台C端版地址:http://she.kinginsai.com)。
She平台高校版通常部署在相应学校的机房环境中,学生PC个人电脑需要同时具备访问外网和访问学校机房环境的网络接入条件。
She平台高校版的资源
-
本课程的字母名称为"BigData",其中(http)文件服务器上的根目录名称"BigData"、gitlab服务器的仓库名称为"BigData"、松鼠学苑GitHub仓库的名称为"Spark-stack"。
-
She平台C端版(http://she.kinginsai.com)的服务端有外网权限,所以松鼠学苑的标准课程均从资源的源端下载、如https://archive.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz;但通常She平台高校版的服务端没有外网权限(这个很容测试、如ping www.baidu.com),因此需要通过(http)文件服务器/gitlab服务器下载、或者从学生本地计算机上传的方式解决。
-
文件资源放在(http)文件服务器上,可以阅读She平台手册的"She平台课程环境详细操作说明"部分,这样在学生可使用wget命令下载到实训环境中,因为文件服务器和She平台是部署在同一内网中;如果对应高校版本中没有部署(http)文件服务器、或者(http)文件服务器中没有相应资源,可以在学生个人电脑端从互联网下载相应资源到本地,然后上传到实训环境中,具体方法参考She平台手册的"ssh远程连接远端服务器工具"部分。
-
配置文件、代码等教学资源放在gitlab服务器上,可以阅读She平台手册的"She平台课程环境详细操作说明"部分,这样在学生可使用git clone命令下载到实训环境中,因为gitlab服务器和She平台是部署在同一内网中;如果对应高校版本中没有部署gitlab服务器、或者gitlab服务器中没有相应资源,可以在学生个人电脑端从松鼠学苑的github仓库(https://github.com/haiye1018/)下载相应资源到本地,压缩后上传到实训环境中,具体方法参考She平台手册的"ssh远程连接远端服务器工具"部分。
什么是大数据
1、是基础设施。
2、是方法论。
课程体系


详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

关于课程环境
- 这里的大数据集群的配置和企业生产环境保持一致,如HA(高可用)、核心功能组件、主要服务(daemon);与之相对应的是需要消耗一定量的内存。
- 大数据环境说明如下,其中后面的集群均会包含前面的组件,如Hive集群会包含Hive、Tez、Hadoop、ZooKeeper、SSHEnv:
Centos7C1/C2/C3: 三台裸服务器。
SSHEnvC1/C2/C3: 配置root用户和hadoop用户ssh免密登录。
ZooKeeperC1/C2/C3: 搭建了ZooKeeper集群。
HadoopC1/C2/C3: 搭建了Hadoop集群。
TezC2/C2/C3: 搭建了带Tez的Hadoop集群。
HiveC1/C2/C3: 搭建了Hive集群。
SparkC1/C2/C3: 搭建了Spark集群。
OozieC1/C2/C3: 搭建了Oozie集群。
HBaseC1/C2/C3: 搭建了HBase集群。
KafkaC1/C2/C3: 搭建了Kafka集群。
RedisC1/C2/C3: 搭建了Redis集群。
FlumeSqoopC1/C2/C3: 搭建了Flume/Sqoop集群。
ElasticsearchC1/C2/C3: 搭建了Elasticsearch集群。
FlinkC1/C2/C3: 搭建了Flink集群。
HudiC1/C2/C3: 搭建了Hudi集群。
SolrC1/C2/C3: 搭建了Solr集群。
AtlasC1/C2/C3: 搭建了Atlas集群。
BigDataWithLoadedDataC1/C2/C3: 集成了除Solr/Atlas组件之外的集群、并加载了相应的数据集,具体数据集参考应用案例。
-
同一个角色(C1、C2、C3)的服务器只能创建一个,如HadoopC1和ZooKeeperC1不能同时创建成功,但HadoopC1和ZooKeeperC2能同时创建成功、尽管这么做没有意义。
-
数据可视化环境参考"数据可视化分析"章节说明。
She平台高校版学生端网络设置
学生通过PC个人电脑的Chrome浏览器登录She平台高校版、具体网址由授课老师发布(但肯定不同于She平台C端版地址:http://she.kinginsai.com)。
She平台高校版通常部署在相应学校的机房环境中,学生PC个人电脑需要同时具备访问外网和访问学校机房环境的网络接入条件。
She平台高校版的资源
-
本课程的字母名称为"BigData",其中(http)文件服务器上的根目录名称"BigData"、gitlab服务器的仓库名称为"BigData"、松鼠学苑GitHub仓库的名称为"Spark-stack"。
-
She平台C端版(http://she.kinginsai.com)的服务端有外网权限,所以松鼠学苑的标准课程均从资源的源端下载、如https://archive.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz;但通常She平台高校版的服务端没有外网权限(这个很容测试、如ping www.baidu.com),因此需要通过(http)文件服务器/gitlab服务器下载、或者从学生本地计算机上传的方式解决。
-
文件资源放在(http)文件服务器上,可以阅读She平台手册的"She平台课程环境详细操作说明"部分,这样在学生可使用wget命令下载到实训环境中,因为文件服务器和She平台是部署在同一内网中;如果对应高校版本中没有部署(http)文件服务器、或者(http)文件服务器中没有相应资源,可以在学生个人电脑端从互联网下载相应资源到本地,然后上传到实训环境中,具体方法参考She平台手册的"ssh远程连接远端服务器工具"部分。
-
配置文件、代码等教学资源放在gitlab服务器上,可以阅读She平台手册的"She平台课程环境详细操作说明"部分,这样在学生可使用git clone命令下载到实训环境中,因为gitlab服务器和She平台是部署在同一内网中;如果对应高校版本中没有部署gitlab服务器、或者gitlab服务器中没有相应资源,可以在学生个人电脑端从松鼠学苑的github仓库(https://github.com/haiye1018/)下载相应资源到本地,压缩后上传到实训环境中,具体方法参考She平台手册的"ssh远程连接远端服务器工具"部分。
什么是大数据
1、是基础设施。
2、是方法论。
课程体系
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
关于课程环境
- 这里的大数据集群的配置和企业生产环境保持一致,如HA(高可用)、核心功能组件、主要服务(daemon);与之相对应的是需要消耗一定量的内存。
- 大数据环境说明如下,其中后面的集群均会包含前面的组件,如Hive集群会包含Hive、Tez、Hadoop、ZooKeeper、SSHEnv:
Centos7C1/C2/C3: 三台裸服务器。
SSHEnvC1/C2/C3: 配置root用户和hadoop用户ssh免密登录。
ZooKeeperC1/C2/C3: 搭建了ZooKeeper集群。
HadoopC1/C2/C3: 搭建了Hadoop集群。
TezC2/C2/C3: 搭建了带Tez的Hadoop集群。
HiveC1/C2/C3: 搭建了Hive集群。
SparkC1/C2/C3: 搭建了Spark集群。
OozieC1/C2/C3: 搭建了Oozie集群。
HBaseC1/C2/C3: 搭建了HBase集群。
KafkaC1/C2/C3: 搭建了Kafka集群。
RedisC1/C2/C3: 搭建了Redis集群。
FlumeSqoopC1/C2/C3: 搭建了Flume/Sqoop集群。
ElasticsearchC1/C2/C3: 搭建了Elasticsearch集群。
FlinkC1/C2/C3: 搭建了Flink集群。
HudiC1/C2/C3: 搭建了Hudi集群。
SolrC1/C2/C3: 搭建了Solr集群。
AtlasC1/C2/C3: 搭建了Atlas集群。
BigDataWithLoadedDataC1/C2/C3: 集成了除Solr/Atlas组件之外的集群、并加载了相应的数据集,具体数据集参考应用案例。
-
同一个角色(C1、C2、C3)的服务器只能创建一个,如HadoopC1和ZooKeeperC1不能同时创建成功,但HadoopC1和ZooKeeperC2能同时创建成功、尽管这么做没有意义。
-
数据可视化环境参考"数据可视化分析"章节说明。
She平台高校版学生端网络设置
学生通过PC个人电脑的Chrome浏览器登录She平台高校版、具体网址由授课老师发布(但肯定不同于She平台C端版地址:http://she.kinginsai.com)。
She平台高校版通常部署在相应学校的机房环境中,学生PC个人电脑需要同时具备访问外网和访问学校机房环境的网络接入条件。
She平台高校版的资源
-
本课程的字母名称为"BigData",其中(http)文件服务器上的根目录名称"BigData"、gitlab服务器的仓库名称为"BigData"、松鼠学苑GitHub仓库的名称为"Spark-stack"。
-
She平台C端版(http://she.kinginsai.com)的服务端有外网权限,所以松鼠学苑的标准课程均从资源的源端下载、如https://archive.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz;但通常She平台高校版的服务端没有外网权限(这个很容测试、如ping www.baidu.com),因此需要通过(http)文件服务器/gitlab服务器下载、或者从学生本地计算机上传的方式解决。
-
文件资源放在(http)文件服务器上,可以阅读She平台手册的"She平台课程环境详细操作说明"部分,这样在学生可使用wget命令下载到实训环境中,因为文件服务器和She平台是部署在同一内网中;如果对应高校版本中没有部署(http)文件服务器、或者(http)文件服务器中没有相应资源,可以在学生个人电脑端从互联网下载相应资源到本地,然后上传到实训环境中,具体方法参考She平台手册的"ssh远程连接远端服务器工具"部分。
-
配置文件、代码等教学资源放在gitlab服务器上,可以阅读She平台手册的"She平台课程环境详细操作说明"部分,这样在学生可使用git clone命令下载到实训环境中,因为gitlab服务器和She平台是部署在同一内网中;如果对应高校版本中没有部署gitlab服务器、或者gitlab服务器中没有相应资源,可以在学生个人电脑端从松鼠学苑的github仓库(https://github.com/haiye1018/)下载相应资源到本地,压缩后上传到实训环境中,具体方法参考She平台手册的"ssh远程连接远端服务器工具"部分。
什么是大数据
1、是基础设施。
2、是方法论。
课程体系
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
创建并初始化环境
以下步骤是其它章节必须的步骤,只需要做一次即可,不能多次初始化。
1、创建参考对应章节。
"HadoopC1/C2/C3: 搭建了Hadoop集群"是可以做Hadoop应用的集群,而想搭建Hadoop集群则需要创建"ZooKeeperC1/C2/C3: 搭建了ZooKeeper集群"、并在此基础上开展搭建工作;当完全掌握搭建之后想学习Hadoop应用层面的知识,可直接创建"HadoopC1/C2/C3: 搭建了Hadoop集群"并在此集群上完成后续的实验操作。
其他阶段的集群遵循上述原理。
2、New terminal.

3、切换到root用户。 命令:
sudo /bin/bash
为什么使用上面的命令而不是用'su - root'呢?因为'sudo /bin/bash'不需要输入密码,而'su - root'需要;但它们的效果是等价的。

4、进入hadoop目录。 命令:
cd /hadoop/

5、运行initHost.sh脚本,配置本机ip和名称(app-11)对应关系。 命令:
./initHosts.sh

6、切换到hadoop用户下,进入hadoop根目录。 命令:
su - hadoop
cd /hadoop/

7、启动环境。 命令:
./startAll.sh


保证当前shell的用户为hadoop(如果当前用户已经是hadoop,此步可忽略)
1、切换到root用户。 命令:
sudo /bin/bash
为什么使用上面的命令而不是用'su - root'呢?因为'sudo /bin/bash'不需要输入密码,而'su - root'需要;但它们的效果是等价的。
2、切换到hadoop用户下。 命令:
su - hadoop
什么是分布式协同
以电商平台为例,在电商平台初期是单应用架构,所谓但应用架构是将应用部分和数据部分放在同一台服务器上,对外提供服务。 但是随着业务的发展 我们的并发量成爆炸式的发展,为了应对这种爆发式的增长,需要将应用和数据进行拆分,应用拆分就是将应用部分拆分成多个子系统,并且每一个子系统,每一个功能部署多个服务,那么,如何协调多个相同功能,这就是协同工作的出发点。数据库拆分提高读取的效率。
为什么选择zookeeper
zookeeper的应用性能和性能非常的好,ZooKeeper的设计保证了其健壮性,这就使得应用开发人员可以更多关注应用本身的逻辑,而不是协同工作上。ZooKeeper从文件系统API得到启发,提供一组简单的API,使得开发人员可以实现通用的协作任务,包括选举主节点、管理组内成员关系、管理元数据等。ZooKeeper包括一个应用开发库(主要提供Java和C两种语言的API)和一个用Java实现的服务组件。ZooKeeper的服务组件运行在一组专用服务器之上,保证了高容错性和可扩展性。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

什么是分布式协同
以电商平台为例,在电商平台初期是单应用架构,所谓但应用架构是将应用部分和数据部分放在同一台服务器上,对外提供服务。 但是随着业务的发展 我们的并发量成爆炸式的发展,为了应对这种爆发式的增长,需要将应用和数据进行拆分,应用拆分就是将应用部分拆分成多个子系统,并且每一个子系统,每一个功能部署多个服务,那么,如何协调多个相同功能,这就是协同工作的出发点。数据库拆分提高读取的效率。
为什么选择zookeeper
zookeeper的应用性能和性能非常的好,ZooKeeper的设计保证了其健壮性,这就使得应用开发人员可以更多关注应用本身的逻辑,而不是协同工作上。ZooKeeper从文件系统API得到启发,提供一组简单的API,使得开发人员可以实现通用的协作任务,包括选举主节点、管理组内成员关系、管理元数据等。ZooKeeper包括一个应用开发库(主要提供Java和C两种语言的API)和一个用Java实现的服务组件。ZooKeeper的服务组件运行在一组专用服务器之上,保证了高容错性和可扩展性。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
准备工作
1、第一步分别建立SSHEnvC1、2、3

正常运行
 2、在SSHEvnC1中操作,New terminal
2、在SSHEvnC1中操作,New terminal

3、切换到root用户。
命令:sudo /bin/bash

4、进入hadoop目录下并查看有哪些文件夹。
命令:cd /hadoop/

5、运行initHost.sh脚本,进行三台机器的认证:./initHosts.sh 。
命令:./initHosts.sh

运行效果:

安装zookeeper安装包
1、 在app11中操作,切换到hadoop用户,密码Yhf_1018
命令:su – hadoop注:输入的密码是不显示出来的。

2、 进入hadoop根目录,并查看目录下的文件。
命令:cd /hadoop/

3、创建一个ZooKeeper安装的根目录。
命令:mkdir ZooKeeper
4、 进入到ZooKeeper目录下。
命令:cd ZooKeeper/

5、上传安装包我们这里用的版本是zookeeper-3.4.10,通过wget命令在网上直接上传,wget+网址。
命令:wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz

6、 安装包解压,会出现一个zookeeper-3.4.10 的文件夹。
命令:tar -xf zookeeper-3.4.10.tar.gz

7、进入zookeeper-3.4.10文件夹,文件中有一个conf文件。
命令:cd zookeeper-3.4.10

8、 进入conf文件夹,文件中有一个zoo_sample.cfg文件,将zoo_sample.cfg文件改名为zoo.cfg。
命令:mv zoo_sample.cfg zoo.cfg注:文件名之间要有空格。

9、 查看zoo.cfg内容。
命令:vi zoo.cfg
 运行效果:
运行效果:

10、将原文件的dataDir改为/hadoop/ZooKeeper/zookeeper-3.4.10/data,注:按i进行内容更改,先按ESC再输入:wq进行文件保存并退出。


11、设置集群的server,再刚才的zoo.cfg文件中继续操作,再文件的最后内容中加入
server.1=app-11:2888:3888
server.2=app-12:2888:3888
server.3=app-13:2888:3888
并保存退出。

12、进入上一层目录,目录为zookeeper-3.4.10,该目录下不存在data目录,需要创建data目录和myid文件,myid对应的id为conf的id,打开myid文件。
命令:mkdir data、touch data/myid、vi data/myid
 运行效果:
运行效果:

13、输入1,这是myid的内容,并保存退出。

14、返回根目录。
命令:cd ..

设置环境变量
1、命令:vi ~/.bashrc

运行效果:

2、设置ZOOKEEPER_HOME目录和PATH目录,在环境变量中加入
export ZOOKEEPER_HOME=/hadoop/ZooKeeper/zookeeper-3.4.10
export PATH=${ZOOKEEPER_HOME}/bin:$PATH
保存并退出。

3、当前的PATH中并没有ZOOKEEPER目录,需要使用source命令让刚刚的修改过的PATH执行。
命令:echo $PATH、source ~/.bashrc

其他集群设置
1、 首先免密登录到app-12上,进入hadoop目录下创建ZooKeeper文件。
命令:ssh hadoop@app-12 "cd /hadoop && mkdir ZooKeeper"

2、所有的集群目录都是一样,需要将整个zookeeper安装包拷贝到其他集群的机器上。
命令:scp -r zookeeper-3.4.10 hadoop@app-12:/hadoop/ZooKeeper注:-r是表示拷贝整个目录。
 运行效果:
运行效果:

3、需要将app-12的myid改为2。
登录app-12。
命令:ssh hadoop@app-12

4、进入ZooKeeper目录下,有zookeeper-3.4.10证明刚才的拷贝完成。
命令:cd /hadoop/ZooKeeper/

5、 进入到zookeeper-3.4.10/data目录下,打开myid文件。
命令:cd zookeeper-3.4.10/、cd data/、vi myid
 运行效果:
运行效果:

6、 将1改为2,并保存退出。

7、退出app-12。
命令:exit
 8、将环境变量拷贝到app-12上,进行覆盖拷贝。
命令:
8、将环境变量拷贝到app-12上,进行覆盖拷贝。
命令:scp ~/.bashrc hadoop@app-12:~/

app-12完成。同理,在app-13上执行。
9、在app-13上创建目录,并拷贝文件,这里使用的是静默拷贝。
命令:ssh hadoop@app-13 "cd /hadoop && mkdir ZooKeeper"
scp -r -p zookeeper-3.4.10
hadoop@app-13:/hadoop/ZooKeeper/

10、拷贝环境变量。
命令:scp ~/.bashrc hadoop@app-13:~/

11、登录到app-13上修改myid文件。
命令:ssh hadoop@app-13
vi /hadoop/ZooKeeper/zookeeper-3.4.10/data/myid
 运行效果:
运行效果:

12、将1修改为3,并保存退出。

13、退出app-13。

检验是否成功
分别登录app-11、app-12、app-13,执行命令:zkServer.sh start,成功运行出效果图,证明成功。

常见问题
 问题:zkServer.sh start无法正常运行。
解决办法:检查zookeeper的环境变量是否正确。
问题:zkServer.sh start无法正常运行。
解决办法:检查zookeeper的环境变量是否正确。
 含义是:免密登录APP-13并在app-13用户中进行zkServer.sh status操作。
hadoop@app-13和“zkServer.sh status”之间一定要有空格。
含义是:免密登录APP-13并在app-13用户中进行zkServer.sh status操作。
hadoop@app-13和“zkServer.sh status”之间一定要有空格。
 问题:可能网络不稳定,缺少某个插件。
解决办法:重新刷新。
问题:可能网络不稳定,缺少某个插件。
解决办法:重新刷新。
 问题:运行失败。
解决办法:重新刷新运行。
问题:运行失败。
解决办法:重新刷新运行。
 问题:该错误为当前用户没有权限对文件作修改。
解决办法:按ESC在输入:q!退出即可。
问题:该错误为当前用户没有权限对文件作修改。
解决办法:按ESC在输入:q!退出即可。
 问题:在执行zkServer.sh start时出现的弹框。
解决办法:直接点x就可以。
问题:在执行zkServer.sh start时出现的弹框。
解决办法:直接点x就可以。
 问题:网络出现波动。
解决办法:多几次刷新页面,重新进入Workspace或者重新登录she平台。
问题:网络出现波动。
解决办法:多几次刷新页面,重新进入Workspace或者重新登录she平台。
友情提示:详细学习内容可观看Spark快速大数据处理——余海峰https://edu.csdn.net/course/detail/24205
zookeeper客户端基本操作
1、首先切换到hadoop用户下。
命令:su - hadoop

2、确保zookeeper集群的正常启动的。
命令:zkServer.sh status
 这里的app-11是follower.
这里的app-11是follower.
3、分别查看app-12、app-13谁是lead.
命令:ssh hadoop@app-12 "zkServer.sh status"、ssh hadoop@app-13 "zkServer.sh status"

4、运行客户端。
命令:zkCli.sh

5、看下客户端有什么命令。
命令:help

6、查看根目录下有什么。
命令:ls /

7、创建一个test并在test目录下存放数据zk。
命令:create /test "zk"

8、在查看根目录下。
命令:ls /

9、取出test中的数据。
命令:get /test

10、删除test目录.。
命令:delete /test

11、创建临时节点。
命令:create -e /test "lock"

12、模拟异常退出,按Ctrl+C,等待30秒。

13、重新登录到客户端。
命令:zkCli.sh

14、查看根目录。
命令:ls /

临时节点消失。
友情提示:详细学习内容可观看Spark快速大数据处理——余海峰https://edu.csdn.net/course/detail/24205
zookeeper分布式锁是干什么的
zookeeper实现分布式锁的原理就是多个节点同时在一个指定的节点下面创建临时会话顺序节点,谁创建的节点序号最小,谁就获得了锁,并且其他节点就会监听序号比自己小的节点,一旦序号比自己小的节点被删除了,其他节点就会得到相应的事件,然后查看自己是否为序号最小的节点,如果是,则获取锁。
为什么使用zookeeper分布式锁?
使用分布式锁的目的,无外乎就是保证同一时间只有一个客户端可以对共享资源进行操作。 但是Martin指出,根据锁的用途还可以细分为以下两类: (1)允许多个客户端操作共享资源 这种情况下,对共享资源的操作一定是幂等性操作,无论你操作多少次都不会出现不同结果。在这里使用锁,无外乎就是为了避免重复操作共享资源从而提高效率。 (2)只允许一个客户端操作共享资源 这种情况下,对共享资源的操作一般是非幂等性操作。在这种情况下,如果出现多个客户端操作共享资源,就可能意味着数据不一致,数据丢失。
分布式锁操作
1、 在app-11上创建一个临时节点并存入数据lock。
命令:create -e /test "lock"

2、在app-12上登录到hadoop用户下,并切换到客户端。
命令:su – hadoop、zkCli.sh

3、 创建一个和app-11一样的临时节点,路径也相同。
命令:create -e /test "lock"
 这里说明创建失败。
这里说明创建失败。
4、 在app-12上创建一个通知,监视test。
命令:stat /test true

5、 在app-11上删除test节点。
命令:delete /test

6、返回app-12。

7、 此处的监视是一次性,还想监视,需要在输入一次命令。
命令:stat /test true
 这里显示说明,这个test不存在。
这里显示说明,这个test不存在。
8、在app-11上再创建一次test。
命令:create -e /test "lock"

9、返回app-12上。

友情提示:详细学习内容可观看Spark快速大数据处理——余海峰https://edu.csdn.net/course/detail/24205
ZooKeeper主从应用
原理
1、zookeeper能做什么? 它可以在分布式系统中协作多个任务,一个协作任务是指一个包含多个进程的任务
2、真实系统中的三个问题 1.消息延迟 2.处理器性能 3.时钟偏移
3、主从模式的三个问题 1.主节点崩溃 :如果主节点发送错误并失效,系统将无法分配新的任务或重新分配已失败的任务。2.从节点崩溃:如果从节点崩溃,已分配的任务将无法完成。 3.通信故障:如果主节点和从节点之间无法进行信息交换,从节点将无法得知新任务分配给它。
4、主-从架构的需求 主节点选举:这是关键的一步,使得主节点可以给从节点分配任务 崩溃检测:主节点必须具有检测从节点崩溃或失去连接的能力。 组成员关系管理:主节点必须具有知道哪一个从节点可以执行任务的能力。 元数据管理:主节点和从节点必须具有通过某种可靠的方式来保存分配状态和执行状态的能力。
5、 监视与通知

操作
app-11为主节点,app-12为从节点、app-13为客户端。
1、 分别用app-11、app-12、app-13登录到客户端。
命令:su – hadoop、zkCli.sh

2、 在主节点上创建一个临时节点并存入数据app-11。
命令:create -e /master "app-11"

3、分别创建临时节点workers、tasks、assign。
命令:create /workers ""、create /tasks ""、create /assign ""

4、使用ls多项监控。
命令:ls /workers true、ls /tasks true

5、在从节点上向workers注册一个节点,并存入自己的节点信息。
命令:creat -e workers/worker1 "app-12"

6、 返回到app-11上。

7、 在客户端上,创建有序的任务。
命令:create -s /tasks/task- "cmd"

8、 返回主节点。

9、在主节点上创建任务节点worker1。
命令:create /assign/worker1 ""

10、在从节点上监控任务节点,因为任务节点还没有创建,所以用stat命令。
命令:stat /assign/worker1/task-0000000000 true

11、在主节点上创建任务节点。
命令:create /assign/worker1/task-0000000000 ""

12、返回从节点.

13、同理在主节点上监控任务完成的状况。
命令:stat /assign/worker1/task-0000000000/status true

14、在从节点上创建任务完成状态,假设ok。
命令:create /assign/worker1/task-0000000000/status "OK"

15、返回主节点。

ZooKeeper清理工作
1、 登录hadoop用户。
命令:su – Hadoop

2、 登录到客户端。
命令:zkCli.sh

3、 删除其他节点,先查看有哪些节点。
命令:ls /

4、删除其他多余节点,只留zookeeper节点。
命令:rmr /workers、rmr /test、rmr /tasks、rmr /master、rmr /assign

5、 退出。
命令:quit

常见问题
 问题原因:临时节点下不能创建子节点
解决办法:检查workers是否为临时节点,删除workers重新创建。
问题原因:临时节点下不能创建子节点
解决办法:检查workers是否为临时节点,删除workers重新创建。
友情提示:详细学习内容可观看Spark快速大数据处理——余海峰https://edu.csdn.net/course/detail/24205
为什么引入大数据
hadoop概述
基本集群环境搭建
学习hadoop3首先不是学习hadoop的概念,因为hadoop是比较复杂的模块,是大数据基础的环境,我们把整个环境搭建好了之后,可以边操作边理解hadoop的功能,比如说MapReduce、YARN、HDFS。而且在基本环境之上,再进行改造,加入每一节课讲解的新内容。这样可以更早的接触到Hadoop集群,能够快速的理解。

逻辑的集群,包括了两个NN、两个RM、三个JN节点、三个DN节点,对应的物理部署形式是包括了app-11、app-12和app-13。在app-11上部署了NN1和RM1,在app-12上部署了NN2和RM2,三个DN和三个JN分别部署在app-11、app-12和app-13,因为整个系统只有三个机器,其中app-11和app-12分别分配了4G内存,app-13只有2g内存,所以app-13的任务会稍微减轻一点。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

为什么引入大数据
hadoop概述
基本集群环境搭建
学习hadoop3首先不是学习hadoop的概念,因为hadoop是比较复杂的模块,是大数据基础的环境,我们把整个环境搭建好了之后,可以边操作边理解hadoop的功能,比如说MapReduce、YARN、HDFS。而且在基本环境之上,再进行改造,加入每一节课讲解的新内容。这样可以更早的接触到Hadoop集群,能够快速的理解。
逻辑的集群,包括了两个NN、两个RM、三个JN节点、三个DN节点,对应的物理部署形式是包括了app-11、app-12和app-13。在app-11上部署了NN1和RM1,在app-12上部署了NN2和RM2,三个DN和三个JN分别部署在app-11、app-12和app-13,因为整个系统只有三个机器,其中app-11和app-12分别分配了4G内存,app-13只有2g内存,所以app-13的任务会稍微减轻一点。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
Hadoop高可用集群搭建过程视频
Hadoop高可用集群搭建验证视频
前期准备工作
1、第一步分别建立ZookeeperC1、2、3。

2、在app11中操作,New terminal.

注意:下面的命令当中可能有格式错误,需要同学根据对步骤的理解修正。
3、切换到root用户。
命令:sudo /bin/bash

4、进入hadoop目录下并查看有哪些文件夹。
命令:cd /hadoop/ 、ls

5、运行initHost.sh脚本,进行三台机器的认证。
命令:./initHosts.sh 。

运行效果:

6、切换到hadoop用户下,进入hadoop根目录。
命令:su - hadoop、cd /hadoop/

7、启动zookeeper集群。
命令:./startAll.sh

以上步骤是启动任一阶段集群的全部过程,如启动hadoop阶段的集群、Spark阶段的集群。
hadoop环境搭建
安装hadoop安装包
1、在app-11上,切换到hadoop用户。
命令:su - hadoop
注:输入的密码是不显示出来的。

2、进入hadoop根目录,并查看目录下的文件。
命令:cd /hadoop/

3、创建一个安装Hadoop的根目录。
命令:mkdir Hadoop

4、进入到Hadoop目录下。
命令:cd Hadoop/

5、下载hadoop安装包。
命令:wget https://archive.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz

6、解压安装包。
命令:tar -xf hadoop-3.1.2.tar.gz

7、进入到/tmp目录下。
命令:cd /tmp/

8、通过GitHub下载Spark-stack。
命令:git clone https://github.com/haiye1018/Spark-stack

9、进入Spark-stack/目录下。
命令:cd Spark-stack/

10、 进入Hadoop目录下。
命令:cd Hadoop/

11、 将conf拷贝到hadoop-3.1.2/etc/hadoop目录下,并查看是否成功。
命令:cp conf/* /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/、cat /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/workers

12、在环境变量中加入hadoop和HADOOP_HOME路径。
命令:vi ~/.bashrc、
export HADOOP_HOME=/hadoop/Hadoop/hadoop-3.1.2
exporPATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${HADOOP_HOME}/lib:$PATH

13、将设置的环境变量生效。
命令:source ~/.bashrc、echo $PATH

将hadoop安装包拷贝集群中的另两台机器上
14、先创建安装的根目录。
命令:ssh hadoop@app-12 "mkdir /hadoop/Hadoop"、sshhadoop@app-13 "mkdir /hadoop/Hadoop"

15、将环境变量拷贝到集群的另外两个机器上。
命令:scp ~/.bashrc hadoop@app-12:~/、scp ~/.bashrchadoop@app-13:~/

16、 将改好的安装包拷贝到集群的另外两个机器上。
命令:cd /hadoop/Hadoop、scp -r -q hadoop-3.1.2 hadoop@app-12:/hadoop/Hadoop、scp -r -q hadoop-3.1.2 hadoop@app-13:/hadoop/Hadoop

hadoop初始化工作
17、 需要将所有的journalnode守护进程启动,接下来是用一个循环脚本启动。
命令:for name in app-11 app-12 app-13; do ssh hadoop@$name"hdfs --daemon start journalnode"; done

18、 查看journalnode是否启动。
命令:for name in app-11 app-12app-13; do ssh hadoop@$name "jps"; done注:显示的是三个journalnode守护进程,三个zookeeper守护进程。

19、 在app-11namenode上各式化。
命令:hdfs namenode -format注:会打印很多classpath

20、 因为是两台namenode做ha,需要在另一台机器上拷贝格式化信息,先关闭所有守护进程。
命令:for name in app-11 app-12 app-13; do ssh hadoop@$name "hdfs--daemon stop journalnode"; done

创建ha节点
21、创建ha主从应用里zookeeper目录树的目录,先登录到客户端查看ha存不存在。
命令:zkCli.sh

22、 查看客户端下有什么。
命令:ls /

23、 只有一个zookeeper节点,ha节点并不存在,退出。
命令:quit
 24、 zookeeper初始化工作。
命令:
24、 zookeeper初始化工作。
命令:hdfs zkfc -formatZK -force注:打印很多的classpath

25、 再次登录到客户端,查看ha节点存不存在。
命令:zkCli.sh

26、 查看根目录下有什么。
命令:ls /注:这时候有一个hadoop-ha节点

27、 查看hadoop-ha节点下。
命令:ls /hadoop-ha

28、 查看dmcluster节点下,dmcluster节点下是空的,dmcluster是ha下的集群。
命令:ls /hadoop-ha/dmcluster

29、 证明ha节点存在之后,退出。
命令:quit

将app-11namenode的初始化信息同步到app-12上
30、 先启动dfs整个的系统。
命令:start-dfs.sh

31、 免密登录到app-12上执行。
命令:ssh hadoop@app-12 "hdfsnamenode -bootstrapStandby"注:打印很多classpath

启动整个集群检查hdfs和yarn是否成功
32、 关闭整个dfs系统,因为后续需要通过其他途径启动整个集群。
命令:stop-dfs.sh

33、启动整个集群,时间会比较久。
命令:start-all.sh

34、检查hdfs和yarn到底是否成功,现将命令打出来。
命令:hdfs haadmin

35、使用-getAllServiceState这个命令。
命令:hdfs haadmin -getAllServiceState

36、打印yarn的命令行。
命令:yarn rmadmin

37、使用-getAllServiceState这个命令。
命令:yarn rmadmin -getAllServiceState

38、验证整个集群,先看一下hdfs上有什么。命令:hdfs dfs -ls /注:hdfs为空

测试hadoop集群是否正常启动
1、为测试方便,创建一个目录。
命令:hdfsdfs -mkdir -p /test/data

2、将所有需要mapreduce数据放在data目录下,将配置文件以xml结尾的上传到data目录里。
命令:hdfs dfs -put /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/*.xml/test/data

3、查看是否上传成功。
命令:hdfsdfs -ls /test/data

4、提交一个mapreduce任务,用hadoop自带的例子。
命令:hadoop jar/hadoop/Hadoop/hadoop-3.1.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jargrep /test/data /test/output "dfs[a-z.]+"
注:使用的是grep参数,输入是test/data输出是test/output,这里的output一定不能存在,存在的话用rm命令删除掉。查询以dfs开头的,以小写字母以及.紧接着相邻的很多+字符的字符串。这个命令执行的时候分两步,第一步是查询,查到做正则表达的那一行,然后做排序。


5、整个mapreduce案例已经执行完了,看结果输出什么东西。
命令:hdfs dfs -ls /test/output
注:输出了两个文件,结果在part-r-00000中

6、查看part-r-00000文件中的内容。命令:hdfs dfs -cat /test/output/part-r-00000
 注:数字代表出现的次数,字符串是匹配的字符串。
注:数字代表出现的次数,字符串是匹配的字符串。
7、登录管理界面,查看已经执行完的任务。首先点击右侧chrome-browser。

8、再点击vnc_lite.html.

9、单击右键,选择Chrome.


10、输入网址,app-11:8088,会自动跳转到app-12:8088。

常见问题
 问题:app-12和app-13的环境变量有问题。解决办法:检查环境变量,如有异常请使用source命令,运行环境变量或者删除workerspace后从头开始创建。
问题:app-12和app-13的环境变量有问题。解决办法:检查环境变量,如有异常请使用source命令,运行环境变量或者删除workerspace后从头开始创建。
友情提示:详细学习内容可观看Spark快速大数据处理——余海峰https://edu.csdn.net/course/detail/24205
HDFS基本操作
1、运行HDFS看有什么东西。
命令:hdfs
注:主要打印出三类命令,管理命令、客户端命令、管理守护进程命令。

2、命令:hdfs version
注:打印了Hadoop信息、源码信息、编译信息等。

3、命令:hdfs classpath
注:打印classpath

4、命令:hdfs getconf
注:打印getconf下的命令

5、打印namenode。
命令:hdfs getconf -namenodes
注:当前app-12为active.所以将app-12放前面。

6、命令:hdfs getconf -secondaryNameNodes
注:因为我们没有设置secondaryNameNodes,所以现在没有。

7、命令:hdfs getconf -journalNodes

8、命令:hdfs getconf -includeFile

9、命令:hdfs dfs
注:对Linux系统文件的操作。

HDFS文件操作
10、在根目录下创建一个文件。
命令:hdfs dfs -mkdir /test2

11、将test/output/part-r-00000文件拷贝到test2下。
命令:hdfs dfs -cp /test/output/part-r-00000 /test2

12、查看是否拷贝成功。
命令:hdfs dfs -ls /test2

13、先查看本地目录和文件。
命令:pwd、ls

14、下载到本地目录下。
命令:hdfs dfs -get /test2/part-r-00000 ./、 ls

15、可以使用Linux命令查看改文件。
命令:vi part-r-00000


友情提示:详细学习内容可观看Spark快速大数据处理——余海峰https://edu.csdn.net/course/detail/24205
今天我学习创建federation环境,viewFS操作,在清理掉这些环境,还原到最初的系统。
创建Federation环境
1、在app-11上,切换到hadoop用户下。
命令:su – hadoop

2、切到hadoop的安装目录下。
命令:cd /hadoop/Hadoop/

3、进入hadoop3.1的配置目录下。
命令:cd hadoop-3.1.2/etc/hadoop/

4、删除hdfs-site.xml文件。
命令:rm -rf hdfs-site.xml

5、进入/tmp/Spark-stack目录下。
命令:cd /tmp/Spark-stack/

6、将hdfs-site.xml拷贝到/hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/目录下。
命令:cp hdfs-site.xml /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/
注:这里的hdfs-site.xml我们增加了dm2,因为在app-11和app-12上做了ha,dm2只能放在app-13上。


7、将该文件继续拷贝到集群的另外两个机器上。
命令:scp hdfs-site.xml hadoop@app-12:/hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/、scp hdfs-site.xml hadoop@app-13:/hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/

8、登录到app-13上。
命令:ssh hadoop@app-13

9、切换到配置文件所在的目录下。
命令:cd /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/

对namenode各式化。
10、先打开hdfs-site.xml文件。
命令:vi hdfs-site.xml

11、添加注释。将dm2的cluster的namenode限制在app-13上,而不采用ha

12、初始化各式。
命令:hdfs namenode -format -clusterId dm2注:会打印很多classpath

13、启动namenode.
命令:hdfs --daemon start namenode注:只是启动本地的namenode。

14、查看是否开启。
命令:jps

15、将app-13上的datanode和其他机器上的namenode建立联系。
命令:hdfs dfsadmin -refreshNamenodes app-11:9867、hdfs dfsadmin -refreshNamenodes app-12:9867、hdfs dfsadmin -refreshNamenodes app-13:9867

16、退出app-13。
命令:exit

17、查看dfs下有什么。
命令:hdfs dfs -ls /注:这里的输出是dmcluster的。因为在core-site配置文件里defaultFS是dmcluster。

18、如果想要获得dm2的输出需要加一个前缀。
命令:hdfs dfs -ls hdfs://dm2/ 注:这里是空的。

19、创建一个文件夹federation.
命令:hdfs dfs -mkdir hdfs://dm2/federation

20、再次查看目录。
命令:hdfs dfs -ls hdfs://dm2/

21、也可以使用dmcluster前缀查看文件目录。
命令:hdfs dfs -ls hdfs://dmcluster/ 注:这里的文件名前会有目录。

我们需要如何有效的管理这些文件,将这些文件系统挂载到虚拟的文件系统。映射到viewfs系统下。
ViewFS操作
1、进入到hadoop的配置文件下。
命令:cd /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/

2、删除core-site.xml文件。
命令:rm -rf core-site.xml

3、切换到/tmp/Spark—stack目录下。
命令:cd /tmp/Spark-stack/

4、将core-site.xml拷贝到hadoop配置文件下。
命令:cp core-site.xml /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/

5、将文件拷贝到集群的另外两个机器上。
命令:scp core-site.xml hadoop@app-12:/hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/、
scp core-site.xml hadoop@app-12:/hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/

6、不需要重新启动集群,view就可以生效。
命令:hdfs dfs -ls /
注:此时所访问的是view的根目录。hadoop和user是dmcluster里的目录,federation是dm2里的目录。这样我就有效的管理了我们集群。

因为后续的操作不需要做federation和view,所以我们更改回去。
还原配置文件
1、先删除core-site.xml、hdfs-site.xml
命令:rm -rf core-site.xml hdfs-site.xml

2、切换到/tmp/Spark-stack/initialization目录下。
命令:cd /tmp/Spark-stack/initialization/

3、将core-site.xml hdfs-site.xml两个文件拷贝到hadoop的配置文件下。
命令:cp core-site.xml hdfs-site.xml /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/

4、将配置文件拷贝到集群的另外两台机器上。
命令:scp core-site.xml hdfs-site.xml hadoop@app-12:/hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/、
scp core-site.xml hdfs-site.xml hadoop@app-13:/hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/

5、登录到app-13。
命令:ssh hadoop@app-13

6、停止namenode。
命令:hdfs --daemon stop namenode

7.查看是否关闭。
命令:jps

8、退出app-13。
命令:exit
 友情提示:详细学习内容可观看Spark快速大数据处理——余海峰https://edu.csdn.net/course/detail/24205
友情提示:详细学习内容可观看Spark快速大数据处理——余海峰https://edu.csdn.net/course/detail/24205
MR基本用例


下载程序
1、切换到hadoop用户下。
命令:su – hadoop

2、查看集群是否正常工作。
命令:jps

3、切换到/tmp目录下,并创建mr文件。注:这个mr是之前在做Java例子时创建的,现在可以删除掉。
命令:cd /tmp/、mkdir mr

4、进入Spark-stack/Hadoop/目录下。
命令:cd Spark-stack/Hadoop/

5、将WordCount程序拷贝到/tmp/mr/目录下。
命令:cp -r WordCount/* /tmp/mr/

6、打开org/apache/hadoop/examples目录下的WordCount.java文件。
命令:vi org/apache/hadoop/examples/WordCount.java

7、因为现在是hadoop的集群环境中编译程序,而不是在idea中导出jar包,需要把包的信息注释。

代码解释

解析输入函数的输入参数、输入的路径、输出的路径。 创建Job,代表MapReduce的整个过程。
 将多个输入文件或者路径加到job中
将多个输入文件或者路径加到job中

Key为行号、value为给map的每一行的字符串、context定义整个上下文环境。首先现将value变成string,再通过StringTokenizer方法变成一个个的单词存放在word中,再将word中出现的单词和频次存放到context中。

已经将map中的相同的key的内容集合到一起。将同一个key的多个做map的结果进行一个求和。
编译
1、设置环境变量HADOOP_CLASSPATH。
命令:export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar

2、因为Java文件存放在WordCount/org/apache/hadoop/examples/目录下,所以进入该目录下。
命令:cd org/apache/hadoop/examples/

3、进行编译。
命令:hadoop com.sun.tools.javac.Main WordCount.java注:会出现很多class文件。

4、将class文件打包,打包成一个可以执行的jar包。
命令:jar cf WordCount.jar WordCount*.class

运行MapReduce
1、查看目录。
命令:hdfs dfs -ls /注:有一个安装路径installTest。

2、查看installTest目录。
命令:hdfs dfs -ls /installTest

3、查看hadoop目录。
命令:hdfs dfs -ls /installTest/Hadoop 注:data目录就是在安装时的目录,output是之前在做hadoop安装测试时的mapreduce任务。

4、查看data目录。
命令:hdfs dfs -ls /installTest/hadoop/data

5、提交MapReduce程序。
命令:hadoop jar WordCount.jar WordCount /installTest/hadoop/data /installTest/hadoop/output3 注:输入是/installTest/hadoop/data,输出是/installTest/hadoop/output3,确保输出是不存在的。map需要缓步启动,reduce需要map启动完才运行。


6、查看结果。
命令:hdfs dfs -ls /installTest/hadoop/output3

7、结果在part-r-00000文件里。查看该文件。
命令:hdfs dfs -cat /installTest/hadoop/output3/part-r-00000

前面的字符串是输入数据也就是data里出现过的字符串,数字是出现的次数。
友情提示:详细学习内容可观看Spark快速大数据处理——余海峰https://edu.csdn.net/course/detail/24205
Wordcount例子Python版本
下载程序
1、登录hadoop用户下。
命令:su - hadoop

2、进入到tmp目录下。
命令:cd /tmp/

3、将mr是运行Java例子创建,我需要将mr全部删除。
命令:rm -rf mr/

4、再创建mr。
命令:mkdir mr

5、进入Spark-stack/Hadoop/目录。
命令:cd Spark-stack/Hadoop/

6、将WordCount-python文件拷贝到mr目录下。
命令:cp -r WordCount-python/* /tmp/mr/

7、确保Python正常安装。
命令:python –-version 注:我们的Python是2.7.5版本。
8、寻找streaming.jar的位置。
命令:find /hadoop/Hadoop/hadoop-3.1.2 -name "*streaming*.jar" 注:在hadoop的安装文件里寻找以streaming包括streaming,以.jar为结尾的文件。

9、在运行之前我们需要找到数据存储目录。
命令:hdfs dfs -ls /

10、数据存储在installTest/hadoop目录下。
命令:hdfs dfs -ls /installTest/Hadoop

11、进入到/tmp/mr目录下。
命令:cd /tmp/mr

12、在正式提交集群之前,我们可以做一个简单的测试,验证Python脚本的正确性。
命令:cat /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/hdfs-site.xml | python WordCountMapper.py | sort | python WordCountReducer.py注:以hadoop的配置文件hdfs-site.xml为输入,依次运行Mapper、排序和Reducer

代码简析

从stdin中读取文本信息,将多余的空格去掉,化成一个个的单词,遍历每个单词,输出到流里。

从stdin中读取mapper的输出,再对相同key的value值累加,然后打印出每一个key总数。
运行
1、进行运行。
命令:hadoop jar hadoop/Hadoop/hadoop-3.1.2/share/hadoop/tools/lib/hadoop-streaming-3.1.2.jar \、> -input /installTest/hadoop/data -output /installTest/hadoop/output5 \、> -file /tmp/mr/WordCountMapper.py -file /tmp/mr/WordCountReducer.py \、> -mapper WordCountMapper.py -reducer WordCountReducer.py
注:首先找到jar文件,空格加\可以多行输入,输入是data目录,输出是output5,确保输出目录是不存在的,将Mapper和Reducer放到文件缓存中,最后定义Mapper和Reducer。


2、先找到执行结果的文件。
命令:hdfs dfs -ls /installTest/hadoop/output5

3、查看执行结构文件。
命令:hdfs dfs -cat /installTest/hadoop/output5/part-00000

字符串是data输入中的字符串,数字是字符串出现的次数。
友情提示:详细学习内容可观看Spark快速大数据处理——余海峰https://edu.csdn.net/course/detail/24205
MapReduce基本原理
输入数据是怎么来的
Hadoop将我们的输入数据划分为等长的数据块,被称为输入的分片,Hadoop为每个分片构建一个map任务,并用该任务来运行用户自定的map函数来处理分片中的每一条记录,map结果就是每一条记录输出的结果。
负载均衡
每个分片所需的时间少于处理输入数据所花的时间。因此,如果并行的处理每个分片,且每个分片的数据比较,那么整个处理过程将获得更好的负载均衡。因为我们一台快计算机它能够处理的数据分片肯定比一台慢的计算机处理的多,而且成一定的比例。如果说,我们把输入分片分的比较细,那么这样,可以达到某种负载均衡或者多的可以承载多的,少的承载少的。但是,如果我们的分片比较大,那么我们就会卡死在这个节点上。比如说,有10个分片需要承载,要用1为单位的承载,可以承载为10份;如果用3为单位的承载,3份还多1份,没法平均起来。也就是分片要小,我们才能做的更好的负载均衡。如果输入分片太小,这个整个输入性能不一定越好,因为在管理分片,在运行map任务的时间可能比处理分片的时间还要多,那么,就是相当于拣了芝麻丢了西瓜,那么这个分片过小,在这里是不划算的。那要怎么样才能产生一个均衡的结果,之前讲的HDFS文件是分为许多的数据块,数据块是承载在DataNode节点上。比如说,每个数据块都是128兆、64兆这种数据块是比较大的,因为我们面临的问题是大数据集的情况,且每个数据块将占用我们NameNode的一部分资源,将数据块切的太小,我们将会受到一定的损失,特别是NameNode的性能损失,所以我们要适中,这是架构层面的考虑。而且Map做的时候都是本地化,什么是数据本地化,在做大数据处理的时候,要借用本地化的处理措施来获得性能,在前面我们的hadoop3的目标中我们讲过,计算要尽可能的靠近数据,而且计算搬移的性能较为容易一些,数据很难搬移。那么最恰当的目标是将计算分布在数据所处理的节点上,那么Map可以达到这个目标。我们在数据所在的节点上执行Map线程将数据存储在节点所在的缓存里。因此就可以在Map端节约网络资源,集群的带宽资源。此外,还要明确一个概念,为什么最佳的分片大小和块的大小相同,而不是和两个块的大小?是因为,如果分片跨越两个数据块任何一个HDFS节点基本上不可能同时存储这两个数据块,因为对于任何HDFS节点也就是DataNode不可能有同时存储两个数据块,这个数据可靠性的要求。
MapReduce优点
1、可以在MapReduce里的job中设置combiner。 2、Map将数据存在本地的系统里,这个过程并不是简单的写到磁盘。在我们软件设计里面就会经常用的这一点,就是有一个循环的缓冲区,这个缓冲区是内存的,它的速度和性能比磁盘的要高,在每一个Map任务的机器上我们设置一个循环的缓冲区,将Map的结果写到缓冲区,当这个缓冲区写满之后,再将写到溢出到文件里面去,这个过程是可以控制的,每个缓冲的区的大小,都是可以控制的。 3、Reduce的过程就相当于先做拷贝再做计算,在拷贝的过程就是做一个合并,是一个逐步的拷贝,因为在Map的过程就是缓慢的,合并次数可以设定。
MapReduce内部机制

程序过程
输入有三个切片,对应的map结果是分别是:Dear,1、Hello,1、World,1和World,1、Hello,3、Dear,2以及World,1、Hello,2、World,1。当我们的shuffle进程完成之后,我们的数据已经get到了,比如dear1和dear2,为了减少数据传输量,在我们做work的时候,将dear1和dear2做一次运算,那么只传输一条记录dear3,做这项功能的叫combiner。之后有两个sort,by key和by value第一个sort是根据key做排序,第二个sort是根据value做排序,做完sort之后,送到给reduce,reduce在将数据写到output里面。
程序原理
如果将两个数据块分配同一个Map那么将可能产生网络的传输,会降低Map传输的性能。虽然将数据存在了Map的DataNode的本地节点,也就是Map放在的本地的文件系统里。而不是HDFS中,这是因为HDFS需要存到用于备份,这样又产生了网络层的数据传输,所以说,将Map的结果存到本地的文件系统里面。因此,Reduce任务需要有一个shuffle过程,就是混洗过程。混洗过程会产生一个网络传输,混洗的过程将Map所在的节点上的结果数据,拷贝到Reduce所在的节点上。而且,因为有多个Reduce,每个Reduce要处理Map结果的子集。因为Map结果有很多的key,需要有一个分区器,把Map结果挂分到Reduce上,也就是选取那些key给哪一个Reduce,在这个分区环节已经确定了。同时这也是Map和Reduce这两个函数的耦合点,因为在做Map的时候,需要知道,这个分区是怎么样做的。所以说, Map的输出要做分区,有了个这个分区之后哪些Map需要送达给哪个Reduce,或者反过来说,我们的shuffle这些线程才能够知道我们去取哪些分区给哪一个Reduce。 在之间做的例子中,输出文件中会有一个part -r -00000结果文件,既然有00000文件,肯定也会有00001文件,是因为做一个Reduce那么就会输出一个结果,相当于输出了一个结果的分区,所以会有多个part-r的输出。
关键总结
1,排序(Shuffle 阶段):排序是MapReduce的默认行为,两次排序行为:第一次在Map的环形缓冲区中(排序后分区),第二次在Reduce的合并切片数据后(排序后分组) 2,分区(Shuffle 阶段):确保相同key的数据分到同一个Reduce中3,分组(Reduce阶段):确保相同key的数据进入同一个reduce()方法迭代器中 4,合并(Shuffle 阶段):把所有溢写的临时文件进行一次合并操作,以确保一个Map 最终只产生一个中间数据文件。 5,多次写磁盘的时机:1、多次溢写的小文件;2、小文件排序合并;3、分区后形成的数据块等待Reduce拉取;4、Reduce拉取每台map所在机器上的数据块;5、Reduce合并所有的数据块进行排序分组
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Hadooop1.0时代
由于Hadoop1.0良好特性,比如说bat,Facebook,雅虎等都在大数据处理系统中用了Hadoop,但是随着Hadoop1.0使用的日益丰富,用的越来越多了,那么原来的Hadoop1.0中存在的问题逐渐暴露出来。主要体现在四个方面。
SPOF
第一个方面单点故障。因为Hadoop1.0时候NameNode和JobTracker设计成单一结点。JobTracker是提交任务的管理者,但是它是单节点,一旦该节点出现故障对整个系统产生致命性影响。因为NameNode和JobTracker放在了一起,这严重制约了Hadoop的可可展性和可靠性。因为我们是在生产环境中使用,如果不能做到高可靠,我们的生产系统很难做到大规模推广。随着我们的业务越来越多,所部署的大数据系统不可能就放一个业务,而是有一个任务队列,在任务队列中也有许多的任务,随着JobTracker的业务增长,处理任务也随着增长同时内存消耗过大也会产生一些任务失败的情况,那么单节点就将大规模的应用给堵死了。
Only MR
第二个方面是仅仅支持MapReduce。这个计算模式比较单一。然而在现实业务中存在很多的需求,比如,对实时业务及时处理就产生了Storm和Spark。需要图的处理,图是计算机里非常重要的数据结构抽象,也需要这种处理模式。这些就不仅仅是MapReduce可以解决的处理框架。那么怎么样整合这些处理框架,数据在Hadoop中,不能将计算搬移到数据所在的节点上,那么框架的应用会受到很大的限制。
MR Slot
第三个方面是MapReduce框架不够灵活。因为Map和Reduce绑得太死,先进行Map再进行Reduce中间有个Shuffle,这个作为整个Map和Reduce的耦合点之一。因为Map和Reduce作为一个整体给用户使用的,但是,并不是每个业务都需要同时操作,有时只需要其中之一。但是Hadoop1.0中TaskTracker将任务分解为Map Tracker Slot和Reduce Tracker Slot。Slot在大数据的理解为分配的资源词,从硬件的Slot抽象到软件的Slot。如果,当前节点只存在Map或者只存在Reduce这种任务,需要同时分配两个插槽也就是两个Slot,这样就会造成资源浪费,因为只有单一的Map和单一的Reduce。
RM
最后一个方面是资源管理不灵活,因为采用的是静态Slot分配措施,就是在任务提交分析完之后,Slot已经分配了,而且在每个节点启动前为每个节点配置好Slot总数,一旦启动后就不能动态更改,并且Map Slot和Reduce Slot不允许交换。
YARN架构

Yarn有三个组件,分别为Resource Manager、Node Manager和Application Master。Resource Manager是管理器的核心组件,采用的是主从结构,负责所有资源的监控、分配和管理。Application Master负责每个应用程序的调度和协调。Node Manager负责本节点资源的维护。因为所有的程序都要跑在每一个节点上,做底层工作的是Node Manager,因为Node Manager上有很多的Container去跑计算机任务。 Resource Manager需要获取Node Manager的情况,Container需要向Application Master汇报情况。
Flink运行在Yarn上

可以将Flink理解为某个计算任务。首先向Flink计算框架提交任务,在Flink框架里有YARN的客户端,Flink将其他的资源打包成Uberjar先提交给HDFS,HDFS是整个集群所能共享的相当于一个缓存。然后,向YARN Resource Manager申请am,am是处理层的管理者。申请一个项目协调小组,由一个总的Container控制,下分许多单个Container。将任务的执行文件也就是Uberjar拷贝到本地执行,执行完之后,或者执行的过程中,向总的Container汇报情况。由此可见,YARN将任务协调交给了应用程序的本身。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

1、在app-11上以hadoop用户登录。
命令:su - hadoop

2、输入yarn命令。
命令:yarn注:三类命令,管理命令、客户端命令、守护进程命令

3、展示所有关于node的命令。
命令:yarn node

4、将集群的所有信息打印出来。
命令:yarn node -list -all注:包括节点信息、节点状态、节点地址、节点上的Containers

5、管理命令。
命令:yarn rmadmin

6、查看所有的service状态。
命令:yarn rmadmin -getAllServiceState

7、管理application的命令。
命令:yarn app

8、命令:yarn app -list
注:因为还没有提交任务,所有现在list结果为空。

9、查看环境变量。
命令:yarn envvars

10、运行jar文件。
命令:yarn jar

11、查看yarn版本。
命令:yarn version

12、打印需要得到Hadoop的jar和所需要的lib包路径。
命令:yarn classpath 注:这里的classpath和hdfs是一样的。

13、动态展现yarn的执行情况。
命令:yarn top注:将CPU、内存使用情况、任务完成情况打印出来

14、按Ctrl+c退出当前状态。

详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

RM HA配置文件详解
1、启动resourcemanager的ha。

2、对集群进行命名。

3、配置resourcemanager的ids,可以定义多个,在本地就定义了两个rm1和rm2。

4、做ha是通过zookeeper协调组件,需要定义zookeeper的地址。

5、将虚拟机的检验工作禁止。

6、配置resourcemanager的hostname和address。

手动切换active和standby
1、确保集群正常启动。
命令:jps

2、将resourcemanager的rm1变为Standby,因为之前查看的rm1是active。
命令:yarn rmadmin -transitionToStandby rm1 --forcemanual

3、选择Yes。
命令:Y

4、检查集群的情况。
命令:yarn rmadmin -getAllServiceState

5、再将rm2变为active状态。
命令:yarn rmadmin -transitionToActive --forceactive --forcemanual rm2
再输入Y

6、再次检查集群的情况。
命令:yarn rmadmin -getAllServiceState
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Yarn调度器配置
理想情况下,我们应用对Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源。在Yarn中,负责给应用分配资源的就是Scheduler。其实调度本身就是一个难题,很难找到一个完美的策略可以解决所有的应用场景。
在Yarn框架中,调度器是一块很重要的内容。有了合适的调度规则,就可以保证多个应用可以在同一时间有条不紊的工作。最原始的调度规则就是FIFO,即按照用户提交任务的时间来决定哪个任务先执行,但是这样很可能一个大任务独占资源,其他的资源需要不断的等待。也可能一堆小任务占用资源,大任务一直无法得到适当的资源,造成饥饿。
为了解决以上问题,yarn提供了两种调度器,分别为:容量调度器和公平调度器。
容量调度器
原理
针对多用户调度,容量调度器采用的方法稍有不同。集群由很多队列组成,这些队列可能是层次结构的(因此,一个队列可能是另一个队列的子队列),每个队列被分配有一定的容量。本质上,容量调度器允许用户或组织为每个用户或组织模拟出一个使用FIFO调度策略的独立集群。容量调度器说的通俗点,可以理解成一个个的资源队列。这个资源队列是用户自己去分配的。
配置文件改动
1、调度器所占的最大份额设置为0.5。如果分配的过小,一个任务大概3G的内存,am会一直在等待过程中,无法进行下去。

2、root的队列是default,default的容量是100%,所有的任务都在同一个队列里面。

容量调度器演示
1、将default队列的情况打印出来。
命令:yarn queue -status default注:包括状态、容量、当前的容量、最大的容量

公平调度器
原理
公平调度器的目标是让每个用户公平共享集群能力。如果只有一个作业在运行,就会得到集群的所有资源。随着提交的作业越来越多,闲置的任务就会以“让每个用户公平共享集群”这种方式进行分配。某个用户的耗时短的作业将在合理的时间内完成,即便另一个用户的长时间作业正在运行而且还在运行过程中。
将整个集群资源都分配给应用程序,当提交其他应用程序的时候,已经释放的资源分配给新的应用程序。因此,每个应用程序最后都能粗略的获得等量的资源。
代码解释
Client向Resource Manager申请资源运行ApplicationMaster,ApplicationMaster向Node Manager申请资源也就是container,这里我们申请了10个container,去运行javaPi程序。

Client.java

1、创建Yarn的Client端,启动Yarn的Client端。
2、用YarnClient创建Application,得到application的上下文。注意,在Yarn中不允许提交相同名字的应用程序。
3、设置am的资源申请量,1G和一核。
4、设置application的环境变量。
ApplicationMaster.java

1、创建AMRMClient端,Application Master要向Resource Manager申请资源。
2、创建nmClient端,是向Node Manager交互的客户端。
3、向RM注册心跳信息。
4、申请container。
Yarn编程实战
下载程序
1、在app-11上,确保集群是启动的。
命令:jps
2、切换到tmp目录下。
命令:cd /tmp

3、创建yarn文件。
命令:mkdir yarn

4、进入程序所在的文件夹下。
命令:cd Spark-stack/yarnExample/src/main/

5、将Java文件拷贝到新建的yarn文件夹下。
命令:cp -r java/* /tmp/yarn/

6、进入yarn目录下。
命令:cd /tmp/yarn/

编译程序
7、确定tools.jar存在。
命令:export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar

8、使用hadoop命令编译程序。
命令:hadoop com.sun.tools.javac.Main org/apache/hadoop/yarn/examples/*.java注:程序文件在examples目录下,编译.java文件。

9、查看examples目录下。
命令:ls org/apache/hadoop/yarn/examples/
注:会出现许多的class文件。

10、将class文件打包。
命令:jar cf app.jar org/apache/hadoop/yarn/examples/*.class

打开程序应用状态监视
11、new terminal,之后使用hadoop用户登录。
命令:su – hadoop

12、监视。
命令:yarn top

运行程序
13、返回之前的new terminal,使用hadoop命令提交程序。
命令:hadoop jar app.jar org.apache.hadoop.yarn.examples.Client 注:程序会一直运行下去,一直获取appID的情况。

Top的监视结果。

14、按Ctrl+c停止程序。

查看打印
15、新建new terminal,hadoop用户登录。
命令:su – hadoop

16、javaPi打印,先进入hadoop-3.1.2/logs目录下。
命令:cd /hadoop/Hadoop/hadoop-3.1.2/logs/

17、在进入userlogs目录下。
命令:cd /hadoop/Hadoop/hadoop-3.1.2/logs/userlogs/
注:这里有所有的执行container任务。

18、进入application_1602472376409_0001目录下。
命令:cd application_1602472376409_0001/注:app-11上有两个个container,分别为02和06.

查看其它机器的container
19、在app-12上,hadoop用户登录。
命令:su – hadoop

20、进入application_1602472376409_0001目录下。
命令:cd/hadoop/Hadoop/hadoop-3.1.2/logs/userlogs/application_1602472376409_0001/ 注:这里的container有三个。

21、在app-13上,hadoop用户登录。
命令:su – hadoop

22、进入application_1602472376409_0001目录下。
命令:cd/hadoop/Hadoop/hadoop-3.1.2/logs/userlogs/application_1602472376409_0001/ 注:这里的container有四个。

23、随机查看一个contain的运行结果。
命令:cat container_1602472376409_0001_01_000009/stdout

常见问题

问题解释:在javaPi中有些字符串不识别,这里是注释的中文不识别。 问题解决:将javaPi中的中文解释删除。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

作业
1、独立完成Hadoop HA集群的搭建与验证。
为什么选择Tez
为什么要用Tez
在分布式系统中要存储海量的数据,因为构建了一个非商务的机器上能够运行的hdfs分布式存储空间,而且这个存储空间是低成本的并且具有良好的扩展性。那么,很多企业都会将海量的存储数据迁移到Hadoop上,而摒弃之前用的ioe方式。然后,在利用Hive和Pig提供的类SQL语句完成我们的大规模的数据处理,以应对数据挖掘以及数据准备的应用场景。为什么这么选择,是因为存储廉价和开发人员是相对丰厚的。Hive和Pig如果需要通过MapReduce进行处理的话,那么解决问题的实时性得不到满足。
Tez在大数据架构的层次图
 数据存储,如果有一个交互式查询任务,Tez负责通过Hive或者Pig等转化为Tez有向无环图的执行方式去执行查询,然后将查询的任务提交到YARN。Spark和Flink有自己的结构框架提交YARN。
数据存储,如果有一个交互式查询任务,Tez负责通过Hive或者Pig等转化为Tez有向无环图的执行方式去执行查询,然后将查询的任务提交到YARN。Spark和Flink有自己的结构框架提交YARN。
之所以还继续选择Tez框架,是因为Tez可以做为底层的计算框架,可以集成在YARN上。
MapReduce和Tez对比

这幅图展示了进入MR和进入Tez的Pig/Hive查询架构、性能的对比。蓝色的块代表做Map,绿色的块代表做Reduce,一个圆圈表示做了一个完整MapReduce的job,连接圆圈之间是结果输出到hdfs中。左侧图中做了四个MapReduce的任务,关系是树,有三次hdfs的写入。在右侧中只有一次写入hdfs,将最终的结果写入。
性能对比

Query27、Query82、Query52、Query55、Query12是查询的种类。

Tez特征
1、分布式执行框架,面向大规模数据处理应用的分布式数据查询的引擎,包含:分布式计算的数据处理框架、可以集成到YARN底层透明的给应用提供执行框架。
2、基于将计算表示为数据流图。
3、构建在YARN之上——Hadoop的资源管理框架。
4、简化部署。
5、数据类型不可知。
6、动态物理数据流决策。
7、运行时计划重新配置。
Tez基本架构

这是逻辑图,Tez是进入DAG的,所以要创建一个DAG。之后创建每个节点,创建每个节点之间的编。

这是物理图,在实际的应用中会有多个并行实例。在实际的物理部署中Tez采用SGather形式将数据发射出去,由Bipartie去拉取需要的数据。

这种执行需要Tez的执行引擎做调度。DAG的执行引擎包括了三个主要部分,两个调度器一个管理者。Vertex Manager将逻辑计算图形式转化为tasks形式。有多个job就会有对应的多个DAG调度器,Task调度器要调度每个计算图的Hadoop集群的物理节点上执行的时间。

左侧图是从Application Master整个集群框架的视角看,DAG的执行过程。通过Client端去提交DAG,提交之间会进行start Session,Session和Application Master交互,向Application Master提交任务,Application Master在YARN集群上。然后Application Master去管理Container Pool(容器的池)。
右侧图是AM承担的重要角色处理信息,通过AM去处理各个Task,因为Task之间是无法直接交流的。比如,Map Task2做完任务有Data Event的输出,需要告诉AM,AM中的Router(相当于路由器)将数据路由到Reduce Task2上。路由的过程并不是在Map Task2的物理节点上拷贝到AM上然后再发送给Reduce Task2所在的节点上,而是提供了一个路由功能,是控制信息的路由,数据是直达的。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

为什么选择Tez
为什么要用Tez
在分布式系统中要存储海量的数据,因为构建了一个非商务的机器上能够运行的hdfs分布式存储空间,而且这个存储空间是低成本的并且具有良好的扩展性。那么,很多企业都会将海量的存储数据迁移到Hadoop上,而摒弃之前用的ioe方式。然后,在利用Hive和Pig提供的类SQL语句完成我们的大规模的数据处理,以应对数据挖掘以及数据准备的应用场景。为什么这么选择,是因为存储廉价和开发人员是相对丰厚的。Hive和Pig如果需要通过MapReduce进行处理的话,那么解决问题的实时性得不到满足。
Tez在大数据架构的层次图
数据存储,如果有一个交互式查询任务,Tez负责通过Hive或者Pig等转化为Tez有向无环图的执行方式去执行查询,然后将查询的任务提交到YARN。Spark和Flink有自己的结构框架提交YARN。
之所以还继续选择Tez框架,是因为Tez可以做为底层的计算框架,可以集成在YARN上。
MapReduce和Tez对比
这幅图展示了进入MR和进入Tez的Pig/Hive查询架构、性能的对比。蓝色的块代表做Map,绿色的块代表做Reduce,一个圆圈表示做了一个完整MapReduce的job,连接圆圈之间是结果输出到hdfs中。左侧图中做了四个MapReduce的任务,关系是树,有三次hdfs的写入。在右侧中只有一次写入hdfs,将最终的结果写入。
性能对比
Query27、Query82、Query52、Query55、Query12是查询的种类。
Tez特征
1、分布式执行框架,面向大规模数据处理应用的分布式数据查询的引擎,包含:分布式计算的数据处理框架、可以集成到YARN底层透明的给应用提供执行框架。
2、基于将计算表示为数据流图。
3、构建在YARN之上——Hadoop的资源管理框架。
4、简化部署。
5、数据类型不可知。
6、动态物理数据流决策。
7、运行时计划重新配置。
Tez基本架构
这是逻辑图,Tez是进入DAG的,所以要创建一个DAG。之后创建每个节点,创建每个节点之间的编。
这是物理图,在实际的应用中会有多个并行实例。在实际的物理部署中Tez采用SGather形式将数据发射出去,由Bipartie去拉取需要的数据。
这种执行需要Tez的执行引擎做调度。DAG的执行引擎包括了三个主要部分,两个调度器一个管理者。Vertex Manager将逻辑计算图形式转化为tasks形式。有多个job就会有对应的多个DAG调度器,Task调度器要调度每个计算图的Hadoop集群的物理节点上执行的时间。
左侧图是从Application Master整个集群框架的视角看,DAG的执行过程。通过Client端去提交DAG,提交之间会进行start Session,Session和Application Master交互,向Application Master提交任务,Application Master在YARN集群上。然后Application Master去管理Container Pool(容器的池)。
右侧图是AM承担的重要角色处理信息,通过AM去处理各个Task,因为Task之间是无法直接交流的。比如,Map Task2做完任务有Data Event的输出,需要告诉AM,AM中的Router(相当于路由器)将数据路由到Reduce Task2上。路由的过程并不是在Map Task2的物理节点上拷贝到AM上然后再发送给Reduce Task2所在的节点上,而是提供了一个路由功能,是控制信息的路由,数据是直达的。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
编译Tez
由于在Tez-Yarn的官网上并没有关于hadoop3.1.2对应的Tez-Yarn安装包,所以我们进行针对性的编译。先检测Maven是否安装了。
修改pom.xml

编译modules,将tez-ui注释掉,不需要编译tez-ui。
检测Maven是否安装
1、在app-11上,使用hadoop用户登录。
命令:su - hadoop

2、检测Maven是否安装。
命令:mvn -version

3、进入cd/hadoop/tools/目录下。
命令:cd /hadoop/tools/

4、这里没有Maven,下载Maven。
命令:wget http://archive.apache.org/dist/maven/maven-3/3.6.0/binaries/apache-maven-3.6.0-bin.tar.gz

5、解压。
命令:tar -xf apache-maven-3.6.0-bin.tar.gz

6、在环境变量中加入MAVEN_HOME路径。
命令:vi ~/.bashrc
exportMAVEN_HOME=/hadoop/tools/apache-maven-3.6.0
export PATH=${MAVEN_HOME}/bin:$PATH

7、将新添加的环境变量生效。
命令:source ~/.bashrc、echo $PATH

8、查看Maven是否安装成功。
命令:mvn -version

下载编译程序
9、切到tmp目录下。
命令:cd /tmp/

10、创建tez文件。
命令:mkdir tez

11、进入Spark-stack/Tez目录下。
命令:cd Spark-stack/Tez

12、将buildTez下的内容拷贝到tez目录下。
命令:cp buildTez/* /tmp/tez/

13、切换到tez目录下。
命令:cd /tmp/tez/

14、解压apache-tez-0.9.0-src.tar.gz。
命令:tar -xf apache-tez-0.9.0-src.tar.gz

15、将pom.xml拷贝到源码目录下。
命令:cp pom.xml apache-tez-0.9.0-src

16、进入源码目录。
命令:cd apache-tez-0.9.0-src

编译
17、开始编译。
命令:mvn -X clean package -DskipTests=true -Dhadoop.version=3.1.2 -Phadoop28 -P!hadoop27 -Dprotoc.path=/hadoop/tools/protobuf-2.5.0/bin/protoc -Dmaven.javadoc.skip=true
注:使用hadoop3.1.2版本,不使用2.7版本。同时在tools里面安装了protobuf组件,将path写在这个命令行上,并且不进行测试。编译的时间是9分钟。显示每个模块相关的编译耗时。

18、安装包在tez-dist目录下。
命令:cd tez-dist/

19、进入target目录。
命令:cd target/ 注:有了tez-0.9.1-minimal.tar.gz和tez-0.9.1.tar.gz这两个包证明编译成功。

安装有两种方式,第一种是先进行编译,将编译出来的安装包拷贝到集群上,命令:cp tez-0.9.1-minimal.tar.gz tez-0.9.1.tar.gz /安装tez的路径。第二种是github上有对应的安装包,直接下载到对应的位置。
安装
修改hadoop-env.sh

增加了三个配置。
修改mapred-site.xml

将mapreduce框架改为yarn-tez。

增加tez-site.xml tez.lib.uris指向/user/tez/tez-0.9.0.tar.gz。
下载安装包
1、返回根目录。
命令:cd

2、检查集群是否正常启动。
命令:jps

3、在hadoop根目录下创建tez安装文件。
命令:mkdir /hadoop/Tez

4、进入Spark-stack/Tez目录下。
命令:cd /tmp/Spark-stack/Tez/

5、这是直接在GitHub上下载安装包。Tez安装包在apache-tez-0.9.0-bin目录下,将该目录下的安装拷贝到安装Tez目录下。
命令:cp apache-tez-0.9.0-bin/* /hadoop/Tez/

6、进入安装Tez目录下。
命令:cd /hadoop/Tez/

将tez-0.9.0.tar.gz上传到hdfs中
7、先创建tez目录。
命令:hdfs dfs -mkdir /user/tez

8、将安装包上传到tez目录下。
命令:hdfs dfs -put tez-0.9.0.tar.gz /user/tez/

9、查看是否上传成功。
命令:hdfs dfs -ls /user/tez/

10、进入hadoop的配置文件。
命令:cd /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/

11、将mapred-site.xml和hadoop-env.sh文件删除。
命令:rm -rf mapred-site.xml hadoop-env.sh

将配置文件拷贝到集群的各个机器上
12、进入Spark-stack/Tez/目录下。
命令:cd /tmp/Spark-stack/Tez/

13、将配置文件拷贝到hadoop的配置文件下。
命令:cp -r conf/* /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/

14、将配置也拷贝到app-12和app-13上。
命令:scp -r conf/* hadoop@app-12:/hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/、 scp -r conf/* hadoop@app-13:/hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/
注:因为scp是覆盖拷贝所以不需要删除。

解压tez-0.9.0-minimal.tar.gz
15、进入Tez安装目录。
命令:cd /hadoop/Tez/

16、创建tez-0.9.0-minimal。
命令:mkdir tez-0.9.0-minimal

17、将tez-0.9.0-minimal.tar.gz解压到tez-0.9.0-minimal。因为在hadoop-env.sh中添加的TEZ_JARS在tez-0.9.0-minimal目录下。
命令:tar -xf tez-0.9.0-minimal.tar.gz -C tez-0.9.0-minimal

18、进入到tez-0.9.0-minimal目录下。
命令:cd tez-0.9.0-minimal

集群重启
19、先停止集群。
命令:stop-all.sh

20、登录app-12上停止historyserver。
命令:ssh app-12 "mapred --daemon stop historyserver"

21、检查启动的集群。
命令:jps 注:除了zookeeper进程在启动没有其他进程。

22、登录其他的机器确保只有zookeeper进程。
命令:ssh app-12 "jps"、ssh app-13 "jps"

23、启动hadoop集群。
命令:start-all.sh

24、重新启动app-12上的historyserver。
命令:ssh app-12 "mapred --daemon start historyserver"

25、使用jps检查集群。
命令:jps注:NameNode、NodeManager、ResourceManager均已经启动了。

测试
26、查看tez-0.9.0-minimal目录。
命令:ls注:用这里的example做测试。

27、查看hdfs的目录。
命令:hdfs dfs -ls/

28、做测试的输入是做hadoop安装时做测试的文件。这个文件在/installTest/hadoop/data目录下,先查看该目录的文件。
命令:hdfs dfs -ls /installTest/hadoop/data

29、MapReduce测试。
命令:hadoop jar tez-examples-0.9.1.jar orderedwordcount /installTest/hadoop/data /installTest/hadoop/output3
注:hadoop jar运行tez-examples-0.9.1.jar然后运行tez-examples-0.9.1.jar里的orderedwordcount命令。orderedwordcount的含义是不仅要进行wordcount还要根据word进行排序。输出是/installTest/hadoop/data,输出是/installTest/hadoop/output3,确保输出文件不存在即可

30、查看输出的文件。
命令:hdfs dfs -ls /installTest/hadoop/data /installTest/hadoop/output3

31、输出的结果在part-v002-o000-r-00000中。
命令:hdfs dfs -cat /installTest/hadoop/data /installTest/hadoop/output3/part-v002-o000-r-00000
注:结果是按照value排序的。

常见问题

问题解释:环境变量执行缓慢。
解决办法:多次进行source命令,更新环境变量。
逻辑DataFlow
 Source就是hdfs的文件,经过map,tokenizer顶点相当于map,做完map就可以输出单词加上1,这样的keyvalue键值对。然后对键值对求和,因为这里的求和之后需要排序,所以求和的过程不像MapReduce直接做Reduce,Reduce之后将value和key进行交换,比如之前是Dear,1现在就是2,Dear。在做Reduce的过程中还增加了一个不仅要分区还要排序根据key进行排序,这时候的key就是之前的value。最后,sorter工作,现在sorter的工作就减少了,因为之前已经对键值对进行了排序,现在sorter要将key和value的值交换。进行双排序之后写入Sink。
Source就是hdfs的文件,经过map,tokenizer顶点相当于map,做完map就可以输出单词加上1,这样的keyvalue键值对。然后对键值对求和,因为这里的求和之后需要排序,所以求和的过程不像MapReduce直接做Reduce,Reduce之后将value和key进行交换,比如之前是Dear,1现在就是2,Dear。在做Reduce的过程中还增加了一个不仅要分区还要排序根据key进行排序,这时候的key就是之前的value。最后,sorter工作,现在sorter的工作就减少了,因为之前已经对键值对进行了排序,现在sorter要将key和value的值交换。进行双排序之后写入Sink。
代码解释

dataSource来源于输入input,dataSink是输出的类型以及输出的位置。
定义tokenizerVertex顶点,ProcessorDescriptor定义相关的处理方法,这个处理方法是TokenProcessor,做的还是MapReduce。
创建编summationEdgeConf,是给下一个求和的顶点,顶点先要OrderedPartitionedKVEdgeConfig就是不仅要分区还要排序,这个编的输入类型就是key和value。
定义求和的顶点,求和的顶点由SumProcessor定义,SumProcessor类似于Reduce。
创建sorterEdgeConf编,和summationEdgeConf的功能类似,输入的类型是intkey,stringvalue,因为之前将key和value的值进行交换,连接的下一个顶点就是排序。
sorterVertex进行排序,因为之前做过排序,此处就不需要进行排序了。只是将key和value变换位置。

先获取conf,然后解析输入。
hadoopShim是兼容不同版本,针对不同的版本定义一系列的方法名,这些方法名有可能在不同的版本中对应的名称或者参数的名称可能会不一样。
创建tezConf和TezClient,需要见dag程序提交给applicationmaster,提交之后就可以做runJob。
操作
下载程序
1、在app-11上,以hadoop登录集群。
命令:su – hadoop

2、进入tmp目录下。
命令:cd /tmp/

3、创建tez-example文件。
命令:mkdir tez-example

4、进入Spark-stack/Tez/tezExamples/src/main/java/目录下。
命令:cd Spark-stack/Tez/tezExamples/src/main/java/

5、将org.tar拷贝到tez-example目录下。
命令:cp org.tar /tmp/tez-example/

6、将脚本文件也拷贝到tez-example目录下。先进入脚本文件目录下。
命令:cd /tmp/Spark-stack/Tez/tezExamples/src/resource/

7、将脚本文件也拷贝到tez-example目录下。
命令:cp buildExamples.sh /tmp/tez-example/

8、进入tez-example目录下。
命令:cd /tmp/tez-example/

运行
9、给脚本执行权限。
命令:chmod a+x buildExamples.sh

10、运行打包和提交的工作。
命令:./buildExamples.sh run

详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Hive是什么
 Hive是大数据仓库的基本组件。右侧是用java写的MapReduce的Wordcount例子,使用SQL语句去实现数据的查询、数据的分析。左侧是SQL语句实现Wordcount,首先将每一行切开根据每一个单词Space,从file中hdfs文件,然后根据Word进行排列,这都是map形式,最后再计算每个Word的总量,根据Word进行Order。下方是将上方的语句分解为两个部分,将子查询单独开来,门槛较低,不用写java程序,也不需要调试。
Hive是大数据仓库的基本组件。右侧是用java写的MapReduce的Wordcount例子,使用SQL语句去实现数据的查询、数据的分析。左侧是SQL语句实现Wordcount,首先将每一行切开根据每一个单词Space,从file中hdfs文件,然后根据Word进行排列,这都是map形式,最后再计算每个Word的总量,根据Word进行Order。下方是将上方的语句分解为两个部分,将子查询单独开来,门槛较低,不用写java程序,也不需要调试。

这幅图是Wordcount的Python版本。左侧是Python的map和reduce。右侧是SQL语句实现。相对于SQL语句,Python也是复杂的。 所以说,用SQL语句作为大数据查询分析的语言,可以有效合理而且直观的组织和使用数据模型,以降低数据分析的门槛,这就是Hive能够发展起来的一个动力。但是,这并不说明其他语言的编程接口没有价值,它们所解决的层次是不一样的。在其他的数据处理框架,比如说,Spark、Flink都有对应的SQL语句相关的一些接口。SQL语句不仅仅可以在做批处理上用还可以进入动态表理论、流上使用SQL。并说明,不是其他语言做大数据处理没有价值,将会被SQL淘汰,因为解决问题的层次是不一样的,有一些问题,仍然需要java、Python这种表现力更丰富的语言去做处理。这些框架使用的语言任然是底层语言java语言来编写的,或者理解为用高级语言编写的数据处理效率会更高而且相应的框架会对原生的语言(java语言)支持或者融合度会更好。
Hive基本架构
 Hive包括了三个部分,Hive的客户端、Hive的服务器、数据。Hive的客户端有三类,Thrift、JDBC、ODBC,通过客户端连接服务器,服务器经过一系列的Driver将查询驱动数据仓库,数据仓库是文件。Hive合作的事情是将在HDFS文件,一个个文件抽象成结构化数据的结构,然后用SQL语句去查询分析这些文件的内容。比如说做MapReduce,Hive的服务器将对应的查询SQL语言转化为一系列的MapReduce或者Tez以docker的形式提交给集群比如YARN集群去执行我们相应的数据处理程序。除了Hive Server之外,还可以通过Hive services提供的客户端,或者Web界面的形式去操作SQL语句。体系架构里面有个Metastore,是因为Hive上存的都是一个个文件,文件里是一行行数据或者一行行的记录。为了执行SQL语句,必须要了解数据的各式信息,所谓的元数据信息,这就是Metastore存的基本信息,它不存数据,数据存在HDFS里,Metastore存在关系型数据库里。
Hive包括了三个部分,Hive的客户端、Hive的服务器、数据。Hive的客户端有三类,Thrift、JDBC、ODBC,通过客户端连接服务器,服务器经过一系列的Driver将查询驱动数据仓库,数据仓库是文件。Hive合作的事情是将在HDFS文件,一个个文件抽象成结构化数据的结构,然后用SQL语句去查询分析这些文件的内容。比如说做MapReduce,Hive的服务器将对应的查询SQL语言转化为一系列的MapReduce或者Tez以docker的形式提交给集群比如YARN集群去执行我们相应的数据处理程序。除了Hive Server之外,还可以通过Hive services提供的客户端,或者Web界面的形式去操作SQL语句。体系架构里面有个Metastore,是因为Hive上存的都是一个个文件,文件里是一行行数据或者一行行的记录。为了执行SQL语句,必须要了解数据的各式信息,所谓的元数据信息,这就是Metastore存的基本信息,它不存数据,数据存在HDFS里,Metastore存在关系型数据库里。

这是详细分析Metastore,可以有多个Metastore后端,MySQL是比较常用的,在Hive中提供了内置的Metastore,还有本地的方式也就是将MySQL部署在Hive Services所在的JVM的机器上,还支持远程的JVM去访问MySQL。将采用第三种方式,Hive Service不和MySQL在同一台机器上的部署方式。 Hive可以是计算引擎,唯一接触到数据的地方就是Metastore,存储的也仅仅是元数据,所有带分析的数据都存在的HDFS里面,由HDFS保证数据安全一致性。
和传统数据对比
Hive并不存储数据,仅仅存储元数据信息,数据都是以源文件的形式存储到HDFS中。在关系数据库中如果数据、描述丢失将很难恢复,但是在Hive中,HDFS数据没有丢失,Metastore丢失可以通过数据去恢复Metastore相对容易。 在传统的数据库中,表的模式是在数据加载时强制制定的。如果在加载时,发现数据不符合模式,加载肯定失败。Hive在查询时进行模式检查,在查询的时候才检查要查询的文件在元数据里面是否匹配,可以绕过Hive写入HDFS。这两种方法各有利弊,在Hive中是进入HDFS的,可以进行大数据量的。而传统的关系型数据库很难做到这一点。 性能不一样,Hive数据模式加载时非常快的,因为不需要检查数据格式信息,直接写到HDFS中。在传统数据中写入需要一条条的检查,但是有另一种优势,查询性能是非常高的,因为可以进行数据的索引。 传统型数据库是做事务处理的,Hive在做事务处理方面就不如传统数据库。Hive不支持更新、删除等。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Hive是什么
Hive是大数据仓库的基本组件。右侧是用java写的MapReduce的Wordcount例子,使用SQL语句去实现数据的查询、数据的分析。左侧是SQL语句实现Wordcount,首先将每一行切开根据每一个单词Space,从file中hdfs文件,然后根据Word进行排列,这都是map形式,最后再计算每个Word的总量,根据Word进行Order。下方是将上方的语句分解为两个部分,将子查询单独开来,门槛较低,不用写java程序,也不需要调试。
这幅图是Wordcount的Python版本。左侧是Python的map和reduce。右侧是SQL语句实现。相对于SQL语句,Python也是复杂的。 所以说,用SQL语句作为大数据查询分析的语言,可以有效合理而且直观的组织和使用数据模型,以降低数据分析的门槛,这就是Hive能够发展起来的一个动力。但是,这并不说明其他语言的编程接口没有价值,它们所解决的层次是不一样的。在其他的数据处理框架,比如说,Spark、Flink都有对应的SQL语句相关的一些接口。SQL语句不仅仅可以在做批处理上用还可以进入动态表理论、流上使用SQL。并说明,不是其他语言做大数据处理没有价值,将会被SQL淘汰,因为解决问题的层次是不一样的,有一些问题,仍然需要java、Python这种表现力更丰富的语言去做处理。这些框架使用的语言任然是底层语言java语言来编写的,或者理解为用高级语言编写的数据处理效率会更高而且相应的框架会对原生的语言(java语言)支持或者融合度会更好。
Hive基本架构
Hive包括了三个部分,Hive的客户端、Hive的服务器、数据。Hive的客户端有三类,Thrift、JDBC、ODBC,通过客户端连接服务器,服务器经过一系列的Driver将查询驱动数据仓库,数据仓库是文件。Hive合作的事情是将在HDFS文件,一个个文件抽象成结构化数据的结构,然后用SQL语句去查询分析这些文件的内容。比如说做MapReduce,Hive的服务器将对应的查询SQL语言转化为一系列的MapReduce或者Tez以docker的形式提交给集群比如YARN集群去执行我们相应的数据处理程序。除了Hive Server之外,还可以通过Hive services提供的客户端,或者Web界面的形式去操作SQL语句。体系架构里面有个Metastore,是因为Hive上存的都是一个个文件,文件里是一行行数据或者一行行的记录。为了执行SQL语句,必须要了解数据的各式信息,所谓的元数据信息,这就是Metastore存的基本信息,它不存数据,数据存在HDFS里,Metastore存在关系型数据库里。
这是详细分析Metastore,可以有多个Metastore后端,MySQL是比较常用的,在Hive中提供了内置的Metastore,还有本地的方式也就是将MySQL部署在Hive Services所在的JVM的机器上,还支持远程的JVM去访问MySQL。将采用第三种方式,Hive Service不和MySQL在同一台机器上的部署方式。 Hive可以是计算引擎,唯一接触到数据的地方就是Metastore,存储的也仅仅是元数据,所有带分析的数据都存在的HDFS里面,由HDFS保证数据安全一致性。
和传统数据对比
Hive并不存储数据,仅仅存储元数据信息,数据都是以源文件的形式存储到HDFS中。在关系数据库中如果数据、描述丢失将很难恢复,但是在Hive中,HDFS数据没有丢失,Metastore丢失可以通过数据去恢复Metastore相对容易。 在传统的数据库中,表的模式是在数据加载时强制制定的。如果在加载时,发现数据不符合模式,加载肯定失败。Hive在查询时进行模式检查,在查询的时候才检查要查询的文件在元数据里面是否匹配,可以绕过Hive写入HDFS。这两种方法各有利弊,在Hive中是进入HDFS的,可以进行大数据量的。而传统的关系型数据库很难做到这一点。 性能不一样,Hive数据模式加载时非常快的,因为不需要检查数据格式信息,直接写到HDFS中。在传统数据中写入需要一条条的检查,但是有另一种优势,查询性能是非常高的,因为可以进行数据的索引。 传统型数据库是做事务处理的,Hive在做事务处理方面就不如传统数据库。Hive不支持更新、删除等。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
修改模板配置文件解释
修改hive-default.xml.template
 修改了两个目录的路径,将Hive的配置文件存在安装目录的tmp下,所以会创建一个tmp。将所有产生的临时文件或者配置文件,所有的工作内容都放到了安装目录下。
修改了两个目录的路径,将Hive的配置文件存在安装目录的tmp下,所以会创建一个tmp。将所有产生的临时文件或者配置文件,所有的工作内容都放到了安装目录下。
 将metastore的路径更改到app-12上。
将metastore的路径更改到app-12上。
 相关的连接密码修改为Yhf_1018。
相关的连接密码修改为Yhf_1018。
 连接的字符串。
连接的字符串。
 在初始化之后会创建schema,不需要检验。
在初始化之后会创建schema,不需要检验。
修改hive-log4j2.properties.template
 将log的目录更改到安装目录下。
将log的目录更改到安装目录下。
启用自动化集群脚本
1、在app-11上,以hadoop用户登录。
命令:su - hadoop

2、进入到/hadoop目录下。
命令:cd /hadoop/

3、将config.conf、startAll.sh、stopAll.sh删除。
命令:rm -rf config.conf startAll.sh stopAll.sh

4、进入/tmp/Spark-stack/Hive/Automated scripts/目录下。
命令:cd /tmp/Spark-stack/Hive/Automated scripts/

5、将 startAll.sh、stopAll.sh、config.conf /hadoop/拷贝到/hadoop目录下。
命令:cp -r startAll.sh stopAll.sh config.conf /hadoop/
6、将cremoteSSH.exp 拷贝到/hadoop/tools/目录下。
命令:cp remoteSSH.exp /hadoop/tools/

7、进入/hadoop目录下。
命令:cd /hadoop/

8、赋予执行权限。
命令:chmod a+x *.sh

9、启动集群。
命令:./startAll.sh

安装Hive
将Hive安装到app-12上,减轻app-11的负载。
检查集群是否正常启动
1、在app-11上,以hadoop登录。
命令:su – hadoop注:所有的启停工作都在app-11上。

2、检查集群是否正常启动。
命令:jps

检查3306端口(MySQL端口)是否启动
3、在app-12上。
命令:netstat -tnl注:如果没有启动需要手动启动。

启动MySQL
4、在app-12的hadoopmysql中new terminal。

5、进入root用户下。
命令:sudo /bin/bash

6、启动mysql服务器。
命令:service mysql start

7、登录MySQL,查看是否正常启动。
命令:mysql -uroot -p 注:输入数据库密码,这里的默认密码是Yhf_1018。

下载安装包
8、在app-12上hadoopc2的new terminal,以hadoop用户登录。
命令:su – hadoop注:所有的启停工作都在app-11上。

9、进入hadoop目录下。
命令:cd /hadoop/

10、创建安装Hive的目录。
命令:mkdir Hive

11、进入到该目录下。
命令:cd Hive/

12、下载Hive安装包。
命令:wget https://archive.apache.org/dist/hive/hive-3.1.1/apache-hive-3.1.1-bin.tar.gz

13、解压安装包。
命令:tar -xf apache-hive-3.1.1-bin.tar.gz

更改模板配置文件
14、进入到安装目录下的配置文件。
命令:cd apache-hive-3.1.1-bin/conf/

15、删除hive-default.xml.template和hive-log4j2.properties.template模板文件。
命令:rm -r hive-log4j2.properties.template hive-default.xml.template

16、进入到/tmp/Spark-stack/Hive/conf/目录下。
命令:cd /tmp/Spark-stack/Hive/conf/

17、将修改后的配置文件拷贝到安装目录下的配置文件中。
命令:cp -r hive-log4j2.properties hive-site.xml /hadoop/Hive/apache-hive-3.1.1-bin/conf/

修改环境变量
18、返回安装目录。
命令:cd /hadoop/Hive/apache-hive-3.1.1-bin

19、创建tmp和log文件。
命令:mkdir {tmp,log}

20、将Hive的路径加到环境变量中。
命令:vi ~/.bashrc
export HIVE_HOME=/hadoop/Hive/apache-hive-3.1.1-bin
export PATH=${HIVE_HOME}/bin:$PATH

21、将环境变量生效。
命令:source ~/.bashrc

22、查看环境变量是否生效。
命令:echo $PATH

创建Metastore的database
23、返回mysql中new terminal,赋权限在任何客户端都可以登录,不受ip限制。
命令:GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'Yhf_1018' with grant option;

24、将权限生效。
命令:FLUSH privileges;

25、先删除Metastore的database,这里是没有的,为了多次使用安全的一个措施。
命令:drop database if exists hive;

26、创建Metastore的database。
命令:create database hive;

27、查看是否创建成功。
命令:show databases;

28、退出MySQL。
命令:quit

下载驱动
29、返回hadoopc2的new terminal上,将MySQL的驱动下载到安装目录的lib下,先进入到lib的目录下。
命令:cd lib/

30、下载驱动。
命令:wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.11/mysql-connector-java-8.0.11.jar

初始化Metastore
31、进入bin目录下。
命令:cd /hadoop/Hive/apache-hive-3.1.1-bin/bin

32、初始化Metastore。
命令:schematool -dbType mysql -initSchema

启动Hive service
33、启动Hive service。
命令:nohup ./hive --service metastore > /hadoop/Hive/apache-hive-3.1.1-bin/log/metastore.log 2>&1 &注:因为需要将service放到后台服务,所以使用nohup启动方式启动metastore服务,将所有的打印打印到log下

34、将hive进程显示出来。
命令:ps -ef | grep hive
35、启动hive。
命令:hive

36、查看databases。
命令:show databases;注:没有创建database。

37、按Ctrl+c退出命令行。

重启集群
38、在app-11上,进入/hadoop目录。
命令:cd /hadoop/

39、将安装完的信息export出去。
命令:vi config.conf

40、停止所有的集群。
命令:./stopAll.sh

41、登录其他两台机器查看集群。
命令:ssh hadoop@app-12 "jps"、ssh hadoop@app-13 "jps"

42、重启集群。
命令:./startAll.sh

43、查看集群启动。
命令:jps

44、查看其它机器上的集群。
命令:ssh hadoop@app-12 "jps"、ssh hadoop@app-13 "jps"

常见问题

问题原因:在lib目录下初始化一系列工作了。 问题解决:删除集群重新搭建。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

检查集群是否正常
1、在app-11上,以hadoop用户登录。
命令:su – hadoop

2、进入/hadoop/目录下。
命令:cd /hadoop/

3、检查集群是否正常。
命令:jps

操作
1、在app-12上,以hadoop用户登录。
命令:su – hadoop

2、查看Hive支持哪些命令。
命令:hive --help

3、查看环境变量里的hadoop配置。
命令:echo $HADOOP_HOME

4、启动客户端。
命令:hive 注:功能比较弱。不支持删除、自动补传等功能。

5、按Ctrl+c,退出。

6、不启用hive查询databases。
命令:hive -e "show databases"

7、使用静默参数,将结果输入文件中。
命令:hive -S -e "show databases" > /tmp/hai.txt

8、查看输出文件结果。
命令:cat /tmp/hai.txt

9、进入hive。
命令:hive --service cli

10、查看databases。
命令:show databases;

11、查看hdfs目录。
命令:dfs -ls / ;

12、退出。
命令:quit;

模拟hive启动失败
1、先删除HADOOP_HOME。
命令:unset HADOOP_HOME

2、查看环境变量。
命令:echo $HADOOP_HOME 注:因为删除了,所有空了。

3、删除Hadoop环境变量。
命令:export PATH=/hadoop/Hive/apache-hive-3.1.1-bin/bin:/hadoop/JDK/jdk1.8.0_131/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/hadoop/.local/bin:/home/hadoop/bin

4、启动hive客户端。
命令:hive --service cli 注:启动失败。
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

HiveQL数据定义
1、在app-12上,以hadoop用户登录。
命令:su – hadoop

2、启动hive。
命令:hive --service cli

3、查看databases。
命令:show databases;

手动创建databases
4、创建test。
命令:CREATE DATABASE IF NOT EXISTS test;

5、查看是否创建成功。
命令:show databases;

6、进入test。
命令:use test;

7、创建employee表。
命令:CREATE TABLE IF NOT EXISTS `EMPLOYEE` ( `ID` bigint, `NAME` string, CONSTRAINT `SYS_PK_BUCKETING_COLS` PRIMARY KEY (`ID`) DISABLE ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' ;
注:``这个符号为标识符,数据名字。

下载数据
8、新建new terminal,以hadoop用户登录。
命令:su – hadoop

9、进入/tmp目录下。
命令:cd /tmp/

10、创建hive文件。
命令:mkdir hive

11、进入 /tmp/Spark-stack/Hive/HiveQL/目录下。
命令:cd /tmp/Spark-stack/Hive/HiveQL/

12、将employee.dat 拷贝到/tmp/hive/目录下。
命令:cp employee.dat /tmp/hive/

8、返回之前的new terminal,加载数据到table中。
命令:LOAD DATA LOCAL INPATH '/tmp/hive/employee.dat' OVERWRITE INTO TABLE EMPLOYEE;

9、查询数据。
命令:select * from EMPLOYEE;

数据库与hdfs对应关系
观察创建完表和数据库之后,在HDFS上有什么变化
1、在app-11上,以hadoop用户登录。
命令:su – hadoop

2、配置文件默认的数据存储仓库在hive/warehouse/
命令:hdfs dfs -ls /user/hive/warehouse/

3、查看test.db文件
命令:hdfs dfs -ls /user/hive/warehouse/test.db

4、查看employee表。
命令:hdfs dfs -ls /user/hive/warehouse/test.db/employee

5、查看employee.dat数据集内容。
命令:hdfs dfs -cat /user/hive/warehouse/test.db/employee/employee.dat

内部表和外部表操作与hdfs文件管控
1、将数据拷贝到/installTest目录下。
命令:hdfs dfs -cp /user/hive/warehouse/test.db/employee/employee.dat /installTest

2、返回app-12的命令行,删除表。
命令:drop table employee;

3、返回app-11上,再次查看。
命令:hdfs dfs -ls /user/hive/warehouse/test.db注:数据已经删除了,但是test.db没有删除掉。

4、返回app-12上,删除test.db。
命令:drop database test;

5、返回app-11上,查看是否删除。
命令:hdfs dfs -ls /user/hive/warehouse/test.db注:已经删除,数据库已经被删除。

创建外部表
6、创建一个空目录存放数据。
命令:hdfs dfs -mkdir /installTest/hive

7、将拷贝过来的employee.dat拷贝到hive目录下。
命令:hdfs dfs -cp /installTest/employee.dat /installTest/hive

8、返回app-12上,创建表,先创建database。
命令:CREATE DATABASE IF NOT EXISTS test;

9、进入test。
命令:use test;

10、创建表。
命令:CREATE TABLE IF NOT EXISTS `EMPLOYEE` ( `ID` bigint, `NAME` string, CONSTRAINT `SYS_PK_BUCKETING_COLS` PRIMARY KEY (`ID`) DISABLE ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LOCATION '/installTest/hive';
注:外部表创建成功。

11、做一次查询。
命令:select * from EMPLOYEE; 注:内部表和外部表在其他操作上是一致的。

HiveQL查询
12、在app-12上退出命令行环境。
命令:quit;

13、进入tmp目录下。
命令:cd /tmp/

14、将hive文件删除重新创建存放临时数据。
命令:rm -rf hive/、mkdir hive

15、进入Spark-stack/Hive/目录下。
命令:cd Spark-stack/Hive/

16、将HiveQL目录下的文件拷贝到/tmp/hive/目录下。
命令:cp -rf HiveQL/* /tmp/hive/

17、进入/tmp/hive/目录下。
命令:cd /tmp/hive/

18、查看employee.sql脚本
命令:vi employee.sql 注:这是创建外部表的脚本。

19、加载脚本。
命令:hive -f /tmp/hive/employee.sql

20、切换到命令行环境。
命令:hive --service cli

21、进入test。
命令:use test;

22、设置MapReduce的Map memory和reduce memory为2G。
命令:set mapreduce.map.memory.mb=2048;、set mapreduce.reduce.memory.mb=2048;

23、查询。
命令:select count(*) from employee; 注:时间是4.38秒。

24、查询现在的执行引擎。
命令:set hive.execution.engine;

25、将执行引擎改为mr。
命令:set hive.execution.engine=mr;

26、再一次查询。
命令:select count(*) from employee;注:时间是10.55秒。

详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

1、在app-12上,用hadoop用户登录。
命令:su - hadoop

2、登录命令行。
命令:hive --service cli

3、进入test库。
命令:use test;

4、给employee上锁,并且是排他。
命令:lock table employee exclusive;

5、新建new terminal,进入zookeeper客户端。
命令:su – hadoop、zkCli.sh

6、查看zookeeper发生什么变化。
命令:ls /注:增加了hive_zookeeper_namespace节点。

7、查看hive_zookeeper_namespace节点。
命令:ls /hive_zookeeper_namespace

8、查看test节点。
命令:ls /hive_zookeeper_namespace/test

9、查看employee表。
命令:ls /hive_zookeeper_namespace/test/employee 注:生成了一个排他锁。

10、返回命令行,删除锁。
命令:unlock table employee;

11、在回到zookeeper查看表。
命令:ls /hive_zookeeper_namespace/test/employee注:已经不存在了。

12、返回命令行,对表再次上锁。
命令:lock table employee exclusive;

13、返回zookeeper,退出客户端。
命令:quit

14、登录hive命令行。
命令:hive --service cli

15、进入test。
命令:use test;

16、做查询。
命令:select * from employee; 注:光标一直在闪。

17、返回命令行,删除锁。
命令:unlock table employee;

18、返回,做查询。
命令:select * from employee; 注:光标还是在闪。

19、退出命令行,重新查询。
命令:按Ctrl+c、hive -e "use test;select * from employee"
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

深入理解Hive视频教程1
深入理解Hive视频教程2
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
Spark是什么
Spark是数据处理引擎,Hadoop的YARN是集群管理的组件,HDFS是数据存储的组件,MapReduce是数据处理的引擎。通常一套大数据解决方案包括了很多组件,有存储、计算、MapReduce、Spark等等。Spark做数据处理引擎,可以说是给你一个计算平台,承担上面的计算任务或者算法,由自己提供的,而在数据处理框架之上是需要一套分析软件,那么这套分析软件是根据业务特点去编程的。Spark是生态系统,Spark有数据处理引擎,同时在引擎之上做流处理,应用范围越来越广。Spark的突出特点是使用了内存运算和基于docker、基于计算图的方式去表述应用。
Spark是大一统的数据处理引擎

这幅图展示了Spark包括了的组件。Spark进入SQL,Datasets,DataFrames提供了结构化分析手段。Structured Streaming是处理流数据,关系型的查询就用SQL去处理流式数据。这两个包括了现在数据处理引擎的两个重要特点,第一个特点是处理结构化数据,将数据抽象成结构化数据。第二个特点是Structured流处理方式,流处理是实时大数据的一个核心理论。RDD是Spark发展初期一个重要的概念,弹性的数据集,进入这种数据集去构架Spark引擎,即将被其他的API所替代,比如Spark SQL,因为Spark SQL可以获得更高的性能。Spark Streaming也是Spark初期流处理的API框架,但是随着流处理理论的发展,这种API已经不适合现在流处理的发展了,Structured Streaming代替了Spark Streaming。MLlib是机器学习和GraphX是处理图。这些涵盖了大数据引擎的基本结构,批处理、流处理和图处理就是Spark是大一统的数据处理引擎的核心。
为什么不选择RDD
RDD是核心的但是是老的API,Flink的核心框架就是Datasets和DataFrames,所有的数据抽象成一个集合或者一个流。RDD这种弹性的数据集不能让使用者更理解内部机制或者更好的使用这个软件。所以说Spark选择将隐藏起来,而推出做流处理和批处理相应API的重要原因。无法判断是Flink学习了Spark还是Spark学习了Flink,我们得不出这个结论,但是,从现在大数据发展的理论上看,Dataset和DataStream这两种抽象是我们分析引擎的核心主流思想,都需要向着两个思想去融合,Spark也做到了这一点,这是为什么不选择RDD作为Spark主要API提供给用户的原因。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Spark是什么
Spark是数据处理引擎,Hadoop的YARN是集群管理的组件,HDFS是数据存储的组件,MapReduce是数据处理的引擎。通常一套大数据解决方案包括了很多组件,有存储、计算、MapReduce、Spark等等。Spark做数据处理引擎,可以说是给你一个计算平台,承担上面的计算任务或者算法,由自己提供的,而在数据处理框架之上是需要一套分析软件,那么这套分析软件是根据业务特点去编程的。Spark是生态系统,Spark有数据处理引擎,同时在引擎之上做流处理,应用范围越来越广。Spark的突出特点是使用了内存运算和基于docker、基于计算图的方式去表述应用。
Spark是大一统的数据处理引擎
这幅图展示了Spark包括了的组件。Spark进入SQL,Datasets,DataFrames提供了结构化分析手段。Structured Streaming是处理流数据,关系型的查询就用SQL去处理流式数据。这两个包括了现在数据处理引擎的两个重要特点,第一个特点是处理结构化数据,将数据抽象成结构化数据。第二个特点是Structured流处理方式,流处理是实时大数据的一个核心理论。RDD是Spark发展初期一个重要的概念,弹性的数据集,进入这种数据集去构架Spark引擎,即将被其他的API所替代,比如Spark SQL,因为Spark SQL可以获得更高的性能。Spark Streaming也是Spark初期流处理的API框架,但是随着流处理理论的发展,这种API已经不适合现在流处理的发展了,Structured Streaming代替了Spark Streaming。MLlib是机器学习和GraphX是处理图。这些涵盖了大数据引擎的基本结构,批处理、流处理和图处理就是Spark是大一统的数据处理引擎的核心。
为什么不选择RDD
RDD是核心的但是是老的API,Flink的核心框架就是Datasets和DataFrames,所有的数据抽象成一个集合或者一个流。RDD这种弹性的数据集不能让使用者更理解内部机制或者更好的使用这个软件。所以说Spark选择将隐藏起来,而推出做流处理和批处理相应API的重要原因。无法判断是Flink学习了Spark还是Spark学习了Flink,我们得不出这个结论,但是,从现在大数据发展的理论上看,Dataset和DataStream这两种抽象是我们分析引擎的核心主流思想,都需要向着两个思想去融合,Spark也做到了这一点,这是为什么不选择RDD作为Spark主要API提供给用户的原因。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
Spark编程模型与基本框架视频教程1
Spark编程模型与基本框架视频教程2
Spark编程模型与Spark基本架构

在程序上创建Spark Context,在上下文定义一系列的数据处理函数,加载数据的处理方式。在客户端有个Driver Application,调度编译程序执行,包括ActorSystem、Block Manager、BroadcastManager、TaskSchedule、DAGScheduler。用户通过SparkContext提供的API进行编写程序,会首先使用Block Manager和BroadcastManager将任务进行广播,广播的是任务的配置信息。然后由DAGScheduler将一个应用当成job,一个job有一个DAG组成,然后由ActorSystem去提交DAG给集群运行,然后,集群的管理器分配资源。Worker里面有个执行器,由执行器去执行任务。TaskScheduler调度Worker去执行。比如说MapReduce,被分解成一个个的Task,每个Task运行在某个容器上,Cluster Manager通过TaskScheduler执行Executor程序。
Spark基本框架

有很多个Driver因为要提交很多的app,客户端可以有多用户系统,客户端可以向Cluster Manager去提交任务,我们的任务不一定运行在Standalone端,可以在YARN、Mesos、EC2端,然后由Cluster Manager调度Executor去执行程序。
SparkContext

第一个是Python定义的Spark Context形式,第二个是Scala定义的,最后一个是java定义的,他们的定义形式是一样的,表现形式是不一样的。先设置一个conf在新建一个context。
任务调度

任务调度分为两部分,DAGScheduler和TaskScheduler。DAGScheduler负责将图划分为各个阶段,提交每个阶段。Spark底层仍然借助了MapReduce形式,因为在做大数据处理,Map和Reduce的思想目前还是无法超越的,ADG是有流程的。将TaskSet提交给TaskScheduler,和Cluster manager交互,TaskLaunch去申请Worker容器,容器里有执行器去执行每个任务,最后,将结果按照一定的各式存储。
部署模式

Spark的部署模式有多种,有Standalone,也就是自己有一个master,在我们的集群里,app-13是master,app-12和app-11是worker组成了一个主从的集群。
计算引擎

Tez是用Map和Reduce做逻辑的形式,然后做join,底层的机制仍然是MapReduce。Hive也是MapReduce,右边是通过解析执行计划,得到结果,仍然是进入MapReduce。因为Hive的底层是Tez,Tez也是通过MapReduce的。

Spark也是一样的,将userData和joined相当于是做Map,events相当于是reduce,在events中拉取数据。MapReduce目前来说是大数据最核心的、有力的思想,还没有过时。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

编译
编译的时候只创建一个机器即可,启动app-11,在编译的时候会占用大量的资源。
1、以hadoop用户登录。
命令:su – hadoop

2、切换到tmp根目录下。
命令:cd /tmp/

3、创建编译spark目录。
命令:mkdir spark

4、创建Maven仓库。
命令:mkdir -p /home/hadoop/.m2/repository/org/spark-project

5、进入spark目录下。
命令:cd spark/

6、下载编译安装包。
命令:wget https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0.tgz

7、解压。
命令:tar -xf spark-2.4.0.tgz

8、进入spark-2.4.0目录。
命令:cd spark-2.4.0

9、删除pom.xml文件。
命令:rm -rf pom.xml

10、切换到Spark的编译目录下。
命令:cd /tmp/Spark-stack/Spark/compile/

11、将pom_hive3.xml拷贝到spark解压之后的目录下。
命令:cp pom_hive3.xml /tmp/spark/spark-2.4.0 
12、将spark-project.zip解压到Maven库中。
命令:unzip /tmp/Spark-stack/Spark/compile/spark-project.zip -d /home/hadoop/.m2/repository/org/spark-project/

13、进入到spark安装目录下。
命令:cd /tmp/spark/spark-2.4.0

14、将pom_hive3.xml改名为pom.xml。
命令:mv pom_hive3.xml pom.xml

15、设置Maven的OPTS使用内存的设置。
命令:export MAVEN_OPTS="-Xmx3g -XX:ReservedCodeCacheSize=512m"

16、开始编译。
命令:./dev/make-distribution.sh --name hadoop3.1.2 --tgz -Phadoop-3.1 -Dhadoop.version=3.1.2 -Phive -Dhive.version=1.21.2.3.1.2.0-4 -Dhive.version.short=1.21.2.3.1.2.0-4 -Phive-thriftserver -Pyarn
注:时间会很长。

安装Spark
再创建另外两台机器,确保三台机器正常运行。
下载安装包
1、在app-11上进行三台机器的认证。
命令:sudo /bin/bash、cd /hadoop、 ./initHosts.sh

2、启动集群。
命令:su – hadoop、cd /hadoop/、./startAll.sh

3、检查启动集群。
命令:jps

4、创建安装Spark的目录。
命令:mkdir Spark

5、进入到编译之后的目录下。
命令:cd /tmp/spark/spark-2.4.0

6、将spark的安装包拷贝到Spark的安装目录下。
命令:cp spark-2.4.0-bin-hadoop3.1.2.tgz /hadoop/Spark/

7、进入到Spark安装目录下。
命令:cd /hadoop/Spark/

8、解压安装包。
命令:tar -xf spark-2.4.0-bin-hadoop3.1.2.tgz

9、进入Spark目录,下载配置文件。
命令:cd /tmp/Spark-stack/Spark/

10、拷贝基本配置文件。
命令:cp Bconf/* /hadoop/Spark/

11、返回Spark的安装目录下。
命令:cd /hadoop/Spark/

修改配置文件
12、进入解压之后的目录下。
命令:cd spark-2.4.0-bin-hadoop3.1.2

13、进入配置文件下。
命令:cd conf/

14、将下载下来的slaves文件拷贝到该目录下。
命令:cp /hadoop/Spark/slaves ./

15、将下载下来的spark-env.sh文件拷贝到该目录下。
命令:cp /hadoop/Spark/spark-env.sh ./

安装Scala
16、切到Spark的安装目录下。
命令:cd /hadoop/Spark/

17、下载Scala安装包。
命令:wget https://downloads.lightbend.com/scala/2.11.12/scala-2.11.12.tgz

18、返回hadoop目录。
命令:cd /hadoop/

19、创建安装Scala目录。
命令:mkdir Scala

20、将下载的Scala安装包拷贝到Scala目录下。
命令:tar -xf Spark/scala-2.11.12.tgz -C Scala/

21、给Scala赋予执行权限。
命令:chmod -R a+x /hadoop/Scala/scala-2.11.12/

修改环境变量
22、修改环境变量。
命令:vi ~/.bashrc
export SPARK_HOME=/hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2
export PATH=${SPARK_HOME}/bin:$PATH
export SCALA_HOME=/hadoop/Scala/scala-2.11.12
export PATH=${SCALA_HOME}/bin:$PATH

23、环境变量生效。
命令:source ~/.bashrc

24、检查环境变量生效。
命令:echo $PATH

清理工作
25、进入Spark安装目录下。
命令:cd Spark/

26、删除没用的文件。
命令:rm -rf scala-2.11.12.tgz slaves spark-2.4.0-bin-hadoop3.1.2.tgz spark-env.sh

27、将config.conf拷贝到hadoop的根目录下。
命令:mv config.conf /hadoop/

拷贝到集群的其他机器上
28、切换到hadoop的根目录下。
命令:cd /hadoop/

29、将环境变量拷贝到其他机器上。
命令:scp ~/.bashrc hadoop@app-12:/hadoop/
scp ~/.bashrc hadoop@app-13:/hadoop/

30、将Spark静默拷贝到其他机器上。
命令:for name in app-12 app-13; do scp -r -q Spark $name:/hadoop/; done

31、将Scala拷贝到其他机器上。
命令:for name in app-12 app-13; do scp -r -q Scala $name:/hadoop/; done

启动集群
32、进入Spark的安装目录下。
命令:cd /hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2/

33、启动集群。
命令:sbin/start-all.sh

34、检查集群。
命令:jps
注:Worker集群已经启动了。
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Spark集群模式

Spark集群模式Standalone,之前安装的配置模式就是Standalone,自己有集群,有一个master和三个work。这种集群是没有做HA的,因为想做HA可以集群的管理框架。
例子-Pyspark
1、以hadoop用户登录。
命令:su – hadoop

2、进入Spark的安装目录下。
命令:cd /hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2/

3、进入Python环境。
命令:bin/pyspark

4、查询。
命令:
from os.path import expanduser, join, abspath
from pyspark.sql import SparkSession
from pyspark.sql import Row
warehouse_location = abspath('/user/hive/warehouse')
spark = SparkSession.builder.appName("Python Spark SQL Hive integration example").config("spark.sql.warehouse.dir",warehouse_location).enableHiveSupport().getOrCreate()
spark.sql("SELECT * FROM test.employee").show()
注:查询失败,需要将hive的配置文件拷贝到Spark配置目录下。

5、退出命令行。
命令:quit()

6、进入到Spark的配置目录下。
命令:cd /hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2/conf/

7、将hive的配置文件拷贝到Spark配置目录下。
命令:scp app-12:/hadoop/Hive/apache-hive-3.1.1-bin/conf/hive-site.xml ./

8、将hive-site.xml拷贝到app-13上。
命令:scp hive-site.xml app-13:/hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2/conf/

9、切换到spark的根目录下。
命令:cd /hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2/

10、运行pyspark。
命令:bin/pyspark

11、select查询。
命令:spark = SparkSession.builder.appName("Python Spark SQL Hive integration example").config("spark.sql.warehouse.dir",warehouse_location).enableHiveSupport().getOrCreate()
spark.sql("SELECT * FROM test.employee").show()

12、count查询。
命令:spark.sql("SELECT COUNT(*) FROM test.employee").show()

13、退出命令行。
命令:quit()

Python脚本通过spark-submit提交yarn集群
如果没有做Pyspark例子,可以参考例子将hive的配置文件拷贝到整个集群的Spark配置目录下。
1、进入到Spark例子目录下。
命令:cd /tmp/Spark-stack/Spark/case/

2、将SparkHiveExample.py程序拷贝到Spark安装目录下。
命令:cp SparkHiveExample.py /hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2/

3、进入spark的安装目录下。
命令:cd /hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2/

4、将程序提交给yarn集群。
命令:./bin/spark-submit SparkHiveExample.py --master yarn --deploy-mode cluster --driver-memory 2g --executor-memory 1g --executor-cores 1 --queuedefault


Python-Scala版本
如果没有做Pyspark例子,可以参考例子将hive的配置文件拷贝到整个集群的Spark配置目录下。
1、进入命令行。
命令:bin/spark-shell
注:默认进入Scala编译环境。

2、交互性执行。
命令:
import java.io.File
import org.apache.spark.sql.{Row, SaveMode, SparkSession}
val warehouseLocation = new File("/user/hive/warehouse").getAbsolutePath
val spark = SparkSession.builder().appName("Spark Hive
Example").config("spark.sql.warehouse.dir",warehouseLocation).enableHiveSupport().getOrCreate()
import spark.implicits._
import spark.sql

3、select查询。
命令:sql("SELECT * FROM test.employee").show()

4、count查询。
命令:sql("SELECT COUNT(*) FROM test.employee").show()

5、停止spark。
命令:spark.stop()

6、退出命令行。
命令::quit

Spark-sql版本
如果没有做Pyspark例子,可以参考例子将hive的配置文件拷贝到整个集群的Spark配置目录下。
1、进入命令行。
命令:bin/spark-sql

2、查看databases。
命令:show databases;

3、进入test。
命令:use test;

4、查看tables。
命令:show tables;

5、select查询。
命令:select * from employee;

6、退出命令行。
命令:quit;

详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Oozie是解决工作流,特别是大数据处理工作流的任务框架。
工作流的必要性
第一点是在大数据处理中需要创建端到端的应用,经常处理一些定时、调度、shell脚本将流程化的节点串接在一起,如果使用传统的方式也就是脚本,但是效率比较底下,无法可视化的对脚本处理,以及相应的脚本的错误处理、通知、其他的监控通知无法做到自动化,而且不同的步骤之间的逻辑以及精细化的调度也很难做精细化的处理。所以说,我们需要在大数据工作流引擎,去支撑这种应用。 第二点如果自己做一些Spark脚本,需要通过一系列的提交,这个工作效率是非常低的。之所以为什么不模拟Spark客户端去提交信息,是因为数据处理任务仅仅是写一个处理函数,相关的步骤框架是通过Oozie满足的。这也是大数据工作引入的必须的条件。Oozie是针对大数据处理的调度器,还要适合于现有的大数据处理框架的功能。
Oozie基本概念

基本架构是Oozie客户端(命令行或REST接口)去提交job,给Oozie服务器,通过服务器中的调度器去调度job在Hadoop上执行,因此在Oozie上有一个做相应大数据的库。此外还有一个针对工作流引擎的数据库,存储工作流细节,这是关系型的数据库。 右侧是客户端提交任务的详细情况,客户端将job上传到HDFS上,集群上的所有节点能够通过HDFS下载job的详细信息,之后,job被提交到yarn集群上,MR,Hive,Pig,Java,Shell,Sqoop,SSH做支撑。
Oozie流程

详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Oozie是解决工作流,特别是大数据处理工作流的任务框架。
工作流的必要性
第一点是在大数据处理中需要创建端到端的应用,经常处理一些定时、调度、shell脚本将流程化的节点串接在一起,如果使用传统的方式也就是脚本,但是效率比较底下,无法可视化的对脚本处理,以及相应的脚本的错误处理、通知、其他的监控通知无法做到自动化,而且不同的步骤之间的逻辑以及精细化的调度也很难做精细化的处理。所以说,我们需要在大数据工作流引擎,去支撑这种应用。 第二点如果自己做一些Spark脚本,需要通过一系列的提交,这个工作效率是非常低的。之所以为什么不模拟Spark客户端去提交信息,是因为数据处理任务仅仅是写一个处理函数,相关的步骤框架是通过Oozie满足的。这也是大数据工作引入的必须的条件。Oozie是针对大数据处理的调度器,还要适合于现有的大数据处理框架的功能。
Oozie基本概念
基本架构是Oozie客户端(命令行或REST接口)去提交job,给Oozie服务器,通过服务器中的调度器去调度job在Hadoop上执行,因此在Oozie上有一个做相应大数据的库。此外还有一个针对工作流引擎的数据库,存储工作流细节,这是关系型的数据库。 右侧是客户端提交任务的详细情况,客户端将job上传到HDFS上,集群上的所有节点能够通过HDFS下载job的详细信息,之后,job被提交到yarn集群上,MR,Hive,Pig,Java,Shell,Sqoop,SSH做支撑。
Oozie流程
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
编译
编译需要占用很大的内存,只创建一个app-11即可。
1、以hadoop用户登录。
命令:su – hadoop

2、在tmp目录下创建Oozie编译文件。
命令:mkdir /tmp/oozie

3、进入tmp根目录下。
命令:cd /tmp/

4、下载Spark-stack。
命令:git clone https://github.com/haiye1018/Spark-stack.git

5、进入Spark-stack/Oozie/目录下。
命令:cd Spark-stack/Oozie/

6、将buildOozie目录下的文件拷贝到Oozie编译文件中。
命令:cp buildOozie/* /tmp/oozie/

7、进入Oozie编译目录下。
命令:cd /tmp/oozie/

8、下载Oozie编译包。
命令:wget https://archive.apache.org/dist/oozie/5.0.0/oozie-5.0.0.tar.gz

9、解压。
命令:tar -xf oozie-5.0.0.tar.gz

10、 命令:rm -rf oozie-5.0.0/pom.xml

11、将下载的pom.xml拷贝到oozie-5.0.0目录下。
命令:cp pom.xml oozie-5.0.0/

12、创建Maven仓库。
命令:
mkdir -p /home/hadoop/.m2/repository/org/apache/maven/doxia/doxia-core/1.0-alpha-9.2y
mkdir -p /home/hadoop/.m2/repository/org/apache/maven/doxia/doxia-module-twiki/1.0-alpha-9.2y

13、将doxia-module-twiki-1.0-alpha-9.2y.jar拷贝到相应的Maven仓库下。
命令:cp doxia-module-twiki-1.0-alpha-9.2y.jar /home/hadoop/.m2/repository/org/apache/maven/doxia/doxia-module-twiki/1.0-alpha-9.2y/

14、将doxia-core-1.0-alpha-9.2y.jar拷贝到相应的Maven仓库下。
命令:cp doxia-core-1.0-alpha-9.2y.jar /home/hadoop/.m2/repository/org/apache/maven/doxia/doxia-core/1.0-alpha-9.2y

15、进入oozie-5.0.0文件下。
命令:cd oozie-5.0.0

16、开始编译。
命令:bin/mkdistro.sh -DskipTests -Dtez.version=0.9.0 -Ptez -P'spark-2' -Puber 注:编译的时间会非常长。

17、有两个安装包,一个在/tmp/oozie/oozie-5.0.0/distro/target/目录下。
命令:cd /tmp/oozie/oozie-5.0.0/distro/target/

18、另一个在安装包在/tmp/oozie/oozie-5.0.0/sharelib/target/目录下。
命令:cd /tmp/oozie/oozie-5.0.0/sharelib/target/

制作sharelib
启动集群
1、创建app-12和app-13。

2、在app-11上以root用户登录。
命令:sudo /bin/bash

3、进入hadoop根目录下。
命令:cd /hadoop/

4、三台机器的认证。
命令:./initHosts.sh

5、以hadoop用户登录。
命令:su - hadoop

6、进入hadoop根目录下。
命令:cd /hadoop/

7、启动集群。
命令:./startAll.sh

创建hive库
8、创建Oozie的目录。
命令:mkdir /tmp/Oozie

9、将编译之后的两个安装包拷贝到该目录下。
命令:cp /tmp/oozie/oozie-5.0.0/sharelib/target/oozie-sharelib-5.0.0.tar.gz /tmp/Oozie/
cp /tmp/oozie/oozie-5.0.0/distro/target/oozie-5.0.0-distro.tar.gz /tmp/Oozie/

10、进入Oozie目录下。
命令:cd /tmp/Oozie/

11、解压oozie-sharelib-5.0.0.tar.gz。
命令:tar -xf oozie-sharelib-5.0.0.tar.gz

12、进入lib目录下。
命令:cd share/、cd lib/

13、删除hive。
命令:rm -rf hive

14、进入hive2目录下。
命令:cd hive2/

15、将oozie-sharelib-hive2-5.0.0.jar备份到上级目录中。
命令:mv oozie-sharelib-hive2-5.0.0.jar ..

16、返回上级目录。
命令:cd ..

17、删除hive2目录下的文件。
命令:rm -rf hive2/*

18、将备份出来的jar文件移回hive2。
命令:mv oozie-sharelib-hive2-5.0.0.jar hive2/

19、将hive的master中的所有jar包拷贝到hive2中。
命令:scp app-12:/hadoop/Hive/apache-hive-3.1.1-bin/lib/* hive2/

20、查看hive2。
命令:ls hive2/

创建Spark库
21、创建存放spark的文件。
命令:mkdir spark2

22、将spark目录下的oozie-sharelib-spark-5.0.0.jar拷贝到spark2中。
命令:cp spark/oozie-sharelib-spark-5.0.0.jar spark2

23、将Spark的jar包文件拷贝到spark2中。
命令:cp /hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2/jars/* spark2

24、删除spark目录。
命令:rm -rf spark

25、返回Oozie目录。
命令:cd /tmp/Oozie/

26、解压oozie-5.0.0-distro.tar.gz。
命令:tar -xf oozie-5.0.0-distro.tar.gz

27、进入oozie-5.0.0目录下。
命令:cd oozie-5.0.0

28、删除oozie-sharelib-5.0.0.tar.gz包。
命令:rm -rf oozie-sharelib-5.0.0.tar.gz

29、删除oozie-examples.tar.gz包。
命令:rm -rf oozie-examples.tar.gz

30、将api-util-1.0.0-M20.jar拷贝到spark2中。
命令:cp embedded-oozie-server/webapp/WEB-INF/lib/api-util-1.0.0-M20.jar /tmp/Oozie/share/lib/spark2/ 注:如果不拷贝在操作中会出现问题。

31、为了支持pyspark,需要交pyspark相关的库拷贝到spark2中。
命令:cp /hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2/python/lib/*.zip /tmp/Oozie/share/lib/spark2/
32、返回上层目录。
命令:cd ..

33、删除原来的压缩文件。
命令:rm -rf *.gz

34、打包文件。
命令:tar -czf oozie-sharelib-5.0.0.tar.gz share/、tar -czf oozie-5.0.0-distro.tar.gz oozie-5.0.0/

安装client和server
在app-11上安装server,server包含了client。可以安装多个client,在app-12和app-13上都可以安装client,但是server只有一个,在app-11上。
下载库
1、在集群的根目录下创建安装Oozie的目录。
命令:mkdir /hadoop/Oozie 
2、确保hadoop的配置文件内容齐全。
命令:vi /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/core-site.xml
注:如果没有需要手动添加,添加之后重启集群。


3、进入Oozie的安装目录下。
命令:cd /hadoop/Oozie/

4、将oozie-5.0.0-distro.tar.gz解压到Oozie安装目录下。
命令:tar -xf /tmp/Oozie/oozie-5.0.0-distro.tar.gz

5、进入解压之后的目录下。
命令:cd oozie-5.0.0/

6、创建web的库。
命令:mkdir libext

7、进入到libext目录下。
命令:cd libext/

8、下载mysql连接器。
命令:wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.11/mysql-connector-java-8.0.11.jar

9、下载java Spring 库。
命令:wget http://archive.cloudera.com/gplextras/misc/ext-2.2.zip

修改配置文件
10、进入配置文件。
命令:cd /hadoop/Oozie/oozie-5.0.0/conf/

11、删除oozie-site.xml文件。
命令:rm -rf oozie-site.xml

12、将修改好的配置文件拷贝过来。
命令:cp /tmp/Spark-stack/Oozie/conf/oozie-site.xml ./

13、进入hadoop-conf目录下。
命令:cd hadoop-conf

14、删除hadoop-conf下所有文件。
命令:rm -rf *

15、拷贝hadoop的相应配置文件。
命令:
cp /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/core-site.xml ./
cp /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/hdfs-site.xml ./
cp /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/yarn-site.xml ./
cp /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/mapred-site.xml ./

配置mysql
1、在app-12上,选择hadoopmysql下的new terminal。

2、启动mysql。
命令:mysql -uroot -p

3、创建databases。
命令:create database oozie;

4、创建用户。
命令:create user "oozie"@"%" identified by "Yhf_1018";

5、给用户赋权限。
命令:grant all privileges on oozie.* to "oozie"@"%" with grant option;

6、flush配置。
命令:flush privileges;

7、退出mysql。
命令:quit;

Sharelib的制作和Oozie启动
1、在app-11上,进入安装Oozie的目录下。
命令:cd /hadoop/Oozie/oozie-5.0.0/

2、创建sharelib。
命令:bin/oozie-setup.sh sharelib create -fs hdfs://dmcluster -locallib /tmp/Oozie/oozie-sharelib-5.0.0.tar.gz
注:将share上传到hdfs。提交信息的时候在/user/hadoop/share/lib/lib_20201105132658位置寻找版本信息sharelib。

3、查看sharelib。
命令:hdfs dfs -ls /user/hadoop/share/lib/lib_20201105132658

4、将mysql-connector-java-8.0.11.jar拷贝到lib目录下。
命令:cp libext/mysql-connector-java-8.0.11.jar lib/

5、初始化databases。
命令:bin/oozie-setup.sh db create -run
注:进行了创建和验证并且生成了一个sql文件。

6、启动Oozie。
命令:bin/oozie-start.sh

7、查看11000端口(Oozie对外访问的端口号)是否启动。
命令:netstat -tnl
注:不要着急查看等待30秒。

8、登录端口号查看。
使用内部的Chrome,输入:app-11:11000 注:现在还没有Oozie任务所以是空的。



9、检验系统里用的是哪个sharelib。
命令:bin/oozie admin -shareliblist

设置自动化启停脚本
1、打开hadoop的config加上Oozie。
命令:vi /hadoop/config.conf export OOZIE_IS_INSTALL=True

2、source环境变量。
命令:source ~/.bashrc

3、确认start.all脚本有Oozie。
命令:vi /hadoop/startAll.sh
注:Oozie在最后,因为它依赖hadoop和Spark。

4、下载Oozie启停脚本。
命令:cp /tmp/Spark-stack/Oozie/sh/* /hadoop/tools/

5、进入hadoo的tools目录下。
命令:cd /hadoop/tools/

6、赋予执行权限。
命令:chmod -R a+x *Oozie*

详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Cron Action

Cron Action是定时方法。Oozie的Cron Action有自己的EL表达式。

job.properties是Oozie运行的本地文件。 workflow是工作流的定义文件。 coordinator是Oozie自带的定时配置文件。
coordinator

配置name,定时的frequency每十分钟执行一次,起点和结束时间,时区是UTC。
workflow

开始时间是2019-01-01T00:00Z,结束时间是2020-01-01T01:00Z。定义的信息传递给coordinator。
操作
上传程序到hdfs上
1、在app-11上,以hadoop用户登录。
命令:su – hadoop

2、进入tmp根目录。
命令:cd /tmp/

3、创建下载oozie案例的目录。
命令:mkdir oozie-example

4、下载案例程序。
命令:cp -R Spark-stack/Oozie/case/* oozie-example/
注:这里拷贝的不只cron,是将所有的案例都拷贝了过来。

5、进入Oozie的安装目录。
命令:cd /hadoop/Oozie/oozie-5.0.0/

6、在hdfs上创建上传程序的目录。
命令:hdfs dfs -mkdir -p /user/hadoop/cron-schedule-example/apps/cron-schedule

7、上传程序到hdfs。
命令:hdfs dfs -put /tmp/oozie-example/cron-schedule-example/apps/cron-schedule/* /user/hadoop/cron-schedule-example/apps/cron-schedule

8、查看是否上传成功。
命令:hdfs dfs -ls /user/hadoop/cron-schedule-example/apps/cron-schedule

执行提交
9、先登录Oozie的server。网址:app-11:11000



10、任务提交。
命令:bin/oozie job -oozie http://app-11:11000/oozie -config /tmp/oozie-example/cron-schedule-example/apps/cron-schedule/job.properties -run

11、刷新Oozie的服务器。因为是定时的,每隔一段时会触发一个job。原始的job在Coordinator Jobs中。触发的job在Workflow Jobs中。任务是一直进行的,不会结束,需要人为结束。


12、结束任务。
命令:bin/oozie job -oozie http://app-11:11000/oozie -info 0000000-201105134017865-oozie-hado-C

13、删除任务。
命令:bin/oozie job -oozie http://app-11:11000/oozie -kill 0000000-201105134017865-oozie-hado-C

14、再刷新Oozie服务器。

ShellAction
demo

这是输出结果。当前的PATH路径和echo my_output=Hello Oozie。
操作
1、在app-11上以hadoop用户登录。
命令:su – hadoop

2、在hdfs上创建上传程序的目录。
命令:hdfs dfs -mkdir -p /user/hadoop/shell-example/apps/shell

3、上传程序到hdfs上。
命令:hdfs dfs -put /tmp/oozie-example/shell-example/apps/shell/* /user/hadoop/shell-example/apps/shell

4、查看是否上传成功。
命令:hdfs dfs -ls /user/hadoop/shell-example/apps/shell

5、进入Oozie的安装目录下。
命令:cd /hadoop/Oozie/oozie-5.0.0/

6、提交任务。
命令:bin/oozie job -oozie http://app-11:11000/oozie -config /tmp/oozie-example/shell-example/apps/shell/job.properties -run

7、登录Oozie的服务器。



8、执行完成之后打开Workflow中的All Jobs

9、打开第一个任务。

10、点击Job DAG。

这是整个的流程图,其中绿色的部分是这个任务在执行的流程。
11、登录app-12:8088。这是shell的执行任务。

12、点击任务。

13、找到logs点选择。

14、点击stdout。

15、再点here。这是执行任务的过程,和打印的classpath。最后是输出的结果。


MapReduce-例子
job.properties

做MapReduce需要输出MapReduce,所以结果输出Dir。
workflow.xml

MapReduce的流程。
操作
1、以hadoop用户登录。
命令:su – hadoop

2、拷贝相关的job定义。
命令:hdfs dfs -copyFromLocal /tmp/oozie-example/mapreduce-example/ /user/hadoop/

3、查看是否拷贝成功。
命令:hdfs dfs -ls /user/hadoop

4、创建存放输出结果的目录。
命令:hdfs dfs -mkdir /user/hadoop/mapreduce-example/input-data

5、进入Oozie的安装目录下。
命令:cd /hadoop/Oozie/oozie-5.0.0/

6、提交集群执行MapReduce。
命令: bin/oozie job -oozie http://app-11:11000/oozie -config /tmp/oozie-example/mapreduce-example/apps/map-reduce/job\(1\).properties -run

7、登录Oozie的服务器。网址:app-11:11000。



8、查看执行结果的位置。
命令:hdfs dfs -ls /user/hadoop/mapreduce-example/output-data/map-reduce

9、查看执行结果。
命令:hdfs dfs -cat /user/hadoop/mapreduce-example/output-data/map-reduce/part-00000
 打印的程序语句的行号。
打印的程序语句的行号。
Hive-例子
job.properties

通过jdbcURL访问hive2中的test库,提供了便捷的方式。
操作
1、在app-12上,以hadoop用户登录。
命令:su – hadoop

2、确保10000端口启动。
命令:netstat -tnl

3、在app-11上,以hadoop用户登录。
命令:su – hadoop

4、进入Oozie安装的目录。
命令:cd /hadoop/Oozie/oozie-5.0.0/

5、上传相关的文件。
命令:hdfs dfs -copyFromLocal /tmp/oozie-example/hive2-example /user/hadoop/

6、检查是否上传成功。
命令:hdfs dfs -ls /user/hadoop/

7、提交程序。
命令:bin/oozie job -oozie http://app-11:11000/oozie -config /tmp/oozie-example/hive2-example/apps/hive2/job.properties -run

8、登录hadoop集群。

9、查看打印结果。结果在Launcher中。结果有12行。

Spark-例子
job.properties

在做sharelib时,我们将spark的目录删除了,所以也可以不指代。这里指代是为了应对多个版本时可以更明确lib的版本,这样就可以在一个版本的集群上执行多个版本的程序。
操作
1、以hadoop用户登录。
命令:su - hadoop

2、进入Oozie的安装目录下。
命令:cd /hadoop/Oozie/oozie-5.0.0/

3、拷贝相应的文件到HDFS上。
命令:hdfs dfs -copyFromLocal /tmp/oozie-example/spark-example/ /user/hadoop/

4、查看是否拷贝成功。
命令:hdfs dfs -ls /user/hadoop/

5、执行。
命令:bin/oozie job -oozie http://app-11:11000/oozie -config /tmp/oozie-example/spark-example/apps/spark/job.properties -run

6、登录Oozie服务器。



7、登录app-12:8088。

因为hadoop是执行方,所以执行的是最快的。而Oozieserver需要有一个回调,hadoop通过回调将状态信息反馈给Oozieserver,所以Oozie稍微缓慢点。
8、查看SparkPi的执行结果。执行结果就是:Pi is roughly 3.1423357116785584.



pyspark-例子
pi.py

这是spark做π计算的程序,使用蒙的卡罗计算方式计算的π。
job.properties

定义Python执行命令的位置,在集群上所有的机器上安装anaconda。
操作
1、以hadoop用户登录。
命令:su - hadoop

2、进入Oozie的安装目录下。
命令:cd /hadoop/Oozie/oozie-5.0.0/

3、将相应的文件拷贝到hdfs上。
命令:hdfs dfs -copyFromLocal /tmp/oozie-example/spark-example-pi/ /user/hadoop/

4、查看是否拷贝成功。
命令:hdfs dfs -ls /user/hadoop/

5、提交程序。
命令:bin/oozie job -oozie http://app-11:11000/oozie -config /tmp/oozie-example/spark-example-pi/apps/pyspark/job.properties -run

6、登录hadoop集群。

7、查看Spark-Pi的结果。

详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

淘宝用户行为分析案例

通过用户的注册、登录、浏览、加车和购买这一系列的数据,去分析这个网站的PV、UV以及各种转化率,浏览之后是否产生购买行为和加购物车之后是否产生购买行为然后通过这种的行为分析,去发掘两个特点,第一个是向什么样的用户去推荐什么样的新的商品,什么样的商品会承载可能的问题,比如说这样的商品需要下架,转化率和复购率不好。
数据源

从淘宝的天池下载数据源,网址是:数据下载地址: https://tianchi.aliyun.com/dataset/dataDetail?dataId=46,需要自己的账号去下载。是淘宝内部的资源,有12256906条记录,这是淘宝初期发展的数据,当时的规模还是比较小的,这个数据集有30天的数据。此外,里面包括了淘宝当时双12的活动,通过双12和平时的对比,可以直观的看到活动对互联网平台产生的流量影响。

时间戳是到小时,在数据分析中需要加载数据分析逻辑,因为没有分和秒所以无法排序。一个小时之内用户可能做很多动作,很多动作无法在时间上进行排序。可以用行去排序,生成的行是谁先发生谁在前,但是我们不做这个假定。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

淘宝用户行为分析案例
通过用户的注册、登录、浏览、加车和购买这一系列的数据,去分析这个网站的PV、UV以及各种转化率,浏览之后是否产生购买行为和加购物车之后是否产生购买行为然后通过这种的行为分析,去发掘两个特点,第一个是向什么样的用户去推荐什么样的新的商品,什么样的商品会承载可能的问题,比如说这样的商品需要下架,转化率和复购率不好。
数据源
从淘宝的天池下载数据源,网址是:数据下载地址: https://tianchi.aliyun.com/dataset/dataDetail?dataId=46,需要自己的账号去下载。是淘宝内部的资源,有12256906条记录,这是淘宝初期发展的数据,当时的规模还是比较小的,这个数据集有30天的数据。此外,里面包括了淘宝当时双12的活动,通过双12和平时的对比,可以直观的看到活动对互联网平台产生的流量影响。
时间戳是到小时,在数据分析中需要加载数据分析逻辑,因为没有分和秒所以无法排序。一个小时之内用户可能做很多动作,很多动作无法在时间上进行排序。可以用行去排序,生成的行是谁先发生谁在前,但是我们不做这个假定。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
本案例可以使用最新的集群环境: BigDataWithLoadedDataC1/C2/C3集群环境
Jupyter Spark调度模式

惰性求值与缓存

Spark求值相当于是转换的操作,这时的转换操作没有求值执行。只有有行动操作的时候,转化操作才会实实在在的执行,这时符合进入DAG进行大数据处理的模式。cache是缓存数据,下次执行sqlDF时不再执行查询操作,这时的cache并没有求值,只有在使用的时候才会求值。
Apache Arrow

上传程序
1、在app-11上,右侧打开Jupyter。

2、输入密码。Yhf_1018


3、上传程序,程序在GitHub中,可自行下载。一下是这次课程涉及到的程序文件及存放目录。




4、上传程序文件。点击Upload本地上传。

用户访问流量分布分析
day
代码讲解

创建Spark Session,定义Spark Session,Spark master是app-13提交的端口是7077。 读取CSV模式的文件,跳过header。Format是日期的方式,加载数据信息。创建视图,在视图之上就可以加载SQL语句。需要注意的是,这里没有使用SQL语句执行,直接在Spark中读取对应文件。

启用Apache Arrow。

按天查询流量信息,从taobai,taobai是之前创建的视图,对象都是spark,根据date排序。cache是将查询数据缓存。

创建View,使用SQL的方式出处理sqlDF2。

对数据类型转换,之所以将create_day转换为string,是因为Apache Arrow不支持create_day类型。

将sqlDF转为Pandas所识别的数据类型。创建完Pandas之后就可以画图了。

将sqlDF画成图,create_day为x轴,需要设定x轴时间的各式。将x轴的数据转成45°的角。
操作
1、在后台启动Jupyter打印。
命令:tailf /tmp/jupyter.log
注:这里可以查看Jupyter运行的过程。

2、点击运行,一步一步的进行,等上一步结束在进行下一步。

3、运行。

释放资源
每次做完运行都需要进行一次释放资源的操作。
1、返回Jupyter首页。

2、查看Running。

3、关闭pageViewByDate程序。


Hour
1、上传程序文件。

2、一步步运行。

3、释放资源。

客单量分析
这个指标反映了客户的购买能力。
1、上传程序。

2、运行,逐步运行。

3、释放资源。

代码解释

购买的数/用户的数=客单量。
商品分析
商品PV各环节转化率

点击转化收藏率为多少,然后由收藏转化为购物车,最后由购物车转化购买有多少。还可以有点击率转化为购买的转化率。
代码解释

统计商品的种类,有8916种。

计算有多少商品。

统计商品和商品成功购买的数量,根据数据统计量进行排序。这里只显示了前20行,商品id为303205878的购买数量是最多的,被购买了50次。这并不能说明什么,这50次可能是一个人一次购买了50个,也可能是30天中平均一天2次的购买量。现在还没有说服力。

SQL查询。

查询每个商品做pv,fav,cart,buy这一系列动作,然后通过这个数据在去统计相关的量。

查询做相关动作的数量。

保存DF。

将行变列,将对应的商品id,输出多个列,每一列是相应的pv,fav,cart,buy的数量。 保存缓存。null是没有对应的数量。

清理缓存。
Ratio
1、上传程序文件。

2、运行。


3、资源释放。

4、退出Jupyter后台,按Ctrl+C。
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

本案例可以使用最新的集群环境: BigDataWithLoadedDataC1/C2/C3集群环境
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
HBase的应用场景及特点
HBase能做什么

对于HBase有两个方面,第一个方面是海量的数据存储,数据的读和写,还有数据的查询。一般HBase的数据存储量是上百亿行乘以上百万的列,也就是一个表里可以包含上百亿行和上百万的列。在关系型数据表里面,列的设计不会超过30个,如果超过30个就说明这个表的设计是有问题的,而对于HBase而言列就没有上限。第二个方面就是准实时查询,HBase基于上百亿行和上百万列的数据量基础上能够通过百毫秒的时长准确的查询。 在所有的业务之中是不是可以将所有的数据都可以放入HBase里面去呢?答案是肯定可以的。那么是不是都适合存在HBase里面去呢?HBase只针对海量数据的存储,只有当这个表里的非常大的时候,才能充分发挥HBase的特点,如果说是上万行、上百行的数据,那么就没有必要往HBase里面放了,我们普通的关系型数据库就可以解决这个问题。当然,相对于普通的关系型数据库HBase还是有很多的优势。
举例说明HBase在实际业务中的应用

首先第一个是交通,比如船舶的信息,船舶的信息中包含JPS的信息,把JPS的信息放到HBase数据库里面,因为JPS的信息量是非常大的,当然相比于路面上的汽车JPS信息是小的。我们为什么将船舶的信息放到HBase里面呢,是为了方便后期做数据的分析,比如说,长江的那一段的流量是非常大的,还可以通过数据分析,那些是社会船舶,那些是商会船舶等等。通过这些分析可以为航道的建设做一些辅助的帮助。 第二个就是金融,这个金融也是很好理解的,跟我们的生活也是息息相关的,特别是我们现在支付非常方便的时代中,当我们发生一笔交易的时,这些数据就可以存放到HBase中。我们的交易信息,包含了取款信息、贷款信息、消费信息、还款信息等等。只要是和我们的 银行金融系统发生交易的这些信息,都会被金融系统保留下来。 第三个就是电商,这个电商的大家就更好理解了,很多人都喜欢用淘宝 、京东,这些信息也会保留下来。比如交易信息、物流信息、个人日志上的浏览信息等等,这些信息的量非常的大,我们都可以选择放到HBase里面去。 最后一个是移动,也就是我们的电话信息。包括我们的短息和通话信息,每天还是很多的,这些都是可以放到HBase里面去的。 这就是我们现实中,比较大的应用场景基于HBase的。当然还是有很多其他的方面,当信息量非常大的时候,也是考虑HBase的。
HBase的特点
第一个就是海量数据的存储,HBase单表可以有上百亿行和上百万列的存储,这个量的存储可以通过对比关系型数据库存储的量,一般关系型数据库存储单表行是不超过五百万的,如果超过五百万是要做封表和封库的操作,列是不超过30的,如果超过30列这个表的设计是不合理的。 第二个是面向列的数据,HBase是面向列的存储和权限控制,并支持独立检索。列式存储,其中数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,能大大减少读取的数据量。 第三个是多版本,HBase每一个列的数据存储有多个Version。 第四个是稀疏性,为空的列兵不占用存储空间,表可以设计的非常稀疏。 第五个是扩展性,底层依赖于HDFS。 第六个是高可靠性,WAL机制保证了数据写入使不会因集群异常而导致写入数据丢失;Replication机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且HBase底层使用HDFS,HDFS本身也有备份。 第七个是高性能,底层的LSM数据结古和Rowkey有序排列等架构上的独特设计,使得HBase具有非常高的写入性能。region切分、主键索引和缓存机制使得HBase在海量数据下具备一定的随机读取性能,该性能针对Rowkey的查询能够到达毫秒级别。 HBase的概念和定位
认识HBase在Hadoop2.x生态系统中的定位

在Hadoop生态系统中HBase主要做数据的存储,也是唯一的。是基于HDFS的。
HBase架构体系

HBase有两个主要的进程,RegionServer和Master,HBase还依赖于两个外部服务HDFS和ZooKeeper。RegionServer是管理表里的数据,也就是当一个表的数据量非常的时候,做一个分区,一个区就是对应一个region,每个region管理自己的数据。RegionServer实时的去报告我们的Master,RegionServer有一个自己的健康状态信息和RegionServer管理那些数据,要让Master实时知道。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

HBase的应用场景及特点
HBase能做什么
对于HBase有两个方面,第一个方面是海量的数据存储,数据的读和写,还有数据的查询。一般HBase的数据存储量是上百亿行乘以上百万的列,也就是一个表里可以包含上百亿行和上百万的列。在关系型数据表里面,列的设计不会超过30个,如果超过30个就说明这个表的设计是有问题的,而对于HBase而言列就没有上限。第二个方面就是准实时查询,HBase基于上百亿行和上百万列的数据量基础上能够通过百毫秒的时长准确的查询。 在所有的业务之中是不是可以将所有的数据都可以放入HBase里面去呢?答案是肯定可以的。那么是不是都适合存在HBase里面去呢?HBase只针对海量数据的存储,只有当这个表里的非常大的时候,才能充分发挥HBase的特点,如果说是上万行、上百行的数据,那么就没有必要往HBase里面放了,我们普通的关系型数据库就可以解决这个问题。当然,相对于普通的关系型数据库HBase还是有很多的优势。
举例说明HBase在实际业务中的应用
首先第一个是交通,比如船舶的信息,船舶的信息中包含JPS的信息,把JPS的信息放到HBase数据库里面,因为JPS的信息量是非常大的,当然相比于路面上的汽车JPS信息是小的。我们为什么将船舶的信息放到HBase里面呢,是为了方便后期做数据的分析,比如说,长江的那一段的流量是非常大的,还可以通过数据分析,那些是社会船舶,那些是商会船舶等等。通过这些分析可以为航道的建设做一些辅助的帮助。 第二个就是金融,这个金融也是很好理解的,跟我们的生活也是息息相关的,特别是我们现在支付非常方便的时代中,当我们发生一笔交易的时,这些数据就可以存放到HBase中。我们的交易信息,包含了取款信息、贷款信息、消费信息、还款信息等等。只要是和我们的 银行金融系统发生交易的这些信息,都会被金融系统保留下来。 第三个就是电商,这个电商的大家就更好理解了,很多人都喜欢用淘宝 、京东,这些信息也会保留下来。比如交易信息、物流信息、个人日志上的浏览信息等等,这些信息的量非常的大,我们都可以选择放到HBase里面去。 最后一个是移动,也就是我们的电话信息。包括我们的短息和通话信息,每天还是很多的,这些都是可以放到HBase里面去的。 这就是我们现实中,比较大的应用场景基于HBase的。当然还是有很多其他的方面,当信息量非常大的时候,也是考虑HBase的。
HBase的特点
第一个就是海量数据的存储,HBase单表可以有上百亿行和上百万列的存储,这个量的存储可以通过对比关系型数据库存储的量,一般关系型数据库存储单表行是不超过五百万的,如果超过五百万是要做封表和封库的操作,列是不超过30的,如果超过30列这个表的设计是不合理的。 第二个是面向列的数据,HBase是面向列的存储和权限控制,并支持独立检索。列式存储,其中数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,能大大减少读取的数据量。 第三个是多版本,HBase每一个列的数据存储有多个Version。 第四个是稀疏性,为空的列兵不占用存储空间,表可以设计的非常稀疏。 第五个是扩展性,底层依赖于HDFS。 第六个是高可靠性,WAL机制保证了数据写入使不会因集群异常而导致写入数据丢失;Replication机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且HBase底层使用HDFS,HDFS本身也有备份。 第七个是高性能,底层的LSM数据结古和Rowkey有序排列等架构上的独特设计,使得HBase具有非常高的写入性能。region切分、主键索引和缓存机制使得HBase在海量数据下具备一定的随机读取性能,该性能针对Rowkey的查询能够到达毫秒级别。 HBase的概念和定位
认识HBase在Hadoop2.x生态系统中的定位
在Hadoop生态系统中HBase主要做数据的存储,也是唯一的。是基于HDFS的。
HBase架构体系
HBase有两个主要的进程,RegionServer和Master,HBase还依赖于两个外部服务HDFS和ZooKeeper。RegionServer是管理表里的数据,也就是当一个表的数据量非常的时候,做一个分区,一个区就是对应一个region,每个region管理自己的数据。RegionServer实时的去报告我们的Master,RegionServer有一个自己的健康状态信息和RegionServer管理那些数据,要让Master实时知道。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
修改配置文件
修改hbase-env.sh
更改前:

将# export HBASE_MANAGES_ZK=true改为export HBASE_MANAGES_ZK=false
表示启动HBase时不启动zookeeper,用户单独启动zookeeper。
更改后:

修改hbase-site.xml
更改前:

在hbase-site.xml中添加
<property>
<name>hbase.rootdir</name>
<value>hdfs://dmcluster/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>app-11,app-12,app-13</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/hadoop/HBase/hbase-2.2.0/zookeeper</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
```
更改后:

## 修改regionservers
更改前:

在regionservers中添加app-11
app-12
app-13
更改后:

## 添加backup-masters文件
文件中只写app-13

# 安装HBase
## 下载HBase安装包
1、以root用户登录
命令:```sudo /bin/bash```

2、创建HBase目录
命令:```mkdir /hadoop/HBase```

3、将HBase目录下的所有目录改为hadoop所有
命令:```chown hadoop:hadoop /hadoop/HBase```

4、以hadoop用户登录
命令:```su - hadoop```

5、进入HBase安装目录
命令:```cd /hadoop/HBase/```

6、下载HBase安装包
命令:```wget http://archive.apache.org/dist/hbase/2.2.0/hbase-2.2.0-bin.tar.gz```
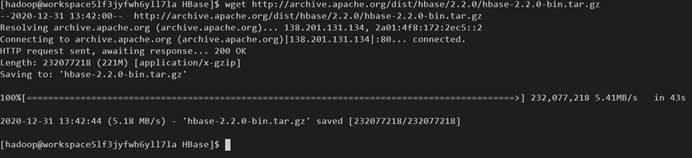
7、解压安装包
命令:```tar -xzf hbase-2.2.0-bin.tar.gz```

## 修改配置文件
8、进入到配置文件下
命令:```cd hbase-2.2.0/conf/```

9、删除需要修改的配置文件
命令:```rm -rf hbase-env.sh hbase-site.xml regionservers```

10、将/tmp/Spark-stack/HBase/conf目录下修改好的配置文件拷贝到配置文件中
命令:```cp /tmp/Spark-stack/HBase/conf/* ./```

## 修改环境变量
11、打开环境变量
命令:```vi ~/.bashrc```
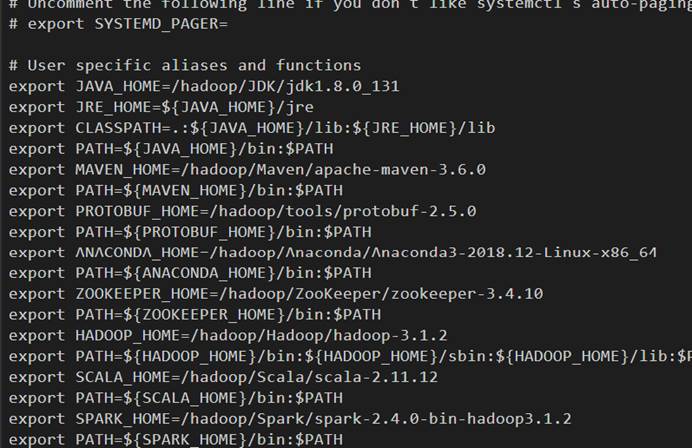
12、添加```export HBASE_HOME=/hadoop/HBase/hbase-2.2.0
export PATH=${HBASE_HOME}/bin:$PATH```
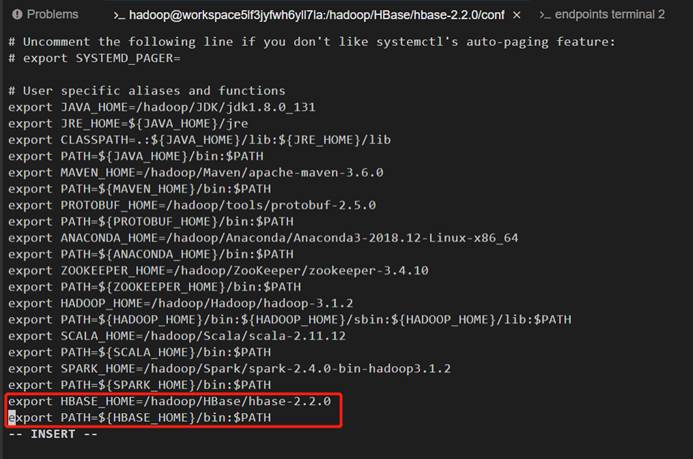
13、使环境变量生效
命令:```source ~/.bashrc```
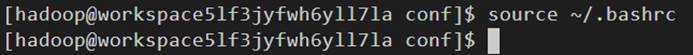
14、查看环境变量是否生效
命令:```echo $PATH```

## 在其他的两个机器上安装HBase
15、在app-12和app-13上先创建安装HBase的目录
命令:```ssh hadoop@app-12 "mkdir /hadoop/HBase"```、```ssh hadoop@app-13 "mkdir /hadoop/HBase"```

16、将HBsae拷贝到app-12和app-13上
命令:```scp -r -q /hadoop/HBase/hbase-2.2.0 hadoop@app-12:/hadoop/HBase/```、```scp -r -q /hadoop/HBase/hbase-2.2.0 hadoop@app-13:/hadoop/HBase/```

17、将环境变量也拷贝到app-12和app-13上
命令:```scp ~/.bashrc hadoop@app-12:~/```、```scp ~/.bashrc hadoop@app-13:~/```

## 清除工作(清除第一次安装失败之后删除不干净的文件)
18、清除hdfs中hbase目录,不存在则不需要清除
命令:```hdfs dfs -rm -r -f /hbase```

19、清除zookeeper中hbase节点,否则可能出现Master is initializing之类错误
命令:```echo 'rmr /hbase' | zkCli.sh```
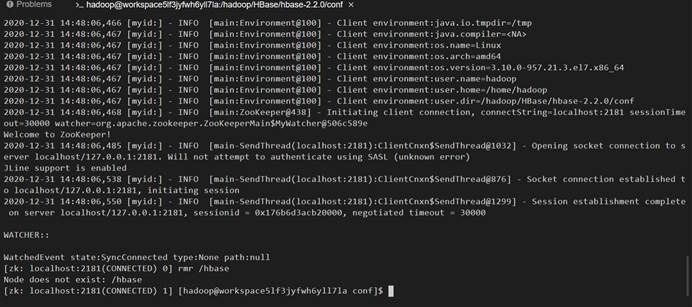
20、在app-12上启动HBase,因为app-12是HBASE_MASTER
命令:```ssh hadoop@app-12 "cd /hadoop/HBase/hbase-2.2.0/bin && ./start-hbase.sh"```
21、查看是否启动成功
命令:```ssh hadoop@app-12 "jps"```
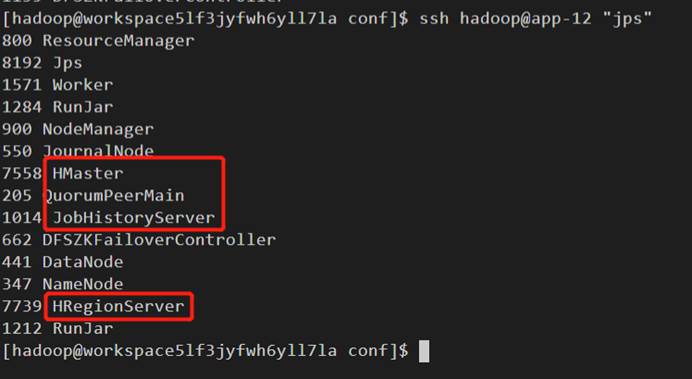
22、打开HBaseWeb监控页面
网址:http:// app-12:16030
## 设置自动化脚本
23、添加到自动启动中
命令:```vi /hadoop/config.conf```
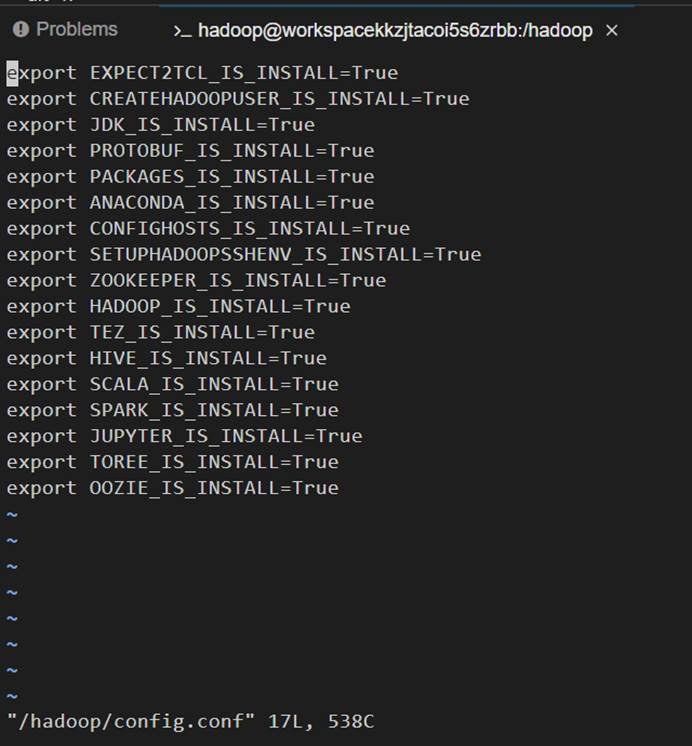
24、添加export HBASE_IS_INSTALL=True
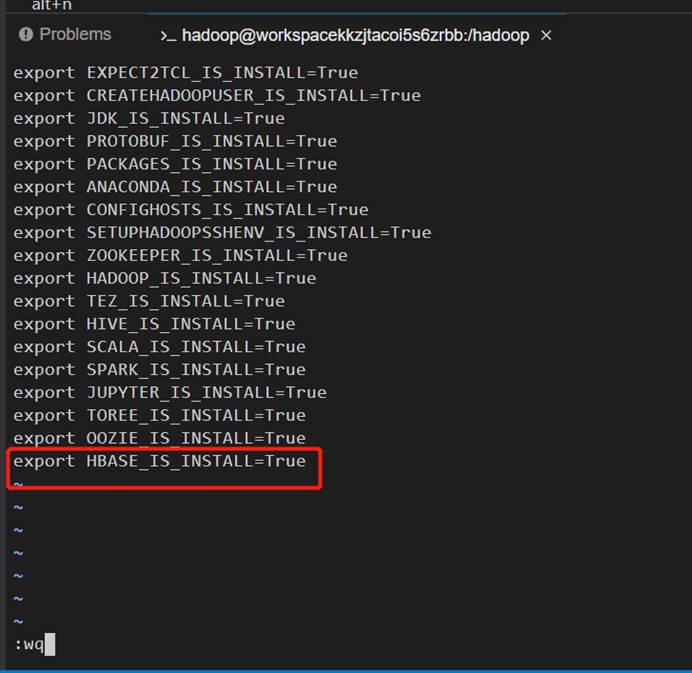
25、使环境变量生效
命令:```source ~/.bashrc```

26、确认start.all脚本有HBase
命令:```vi /hadoop/startAll.sh```
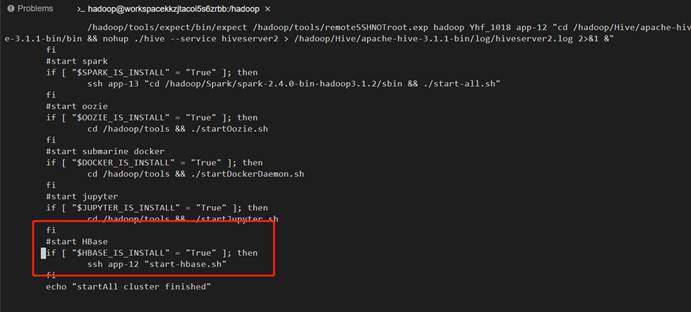
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

1、以hadoop用户登录
命令:su – hadoop

2、进入HBase安装目录下
命令:cd /hadoop/HBase/hbase-2.2.0/

3、启动客户端
命令:bin/hbase shell

4、创建表,表名txt,列簇名info
命令:create 'txt','info'

5、查看是否创建成功
命令:list

6、查看表内的数据
命令:scan 'txt'

7、添加数据,是一列一列添加的,列簇名是username
命令:put 'txt','001','info:username','henry'

8、查看表的内容
命令:scan 'txt'

9、再添加一条数据
命令:put 'txt','001','info:age','20'

10、再查看表的内容
命令:scan 'txt'

11、查看表的属性信息
命令:describe 'txt'

12、对表的行数求和
命令:count 'txt'

13、获得某列数据,获得001的username的值
命令:get 'txt','001','info:username'

14、删除某列数据,删除001的age列
命令:delete 'txt','001','info:age'

15、查看表的内容
命令:scan 'txt'

16、删除表之前先禁用该表
命令:disable 'txt'

17、查看该表是否可用
命令:is_enabled 'txt'

18、删除该表
命令:drop 'txt'

19、查看所有表
命令:list
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

消息队列
消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行–它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。在分布式计算环境中,为了集成分布式应用,开发者需要对异构网络环境下的分布式应用提供有效的通信手段。为了管理需要共享的信息,对应用提供公共的信息交换机制是重要的。常用的消息队列技术是 Message Queue。
Message Queue 的通讯模式
1、点对点通讯:点对点方式是最为传统和常见的通讯方式,它支持一对一、一对多、多对多、多对一等多种配置方式,支持树状、网状等多种拓扑结构。 2、多点广播:MQ 适用于不同类型的应用。其中重要的,也是正在发展中的是”多点广播”应用,即能够将消息发送到多个目标站点 (Destination List)。可以使用一条 MQ 指令将单一消息发送到多个目标站点,并确保为每一站点可靠地提供信息。MQ 不仅提供了多点广播的功能,而且还拥有智能消息分发功能,在将一条消息发送到同一系统上的多个用户时,MQ 将消息的一个复制版本和该系统上接收者的名单发送到目标 MQ 系统。目标 MQ 系统在本地复制这些消息,并将它们发送到名单上的队列,从而尽可能减少网络的传输量。 3、发布/订阅 (Publish/Subscribe) 模式:发布/订阅功能使消息的分发可以突破目的队列地理指向的限制,使消息按照特定的主题甚至内容进行分发,用户或应用程序可以根据主题或内容接收到所需要的消息。发布/订阅功能使得发送者和接收者之间的耦合关系变得更为松散,发送者不必关心接收者的目的地址,而接收者也不必关心消息的发送地址,而只是根据消息的主题进行消息的收发。 4、群集 (Cluster):为了简化点对点通讯模式中的系统配置,MQ 提供 Cluster(群集) 的解决方案。群集类似于一个域 (Domain),群集内部的队列管理器之间通讯时,不需要两两之间建立消息通道,而是采用群集 (Cluster) 通道与其它成员通讯,从而大大简化了系统配置。此外,群集中的队列管理器之间能够自动进行负载均衡,当某一队列管理器出现故障时,其它队列管理器可以接管它的工作,从而大大提高系统的高可靠性。
Apache Kafka 原理
Kafka 是一个消息系统,原本开发自 LinkedIn,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。现在它已被多家公司作为多种类型的数据管道和消息系统使用。活动流数据是几乎所有站点在对其网站使用情况做报表时都要用到的数据中最常规的部分。活动数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。运营数据指的是服务器的性能数据(CPU、IO 使用率、请求时间、服务日志等等数据),总的来说,运营数据的统计方法种类繁多。
Kafka 专用术语
●Broker:Kafka 集群包含一个或多个服务器,这种服务器被称为 broker。
●Topic:每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上,但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)。
●Partition:Partition 是物理上的概念,每个 Topic 包含一个或多个 Partition。
●Producer:负责发布消息到 Kafka broker。
●Consumer:消息消费者,向 Kafka broker 读取消息的客户端。
●Consumer Group:每个 Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定 group name,若不指定 group name 则属于默认的 group)。
Kafka 交互流程
Kafka 是一个基于分布式的消息发布-订阅系统,它被设计成快速、可扩展的、持久的。与其他消息发布-订阅系统类似,Kafka 在主题当中保存消息的信息。生产者向主题写入数据,消费者从主题读取数据。由于 Kafka 的特性是支持分布式,同时也是基于分布式的,所以主题也是可以在多个节点上被分区和覆盖的。
信息是一个字节数组,程序员可以在这些字节数组中存储任何对象,支持的数据格式包括 String、JSON、Avro。Kafka 通过给每一个消息绑定一个键值的方式来保证生产者可以把所有的消息发送到指定位置。属于某一个消费者群组的消费者订阅了一个主题,通过该订阅消费者可以跨节点地接收所有与该主题相关的消息,每一个消息只会发送给群组中的一个消费者,所有拥有相同键值的消息都会被确保发给这一个消费者。
Kafka 设计中将每一个主题分区当作一个具有顺序排列的日志。同处于一个分区中的消息都被设置了一个唯一的偏移量。Kafka 只会保持跟踪未读消息,一旦消息被置为已读状态,Kafka 就不会再去管理它了。Kafka 的生产者负责在消息队列中对生产出来的消息保证一定时间的占有,消费者负责追踪每一个主题 (可以理解为一个日志通道) 的消息并及时获取它们。基于这样的设计,Kafka 可以在消息队列中保存大量的开销很小的数据,并且支持大量的消费者订阅。
利用 Apache Kafka 系统架构的设计思路
示例:网络游戏
假设我们正在开发一个在线网络游戏平台,这个平台需要支持大量的在线用户实时操作,玩家在一个虚拟的世界里通过互相协作的方式一起完成每一个任务。由于游戏当中允许玩家互相交易金币、道具,我们必须确保玩家之间的诚信关系,而为了确保玩家之间的诚信及账户安全,我们需要对玩家的 IP 地址进行追踪,当出现一个长期固定 IP 地址忽然之间出现异动情况,我们要能够预警,同时,如果出现玩家所持有的金币、道具出现重大变更的情况,也要能够及时预警。此外,为了让开发组的数据工程师能够测试新的算法,我们要允许这些玩家数据进入到 Hadoop 集群,即加载这些数据到 Hadoop 集群里面。
对于一个实时游戏,我们必须要做到对存储在服务器内存中的数据进行快速处理,这样可以帮助实时地发出预警等各类动作。我们的系统架设拥有多台服务器,内存中的数据包括了每一个在线玩家近 30 次访问的各类记录,包括道具、交易信息等等,并且这些数据跨服务器存储。
我们的服务器拥有两个角色:首先是接受用户发起的动作,例如交易请求,其次是实时地处理用户发起的交易并根据交易信息发起必要的预警动作。为了保证快速、实时地处理数据,我们需要在每一台机器的内存中保留历史交易信息,这意味着我们必须在服务器之间传递数据,即使接收用户请求的这台机器没有该用户的交易信息。为了保证角色的松耦合,我们使用 Kafka 在服务器之间传递信息 (数据)。
Kafka 特性
Kafka 的几个特性非常满足我们的需求:可扩展性、数据分区、低延迟、处理大量不同消费者的能力。这个案例我们可以配置在 Kafka 中为登录和交易配置同一个主题。由于 Kafka 支持在单一主题内的排序,而不是跨主题的排序,所以我们为了保证用户在交易前使用实际的 IP 地址登录系统,我们采用了同一个主题来存储登录信息和交易信息。
当用户登录或者发起交易动作后,负责接收的服务器立即发事件给 Kafka。这里我们采用用户 id 作为消息的主键,具体事件作为值。这保证了同一个用户的所有的交易信息和登录信息被发送到 Kafka 分区。每一个事件处理服务被当作一个 Kafka 消费者来运行,所有的消费者被配置到了同一个消费者群组,这样每一台服务器从一些 Kafka 分区读取数据,一个分区的所有数据被送到同一个事件处理服务器 (可以与接收服务器不同)。当事件处理服务器从 Kafka 读取了用户交易信息,它可以把该信息加入到保存在本地内存中的历史信息列表里面,这样可以保证事件处理服务器在本地内存中调用用户的历史信息并做出预警,而不需要额外的网络或磁盘开销。
图 1. 游戏设计图

为了多线程处理,我们为每一个事件处理服务器或者每一个核创建了一个分区。Kafka 已经在拥有 1 万个分区的集群里测试过。
切换回 Kafka
上面的例子听起来有点绕口:首先从游戏服务器发送信息到 Kafka,然后另一台游戏服务器的消费者从主题中读取该信息并处理它。然而,这样的设计解耦了两个角色并且允许我们管理每一个角色的各种功能。此外,这种方式不会增加负载到 Kafka。测试结果显示,即使 3 个结点组成的集群也可以处理每秒接近百万级的任务,平均每个任务从注册到消费耗时 3 毫秒。
上面例子当发现一个事件可疑后,发送一个预警标志到一个新的 Kafka 主题,同样的有一个消费者服务会读取它,并将数据存入 Hadoop 集群用于进一步的数据分析。
因为 Kafka 不会追踪消息的处理过程及消费者队列,所以它在消耗极小的前提下可以同时处理数千个消费者。Kafka 甚至可以处理批量级别的消费者,例如每小时唤醒一次一批睡眠的消费者来处理所有的信息。
Kafka 让数据存入 Hadoop 集群变得非常简单。当拥有多个数据来源和多个数据目的地时,为每一个来源和目的地配对地编写一个单独的数据通道会导致混乱发生。Kafka 帮助 LinkedIn 规范了数据通道格式,并且允许每一个系统获取数据和写入数据各一次,这样极大地减少数据通道的复杂性和操作耗时。
LinkedIn 的架构师 Jay Kreps 说:“我最初是在 2008 年完成键值对数据存储方式后开始的,我的项目是尝试运行 Hadoop,将我们的一些处理过程移动到 Hadoop 里面去。我们在这个领域几乎没有经验,花了几个星期尝试把数据导入、导出,另外一些事件花在了尝试各种各样的预测性算法使用上面,然后,我们开始了漫漫长路”。
与 Flume 的区别
Kafka 与 Flume 很多功能确实是重复的。以下是评估两个系统的一些建议:
1、Kafka 是一个通用型系统。你可以有许多的生产者和消费者分享多个主题。相反地,Flume 被设计成特定用途的工作,特定地向 HDFS 和 HBase 发送出去。Flume 为了更好地为 HDFS 服务而做了特定的优化,并且与 Hadoop 的安全体系整合在了一起。基于这样的结论,Hadoop 开发商 Cloudera 推荐如果数据需要被多个应用程序消费的话,推荐使用 Kafka,如果数据只是面向 Hadoop 的,可以使用 Flume。 2、Flume 拥有许多配置的来源 (sources) 和存储池 (sinks)。然后,Kafka 拥有的是非常小的生产者和消费者环境体系,Kafka 社区并不是非常支持这样。如果你的数据来源已经确定,不需要额外的编码,那你可以使用 Flume 提供的 sources 和 sinks,反之,如果你需要准备自己的生产者和消费者,那你需要使用 Kafka。 3、Flume 可以在拦截器里面实时处理数据。这个特性对于过滤数据非常有用。Kafka 需要一个外部系统帮助处理数据。 4、无论是 Kafka 或是 Flume,两个系统都可以保证不丢失数据。然后,Flume 不会复制事件。相应地,即使我们正在使用一个可以信赖的文件通道,如果 Flume agent 所在的这个节点宕机了,你会失去所有的事件访问能力直到你修复这个受损的节点。使用 Kafka 的管道特性不会有这样的问题。 5、Flume 和 Kafka 可以一起工作的。如果你需要把流式数据从 Kafka 转移到 Hadoop,可以使用 Flume 代理 (agent),将 kafka 当作一个来源 (source),这样可以从 Kafka 读取数据到 Hadoop。你不需要去开发自己的消费者,你可以使用 Flume 与 Hadoop、HBase 相结合的特性,使用 Cloudera Manager 平台监控消费者,并且通过增加过滤器的方式处理数据。
结束语
综上所述,Kafka 的设计可以帮助我们解决很多架构上的问题。但是想要用好 Kafka 的高性能、低耦合、高可靠性、数据不丢失等特性,我们需要非常了解 Kafka,以及我们自身的应用系统使用场景,并不是任何环境 Kafka 都是最佳选择。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

消息队列
消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行–它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。在分布式计算环境中,为了集成分布式应用,开发者需要对异构网络环境下的分布式应用提供有效的通信手段。为了管理需要共享的信息,对应用提供公共的信息交换机制是重要的。常用的消息队列技术是 Message Queue。
Message Queue 的通讯模式
1、点对点通讯:点对点方式是最为传统和常见的通讯方式,它支持一对一、一对多、多对多、多对一等多种配置方式,支持树状、网状等多种拓扑结构。 2、多点广播:MQ 适用于不同类型的应用。其中重要的,也是正在发展中的是”多点广播”应用,即能够将消息发送到多个目标站点 (Destination List)。可以使用一条 MQ 指令将单一消息发送到多个目标站点,并确保为每一站点可靠地提供信息。MQ 不仅提供了多点广播的功能,而且还拥有智能消息分发功能,在将一条消息发送到同一系统上的多个用户时,MQ 将消息的一个复制版本和该系统上接收者的名单发送到目标 MQ 系统。目标 MQ 系统在本地复制这些消息,并将它们发送到名单上的队列,从而尽可能减少网络的传输量。 3、发布/订阅 (Publish/Subscribe) 模式:发布/订阅功能使消息的分发可以突破目的队列地理指向的限制,使消息按照特定的主题甚至内容进行分发,用户或应用程序可以根据主题或内容接收到所需要的消息。发布/订阅功能使得发送者和接收者之间的耦合关系变得更为松散,发送者不必关心接收者的目的地址,而接收者也不必关心消息的发送地址,而只是根据消息的主题进行消息的收发。 4、群集 (Cluster):为了简化点对点通讯模式中的系统配置,MQ 提供 Cluster(群集) 的解决方案。群集类似于一个域 (Domain),群集内部的队列管理器之间通讯时,不需要两两之间建立消息通道,而是采用群集 (Cluster) 通道与其它成员通讯,从而大大简化了系统配置。此外,群集中的队列管理器之间能够自动进行负载均衡,当某一队列管理器出现故障时,其它队列管理器可以接管它的工作,从而大大提高系统的高可靠性。
Apache Kafka 原理
Kafka 是一个消息系统,原本开发自 LinkedIn,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。现在它已被多家公司作为多种类型的数据管道和消息系统使用。活动流数据是几乎所有站点在对其网站使用情况做报表时都要用到的数据中最常规的部分。活动数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。运营数据指的是服务器的性能数据(CPU、IO 使用率、请求时间、服务日志等等数据),总的来说,运营数据的统计方法种类繁多。
Kafka 专用术语
●Broker:Kafka 集群包含一个或多个服务器,这种服务器被称为 broker。
●Topic:每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic。(物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上,但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)。
●Partition:Partition 是物理上的概念,每个 Topic 包含一个或多个 Partition。
●Producer:负责发布消息到 Kafka broker。
●Consumer:消息消费者,向 Kafka broker 读取消息的客户端。
●Consumer Group:每个 Consumer 属于一个特定的 Consumer Group(可为每个 Consumer 指定 group name,若不指定 group name 则属于默认的 group)。
Kafka 交互流程
Kafka 是一个基于分布式的消息发布-订阅系统,它被设计成快速、可扩展的、持久的。与其他消息发布-订阅系统类似,Kafka 在主题当中保存消息的信息。生产者向主题写入数据,消费者从主题读取数据。由于 Kafka 的特性是支持分布式,同时也是基于分布式的,所以主题也是可以在多个节点上被分区和覆盖的。
信息是一个字节数组,程序员可以在这些字节数组中存储任何对象,支持的数据格式包括 String、JSON、Avro。Kafka 通过给每一个消息绑定一个键值的方式来保证生产者可以把所有的消息发送到指定位置。属于某一个消费者群组的消费者订阅了一个主题,通过该订阅消费者可以跨节点地接收所有与该主题相关的消息,每一个消息只会发送给群组中的一个消费者,所有拥有相同键值的消息都会被确保发给这一个消费者。
Kafka 设计中将每一个主题分区当作一个具有顺序排列的日志。同处于一个分区中的消息都被设置了一个唯一的偏移量。Kafka 只会保持跟踪未读消息,一旦消息被置为已读状态,Kafka 就不会再去管理它了。Kafka 的生产者负责在消息队列中对生产出来的消息保证一定时间的占有,消费者负责追踪每一个主题 (可以理解为一个日志通道) 的消息并及时获取它们。基于这样的设计,Kafka 可以在消息队列中保存大量的开销很小的数据,并且支持大量的消费者订阅。
利用 Apache Kafka 系统架构的设计思路
示例:网络游戏
假设我们正在开发一个在线网络游戏平台,这个平台需要支持大量的在线用户实时操作,玩家在一个虚拟的世界里通过互相协作的方式一起完成每一个任务。由于游戏当中允许玩家互相交易金币、道具,我们必须确保玩家之间的诚信关系,而为了确保玩家之间的诚信及账户安全,我们需要对玩家的 IP 地址进行追踪,当出现一个长期固定 IP 地址忽然之间出现异动情况,我们要能够预警,同时,如果出现玩家所持有的金币、道具出现重大变更的情况,也要能够及时预警。此外,为了让开发组的数据工程师能够测试新的算法,我们要允许这些玩家数据进入到 Hadoop 集群,即加载这些数据到 Hadoop 集群里面。
对于一个实时游戏,我们必须要做到对存储在服务器内存中的数据进行快速处理,这样可以帮助实时地发出预警等各类动作。我们的系统架设拥有多台服务器,内存中的数据包括了每一个在线玩家近 30 次访问的各类记录,包括道具、交易信息等等,并且这些数据跨服务器存储。
我们的服务器拥有两个角色:首先是接受用户发起的动作,例如交易请求,其次是实时地处理用户发起的交易并根据交易信息发起必要的预警动作。为了保证快速、实时地处理数据,我们需要在每一台机器的内存中保留历史交易信息,这意味着我们必须在服务器之间传递数据,即使接收用户请求的这台机器没有该用户的交易信息。为了保证角色的松耦合,我们使用 Kafka 在服务器之间传递信息 (数据)。
Kafka 特性
Kafka 的几个特性非常满足我们的需求:可扩展性、数据分区、低延迟、处理大量不同消费者的能力。这个案例我们可以配置在 Kafka 中为登录和交易配置同一个主题。由于 Kafka 支持在单一主题内的排序,而不是跨主题的排序,所以我们为了保证用户在交易前使用实际的 IP 地址登录系统,我们采用了同一个主题来存储登录信息和交易信息。
当用户登录或者发起交易动作后,负责接收的服务器立即发事件给 Kafka。这里我们采用用户 id 作为消息的主键,具体事件作为值。这保证了同一个用户的所有的交易信息和登录信息被发送到 Kafka 分区。每一个事件处理服务被当作一个 Kafka 消费者来运行,所有的消费者被配置到了同一个消费者群组,这样每一台服务器从一些 Kafka 分区读取数据,一个分区的所有数据被送到同一个事件处理服务器 (可以与接收服务器不同)。当事件处理服务器从 Kafka 读取了用户交易信息,它可以把该信息加入到保存在本地内存中的历史信息列表里面,这样可以保证事件处理服务器在本地内存中调用用户的历史信息并做出预警,而不需要额外的网络或磁盘开销。
图 1. 游戏设计图
为了多线程处理,我们为每一个事件处理服务器或者每一个核创建了一个分区。Kafka 已经在拥有 1 万个分区的集群里测试过。
切换回 Kafka
上面的例子听起来有点绕口:首先从游戏服务器发送信息到 Kafka,然后另一台游戏服务器的消费者从主题中读取该信息并处理它。然而,这样的设计解耦了两个角色并且允许我们管理每一个角色的各种功能。此外,这种方式不会增加负载到 Kafka。测试结果显示,即使 3 个结点组成的集群也可以处理每秒接近百万级的任务,平均每个任务从注册到消费耗时 3 毫秒。
上面例子当发现一个事件可疑后,发送一个预警标志到一个新的 Kafka 主题,同样的有一个消费者服务会读取它,并将数据存入 Hadoop 集群用于进一步的数据分析。
因为 Kafka 不会追踪消息的处理过程及消费者队列,所以它在消耗极小的前提下可以同时处理数千个消费者。Kafka 甚至可以处理批量级别的消费者,例如每小时唤醒一次一批睡眠的消费者来处理所有的信息。
Kafka 让数据存入 Hadoop 集群变得非常简单。当拥有多个数据来源和多个数据目的地时,为每一个来源和目的地配对地编写一个单独的数据通道会导致混乱发生。Kafka 帮助 LinkedIn 规范了数据通道格式,并且允许每一个系统获取数据和写入数据各一次,这样极大地减少数据通道的复杂性和操作耗时。
LinkedIn 的架构师 Jay Kreps 说:“我最初是在 2008 年完成键值对数据存储方式后开始的,我的项目是尝试运行 Hadoop,将我们的一些处理过程移动到 Hadoop 里面去。我们在这个领域几乎没有经验,花了几个星期尝试把数据导入、导出,另外一些事件花在了尝试各种各样的预测性算法使用上面,然后,我们开始了漫漫长路”。
与 Flume 的区别
Kafka 与 Flume 很多功能确实是重复的。以下是评估两个系统的一些建议:
1、Kafka 是一个通用型系统。你可以有许多的生产者和消费者分享多个主题。相反地,Flume 被设计成特定用途的工作,特定地向 HDFS 和 HBase 发送出去。Flume 为了更好地为 HDFS 服务而做了特定的优化,并且与 Hadoop 的安全体系整合在了一起。基于这样的结论,Hadoop 开发商 Cloudera 推荐如果数据需要被多个应用程序消费的话,推荐使用 Kafka,如果数据只是面向 Hadoop 的,可以使用 Flume。 2、Flume 拥有许多配置的来源 (sources) 和存储池 (sinks)。然后,Kafka 拥有的是非常小的生产者和消费者环境体系,Kafka 社区并不是非常支持这样。如果你的数据来源已经确定,不需要额外的编码,那你可以使用 Flume 提供的 sources 和 sinks,反之,如果你需要准备自己的生产者和消费者,那你需要使用 Kafka。 3、Flume 可以在拦截器里面实时处理数据。这个特性对于过滤数据非常有用。Kafka 需要一个外部系统帮助处理数据。 4、无论是 Kafka 或是 Flume,两个系统都可以保证不丢失数据。然后,Flume 不会复制事件。相应地,即使我们正在使用一个可以信赖的文件通道,如果 Flume agent 所在的这个节点宕机了,你会失去所有的事件访问能力直到你修复这个受损的节点。使用 Kafka 的管道特性不会有这样的问题。 5、Flume 和 Kafka 可以一起工作的。如果你需要把流式数据从 Kafka 转移到 Hadoop,可以使用 Flume 代理 (agent),将 kafka 当作一个来源 (source),这样可以从 Kafka 读取数据到 Hadoop。你不需要去开发自己的消费者,你可以使用 Flume 与 Hadoop、HBase 相结合的特性,使用 Cloudera Manager 平台监控消费者,并且通过增加过滤器的方式处理数据。
结束语
综上所述,Kafka 的设计可以帮助我们解决很多架构上的问题。但是想要用好 Kafka 的高性能、低耦合、高可靠性、数据不丢失等特性,我们需要非常了解 Kafka,以及我们自身的应用系统使用场景,并不是任何环境 Kafka 都是最佳选择。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
配置文件修改解释
server.properties
1、修改前:
 将#listeners=PLAINTEXT://:9092修改为listeners=PLAINTEXT://app-11:9092、#advertised.listeners=PLAINTEXT://your.host.name:9092修改为#advertised.listeners=PLAINTEXT://app-11:9092是改为自己本机的ip
将#listeners=PLAINTEXT://:9092修改为listeners=PLAINTEXT://app-11:9092、#advertised.listeners=PLAINTEXT://your.host.name:9092修改为#advertised.listeners=PLAINTEXT://app-11:9092是改为自己本机的ip
修改后:

2、修改前:

将log.dirs=/tmp/kafka-logs修改为log.dirs=/hadoop/Kafka/kafka_2.11-2.2.0/kafka-logs这是改为kafka的目录下,会自动生成kafka-logs目录
修改后:

3、修改前:
 将zookeeper.connect=localhost:2181修改为zookeeper.connect=app-11:2181,app-12:2181,app-13:2181,这是修改zookeeper,我们的zookeeper不仅在app-11上,还有app-12和app-13上。
将zookeeper.connect=localhost:2181修改为zookeeper.connect=app-11:2181,app-12:2181,app-13:2181,这是修改zookeeper,我们的zookeeper不仅在app-11上,还有app-12和app-13上。
修改后:

下载安装包
1、以hadoop用户登录
命令:su – hadoop

2、进入到hadoop的根目录下
命令:cd /hadoop/

3、创建安装kafka的目录
命令:mkdir Kafka

4、进入Kafka目录
命令:cd Kafka/

5、下载kafka安装包
命令:wget http://archive.apache.org/dist/kafka/2.2.0/kafka_2.11-2.2.0.tgz

6、解压安装包
命令:tar -xvf kafka_2.11-2.2.0.tgz

修改配置文件
7、进入配置文件
命令:cd kafka_2.11-2.2.0/config/

8、将server.properties配置文件删除
命令:rm -rf server.properties

9、将修改好的配置文件拷贝到该目录下
命令:cp /tmp/Spark-stack/Kafka/conf/server.properties ./

10、返回上级目录
命令:cd .. 
11、测试单节点是否安装成功,启动kafka
命令:bin/kafka-server-start.sh config/server.properties &

12、查看是否启动成功
命令:ps -ef|grep kafka

13、关闭kafka
命令:bin/kafka-server-stop.sh

14、修改环境变量
命令:vi ~/.bashrc
export KAFKA_HOME=/hadoop/Kafka/kafka_2.11-2.2.0
export PATH=${KAFKA_HOME}/bin:$PATH

15、使环境生效
命令:source ~/.bashrc

13、查看环境变量是否生效
命令:echo $PATH

其他机器的设置
14、在app-12和app-13上创建安装kafka的目录
命令:ssh hadoop@app-12 "mkdir /hadoop/Kafka"、ssh hadoop@app-13 "mkdir /hadoop/Kafka"

15、返回上级目录
命令:cd ..

16、将kafka安装拷贝到app-12和app-13上
命令:scp -r kafka_2.11-2.2.0/ hadoop@app-13:/hadoop/Kafka/、scp -r kafka_2.11-2.2.0/ hadoop@app-12:/hadoop/Kafka/

17、将环境变量拷贝到其他机器上
命令:scp ~/.bashrc hadoop@app-12:~/、scp ~/.bashrc hadoop@app-13:~/

修改其他机器上的配置文件
14、登录app-12机器
命令:ssh hadoop@app-12

15、打开配置文件
命令:vi /hadoop/Kafka/kafka_2.11-2.2.0/config/server.properties
将所有的app-11改为app-12
 app-12broker.id改为1
app-12broker.id改为1

16、退出app-12机器
命令:exit

17、登录app-13机器
命令:ssh hadoop@app-13

18、打开配置文件
命令:vi /hadoop/Kafka/kafka_2.11-2.2.0/config/server.properties

19、退出app-13
命令:exit

设置自动化脚本
20、为了方便启动kafka,我们做了一个脚本启动三台机器的kafka,将启动脚本拷贝到
命令:cp /tmp/Spark-stack/Kafka/sh/* /hadoop/tools/

21、给脚本赋权限
命令:chmod -R a+x /hadoop/tools/*Kafka*

22、在hadoop/config.conf中增加kafka
命令:vi /hadoop/config.conf
export KAFKA_IS_INSTALL=True

23、在启动、停止全部的脚本中加入kafka
命令:vi /hadoop/startAll.sh
#start Kafka
if [ "$KAFKA_IS_INSTALL" = "True" ]; then
cd hadoop/tools && ./startKafka.sh
fi

命令:vi /hadoop/stopAll.sh
#stop Kafka
if [ "$KAFKA_IS_INSTALL" = "True" ]; then
cd /hadoop/tools && ./stopKafka.sh
fi

22、启动kafka
命令:cd /hadoop/tools/、./startKafka.sh

23、使环境变量生效
命令:source ~/.bashrc

24、启动脚本
命令:./startKafka.sh

23、检查是否启动成功
命令:ps -ef|grep kafka
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

1、创建Topic,连接的zookeeper是2181,名字取为songshu-topic
命令:bin/kafka-topics.sh --create –zookeeper app-11:2181 app-12:2181 app-13:2181 --replication-factor 1 --partitions 1 --topic songshu-topic

2、查看Topic
命令:bin/kafka-topics.sh --list --zookeeper app-11:2181 app-12:2181 app-13:2181

3、发送消息
命令:bin/kafka-console-producer.sh --broker-list app-11:9092 app-12:9092 app-13:9092--topic songshu-topic
发送消息内容:HelloWord、123、003(发送的内容可自定义)
注:当输入命令之后,会出现小箭头,在箭头之后输入需要发送的消息

4、新建一个new terminal,以hadoop用户登录,在进入到kafka目录下
命令:su – hadoop、cd /hadoop/Kafka/kafka_2.11-2.2.0

5、接受消息
命令:bin/kafka-console-consumer.sh --bootstrap-server app-11:9092 app-12:9092 app-13:9092 --topic songshu-topic --from-beginning
注:打印的信息和发送的内容是一样的

6、返回之前的发送命令下,继续输入一个内容
命令:abc

7、在返回接收的命令下,会实时接收到信息
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Kafka Cluster
这是kafka为我们提供的四大类API,kafka不存在单节点一说,存在的单节点也是单节点集群,都是一个一个的集群,kafka默认的就是集群。有两个客户端操作分别是Producers客户端和Consumers客户端,Connectors就是kafka和DB的一个交互,Stream Processors是流处理API。最常用的是Producers和Consumers,最复杂的是Consumers,所以Consumers是我们的重点。除了这四类还有Admin,这一共是五类API。

客户端API类型

AdminClient API:允许管理和检测Topic、broker以及其它Kafka对象。 Producer API:发布消息到1个或多个topic。 Consumer API :订阅一个或多个topic,并处理产生的消息。 Streams API:高效地将输入流转换到输出流。 Connector API:从一些源系统或应用程序中拉取数据到kafka。
代码操做加解释
1、创建Java Empty Env

2、点击左侧第一个图标上传程序文件

3、点击右键选择Upload Flies

4、点击右侧第二个图标新建new terminal

5、在命令行里输入命令,先解压程序压缩包
命令:tar -xf kafka-study-coding.tar

6、删除压缩包
命令:rm -rf kafka-study-coding.tar

7、以root用户登录
命令:sudo /bin/bash

8、将kafka集群的ip地址添加到hosts文件中
命令:vi /etc/hosts 192.168.30.140 app-13 192.168.138.63 app-12 192.168.235.178 app-11

9、进入到程序目录下
命令:cd kafka-study-coding/

往后的操作都是先编译后运行
编译:mvn compile -Dexec.mainClass="com.kinginsai.bigdata.kafka.admin.AdminSample"
运行:mvn exec:java -Dexec.mainClass="com.kinginsai.bigdata.kafka.admin.AdminSample" -Dexec.classpathScope=runtime -Dmaven.test.skip=true
10、设置AdminClient,连接kafka集群,地址是服务器的host

11、创建Topic,Topic的名字为songshu-topic,运行的结果打印出来

12、获取topic列表

13、删除topic,并查看topic是否删除
 运行结果:
运行结果:

14、描述topic
 运行结果:
运行结果:

15、查看配置信息
 运行结果:
运行结果:

16、增加partition,之后运行描述topic,看是否增加了
 运行结果:
运行结果:


常见问题 1、

在root用户下,删除target。
 2、在创toptic的时候,出现以下警告,是因为后台在不停的打印,创建成功之后还在打印,在创建的就是重复的了,所以出以下警告
2、在创toptic的时候,出现以下警告,是因为后台在不停的打印,创建成功之后还在打印,在创建的就是重复的了,所以出以下警告

在创建的最后加上adminClient.close();关闭adminClient即可。

详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Producer发送模式
1、同步发送 2、异步发送 3、异步回调发送
业务流程

producer的发送大致分为两步,第一步是先构建producer,第二步是send出去
Producer发送原理

kafka的生产者主要做了三个事情,第一个是直接发送,直接发送是指kafka会把producer的消息发送到整个分区leader的broker上,一般不会涉及到其他的干预。还会缓存producer的主节点列表,如果leader出现问题会刷新列表。 第二个是负载均衡,负载均衡器是默认的,会告诉我们两件事,第一是kafka的producer数据可以被控制在哪个partition上,第二个是数据具体在哪个partition上由谁来决定的,这个是由我们的客户端决定的。 第三个是异步发送,异步发送分两件事情,第一个是它本身是future对象,这个future对象可以不获取。第二是做批量发送,会在内存里积累数据,当单次请求发送数据达到一定的预值会按批次的将数据发送到kafka上,这样首先减少了io操作,变相的提高了吞吐量。
代码操做及解释
1、接之前的操作,如果没有之前的操作,就先把app-11、app-12、app-13的ip地址写入hosts文件中。如果写完之后,打开pom文件,将 com.kinginsai.bigdata.kafka.admin. AdminSample修改为com.kinginsai.bigdata.kafka.producer.ProducerSample,其实这里是修改主程序,运行那个class填写那个路径。
 往后的运行操作:
先编译:
往后的运行操作:
先编译:mvn compile -Dexec.mainClass="com.kinginsai.bigdata.kafka.producer.ProducerSample"
后运行:mvn exec:java -Dexec.mainClass="com.kinginsai.bigdata.kafka.producer.ProducerSample" -Dexec.classpathScope=runtime -Dmaven.test.skip=true
2、Producer异步发送演示。
以下运行程序都是先编译后运行,上面都是配置信息。
 3、检查运行之后是否是我们想象的结果,登录app-11,新建new terminal,以hadoop用户登录,在进入到kafka的目录下
命令:
3、检查运行之后是否是我们想象的结果,登录app-11,新建new terminal,以hadoop用户登录,在进入到kafka的目录下
命令:su – hadoop、cd /hadoop/Kafka/kafka_2.11-2.2.0/

4、查看接受消息
命令:bin/kafka-console-consumer.sh --bootstrap-server app-11:9092 app-12:9092 app-13:9092 --topic songshu-topic --from-beginning

5、Producer异步阻塞发送演示,区别在于send有返回值,是future类型,future是发出去就不管了,在get之前都不会获取返回值,但是每次发送都获取一下,就相当于把返回值阻塞在这个位置上了,就是发送一次停一次。随机发送。
 运行结果:
运行结果:

6、Producer异步发送带回调函数,offset是不同的,offset是针对partition的,会有不同的partition有相同的offset,offset是做文件解锁的
 运行结果:
运行结果:

一般来讲我们经常用的是Producer异步发送,如果需要做消息记录的用Producer异步发送带回调函数,这个会将值回调,阻塞会阻塞在哪。
7、Producer异步发送带回调函数和Partition负载均衡,自定义的partition。结果的partition是五个0和五个1。

 运行结果:
运行结果:

常见问题

问题解释:不识别app-11、app-12、app-13的ip地址 解决方法:将app-11、app-12、app-13的ip地址写入hosts文件中
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

代码操做及解释
1、在运行每个单独class的时,要先检查pom文件中的主程序是否对应的是要执行的class
 后面的发送信息的(Producer)运行操作的命令:
编译:
后面的发送信息的(Producer)运行操作的命令:
编译:mvn compile -Dexec.mainClass="com.kinginsai.bigdata.kafka.producer.ProducerSample"
运行:mvn exec:java -Dexec.mainClass="com.kinginsai.bigdata.kafka.producer.ProducerSample" -Dexec.classpathScope=runtime -Dmaven.test.skip=true
2、先发送100条信息,用的是producer中的Producer异步发送带回调函数和Partition负载均衡

编译成功:

运行成功:有50个0和50个1

3、开始运行consumer,先将pom文件改为consumer的
 后面运行消费的(Consumer)操作命令:
编译:
后面运行消费的(Consumer)操作命令:
编译:mvn compile -Dexec.mainClass="com.kinginsai.bigdata.kafka.consumer.ConsumerSample"
运行:mvn exec:java -Dexec.mainClass="com.kinginsai.bigdata.kafka.consumer.ConsumerSample" -Dexec.classpathScope=runtime -Dmaven.test.skip=true
4、运行consumersample中的helloworld。一般来讲工作中有,但是不推荐,因为什么都不用关心,每条消息都会有一条offset,在消费的时候就会以offset的偏移量为主,就是当前消费哪个offset会告诉kafka,下次再消费的时候会以偏移量的下一个位置继续消费,这是正常的操作形式。但是,这种形式在一般工作中很少很少有这种需要打印system.out,只是打印出kafka的数据,很多时候,我们是要拿数据去做一个业务处理,而做业务处理时就会出现操作失败,也有可能出现耗时的,在基于这样的场景下再去使用这个就很尴尬了,它会定时提交,在提交的时候你有可能没有操作完,但是提交之后,下次就消费不到了。就会出现很多问题。
因为有consumer,offset的topic就会记录在客户端在哪个partition上消费了哪个offset,室友记录的,所有在下次的时候就会发现,之前订阅过了就不会再消费了。

编译成功:

运行成功:

手动提交
5、修改pom文件

6、先发送100条信息,再手动提交。

7、提交,先注释掉手动提交的代码,反复消费,看是否可以重复消费,再取消注释,手动提交之后再消费是消费不到的。
 运行结果:
运行结果:

8、手动对每个Partition进行提交,先发送100条信息。这没有做什么优化反而多循环,之前是都拉取下来做循环,这次是针对每次拉取下来的做循环,这是为多线程处理的时候做铺垫,多线程是对每个partition做单独的处理,在单独处理的情况下,就会出现有的partition成功,有的不成功,在这种情况下,我们循环
 运行结果:
运行结果:


9、手动订阅某个或某些分区,并提交offset。
 运行结果:
运行结果:

Consumer注意事项
1、单个分区的消息只能由ConsumerGroup中某个Consumer消费,也就是Consumer对partition可以是一对多或者一对一。


2、Consumer从Partition中消费信息是顺序,默认从头开始消费。 3、单个ConsumerGroup会消费所有Partition中的消息,比如:有一个consumer有两到三个partition,consumer可以消费所有的partition。
consumer基本概念

kafka的每个消息都会进入到每个partition,如果只有一个Consumer在消费的情况下,那就代表着partition数据变成串行,但是consumer比partition多是没有意义的,目前最佳事件就是一个consumer对应一个partition,这样依然可以利用CPU的性能,还可以并行处理partition中所有的数据,所以在这样的情况下,利用了高效遍历,这肯定依赖了多线程。
 运行结果:
运行结果:

10、多线程处理consumer


运行结果:

11、也是多线程运行,这个稍微复杂,更类似于现在的生产环境。首先创建了CunsumerExecutor,也就是一个线程池。这两个最主要的区别就是consumer是创建次数,ConsumerThreadSample就是创建多次,就有一个线程就会创建一次,还有就是消息来了去做分发,consumer自身不做任何处理。以下是这次的思路。没有具体说这两种哪个好哪个不好,视情况而定。
 运行结果:
运行结果:

12、控制offset的起始位置。手动提交offset可能还是不能更精准的控制offset,想要控制offset的起始位置,比如说需要重复消费。
这里的开始消费的位置根据发送的信息的填写。这里会打印很多回,因为我们做的是一个循环,每次循环都是根据消费的位置开始的。
这个练习告诉我们,kafka是不会随便丢消息的,和正常的消息队列是有区别的。

运行结果:

13、流量控制。因为kafka是高吞吐量,不会分配到太多的内存,当达到一个峰值的时候,consumer很可能会被停掉,这个时候就需要限流。partition1和partition0都是消费了前40条信息之后断开。
 运行结果:
运行结果:


常见问题

问题解释:没有接受到offset数据 解决办法:不要关闭当前的命令,重新发送一遍信息,consumer就会接收到信息之后就会自动消费到。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Kafka Stream基本概念
1、Kafka Stream是处理分析储存在Kafka数据的客户端程序库
2、Kafka Stream通过state store可以实现高校状态操作
3、支持原语Processor和高层抽象DSL

最上面的P0、P1、P2、P3是partition的数据,P0、P1、P2、P3这些组成的是topic,topic的数据会分散在不同的Task上,Thread就是线程,将不同的数据发到不同的Task中做处理,处理之后会有一个单独的State去记录我们的状态。
Kafka Stream关键词
1、流及流处理器:流是数据流,流处理器是在整个流向的过程中对里面的数据做一些处理,它可能有很多节点,有可能有不同的目标。
2、流处理拓扑:就是一个拓扑图,这个图包含了流的走向、流处理的节点。
3、源处理器及Sink处理器:源处理器是指数据的源头,Sink处理器是结果处理器。

Source Processor是源处理器,每条线就是Stream就是流,最后当出结果了就是Sink处理器,将所有的数据做汇总。
高层架构图

P0、P1、P2、P3是partition,这些数据由一个一个的consumer去消费,中间的流可以不用管,消费完成之后,会将所有的生成数据汇总成一个producer,producer会继续推送到partition中。从图中可以看出来kafka流处理默认的是从一个topic中拿出数据,经过流处理再用producer推给另外一个topic。那么有可能是一个topic也有可能是多个topic,这里建议是多个topic,至少两个topic,一个接收待处理的数据,一个接受处理完的数据。
代码解释操作
1、先创建两个topic,一个负责接受一个负责发送。先用Admin创建topic。
命令:
编译:mvn compile -Dexec.mainClass="com.kinginsai.bigdata.kafka.admin.AdminSample"
运行:mvn exec:java -Dexec.mainClass="com.kinginsai.bigdata.kafka.admin.AdminSample" -Dexec.classpathScope=runtime -Dmaven.test.skip=true

 运行结果:
运行结果:

2、这次演示的名称是wordcount-app,StreamBuild是怎么构建kafka的流,这个流是长期持久的,会一直不断的输入流里面的东西,就会有一个start。
KStream中的key和value都是String类型,source就是从哪个topic中读取数据,用空格做截取,统计Wordcount。然后组合并,将相同的单词放到一起,再做整合。整合之后返回的数据类型不是数据,返回的是KTable,将count构建到流上,再写到接收的topic。
KStream是不断从INPUT_topic上获取新数据,并且追加到流上的一个抽象对象,类似于栈的一个东西,不断的压栈。
KTable是数据集合的抽象对象。
flatMapValues是将一行数据拆分成多行数据,将拆分的数据每次整合到组里的每一步都是算子。
命令:
编译:mvn compile -Dexec.mainClass="com.kinginsai.bigdata.kafka.stream.StreamSample"
运行:mvn exec:java -Dexec.mainClass="com.kinginsai.bigdata.kafka.stream.StreamSample" -Dexec.classpathScope=runtime -Dmaven.test.skip=true
 运行结果:
运行结果:

3、验证是否运行成功,在集群中,打开app-11,新建new terminal,以hadoop用户登录,进入到Kafka的安装目录下,输入songshu-stream-in t要输入的信息,再新建new terminal,输入songshu-stream-out接受的信息
命令:
bin/kafka-console-producer.sh --broker-list app-11:9092 --topic songshu-stream-in
这里输入的信息分别是Hello World Kafka、Hello World songshu、Hello Kafka songshu

命令:
bin/kafka-console-consumer.sh --bootstrap-server app-11:9092 --topic songshu-stream-out --property print.key=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer --from-beginning
看最后的三行就是3个hello,2个world,2个Kafka,前面的因为是每行都读做一次worldcount,将不同的world做了一次整合,之后再有相同的会整合到之前的上面,最后的输出一次。

4、演示下算子,
 运行结果:
运行结果:

5、在new terminal中输入要输入的信息

6、返回程序查看结果,前面的key不重要,后面的world就是以空格分隔,一个一个的数据,再整合到组中。

详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Kafka Connect基本概念
1、Kafka Connect是Kafka流式计算的一部分,左侧是数据源包括了数据库、hadoop、文本等等,右侧是数据结果包括了文本、hadoop、数据库,中间上层就是Kafka Connect,它里面会有很多的输入,将输入的内容的读取进来转交给Kafka里,也有可能将kafka里的内容拿出来放到我们的外部数据源中。

2、Kafka Connect 主要用来与其他中间件建立流式通道
3、Kafka Connect支持流式和批量处理集成
Kafka Connect环境准备
1、在app-11上新建new terminal,以hadoop用户登录,创建存放Kafka Connect依赖包
命令:su – hadoop、mkdir /hadoop/plugins
2、进入该目录下
命令:cd /hadoop/plugins/

3、下载kafka connect依赖包
命令:wget https://d1i4a15mxbxib1.cloudfront.net/api/plugins/confluentinc/kafka-connect-jdbc/versions/10.0.1/confluentinc-kafka-connect-jdbc-10.0.1.zip

4、下载mysql启动jdbc
命令:wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.18/mysql-connector-java-8.0.18.jar

5、解压kafka connect依赖包
命令:unzip confluentinc-kafka-connect-jdbc-10.0.1.zip

6、删除安装包
命令:rm -rf confluentinc-kafka-connect-jdbc-10.0.1.zip

7、将mysql的驱动包拷贝到kafka connect中
命令:cp mysql-connector-java-8.0.18.jar confluentinc-kafka-connect-jdbc-10.0.1/lib/

8、进入kafka修改配置文件
命令:cd /hadoop/Kafka/kafka_2.11-2.2.0/config/

9、配置文件中connect-distributed.properties是集群版的配置, connect-standalone.properties是配置单机版的,现在配置集群版的。
命令:vi connect-distributed.properties
修改ip地址,连接kafka的服务器

将rest.port=8083释放出来,这是提供一个rest管理界面,可以动态的使用管理,这个端口号可以自己设置

支持引入外部依赖

10、返回上层目录,准备启动connect
命令:cd ..

配置其他机器
11、拷贝
命令:
scp -r -p /hadoop/plugins hadoop@app-12:/hadoop/plugins/、 scp -r -p /hadoop/plugins hadoop@app-13:/hadoop/plugins/

12、删除app-12和app-13上之前的配置文件
命令:ssh hadoop@app-12 "rm -rf /hadoop/Kafka/kafka_2.11-2.2.0/config/connect-distributed.properties"
ssh hadoop@app-13 "rm -rf /hadoop/Kafka/kafka_2.11-2.2.0/config/connect-distributed.properties"

13、拷贝配置文件
命令:scp /hadoop/Kafka/kafka_2.11-2.2.0/config/connect-distributed.properties hadoop@app-12:/hadoop/Kafka/kafka_2.11-2.2.0/config/
scp /hadoop/Kafka/kafka_2.11-2.2.0/config/connect-distributed.properties hadoop@app-13:/hadoop/Kafka/kafka_2.11-2.2.0/config/

11、分别app-11、app-12、app-13的启动connect
命令:bin/connect-distributed.sh config/connect-distributed.properties

12、查看是否启动成功,创建一个内部浏览器

13、在内部浏览器中输入:输入的ip地址是自己机器app-11的ip
http://192.168.138.35:8083/connector-plugins 显示的是confluent中的版本号
(ip地址也可以是app-11)
14、在内部浏览器中输入:http://192.168.138.35:8083/connectors 因为是实时接收动态,现在还是空的。 (ip地址也可以是app-11)

添加任务
15、创建数据库,在app-12上,新建new terminal,启动mysql数据库
命令:mysql -uroot -p

16、创建数据库
命令:create database kafka;

17、进入数据库创建表 命令:
use kafka;
create table `user`(
`id` int primary key,
`name` varchar(20),
`age` int);

18、在app-11上,新建new terminal,以hadoop用户登录,直接连接任务 命令:连接的ip地址是要看自己机器的,是连接该机器得到kafka;” songshu-upload-mysql”是任务的名字,连接的是app-12的mysql;每次增加是需要更新的,根据id的标识符增加.
curl -X POST -H 'Content-Type: application/json' -i 'http://192.168.30.163:8083/connectors' \
--data \
'{"name":"songshu-upload-mysql","config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:mysql://app-14:3306/kafka?user=root&password=Yhf_1018",
"table.whitelist":"user",
"incrementing.column.name": "id",
"mode":"incrementing",
"topic.prefix": "songshu-mysql-"}}'

19、刷新内部浏览器,http://192.168.138.35:8083/connectors,出现名字证明连接成功。

20、在数据库中添加数据
命令:insert into user values (1,'aaa',18);
insert into user values (2,'bbb',10);

21、返回app-11的new terminal,查看connect
命令:cd /hadoop/Kafka/kafka_2.11-2.2.0/、
bin/kafka-console-consumer.sh --bootstrap-server 192.168.30.157:9092 --topic songshu-mysql-user --from-beginning
显示的就是刚才插入的数据,这部分是从mysql写入connect

22、演示从connect读取到mysql,先创建一个读出存放数据的表 命令:
create table `user_bck`(
`id` int primary key,
`name` varchar(20),
`age` int);

23、在app-11的new terminal的中连接任务,注意这两个任务的名不能一样
curl -X POST -H 'Content-Type: application/json' -i 'http://192.168.30.157:8083/connectors' \
--data \
'{"name":"songshu-download-mysql","config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mysql://app-14:3306/kafka?user=root&password=Yhf_1018",
"topics":"songshu-mysql-user",
"auto.create":"false",
"insert.mode": "upsert",
"pk.mode":"record_value",
"pk.fields":"id",
"table.name.format": "user_bck"}}'

24、刷新内部浏览器

25、查看刚才创建的表user_bck
命令:select * from user_bck;

Kafka Connect 关键词
1、Work 是connect分为两种模式,一种是Standalone是单机的,另一种的Distributed是分布式,在生产环境中一般是以分布式的为准。这两个的配置还是比较类似的。图是task和instance平衡关系的。

2、Connect和Task,connect是类似于任务调度,connect在处理任务的过程将工作交给具体的Task去做。Task的具体操作流程在Source Data中获取到紧接着做converter,做完之后产生offset紧接着提交,

3、Task Rebalance,connect会尽量平衡task的工作,当task的工作过大或者不饱和时会触发Task Rebalance,Task会重新组织工作量处理。但是有例外,就是当Task失败的时候,就不会重新安排,挂掉了就挂掉了,把失败的Task的任务分配给其他的。

4、AvroConverter是处理数据转换的,

详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

基本概念
1、Flink程序的基础构建模块是流(streams)与转换(transformations),流就是指输入,转换就是指对输入的数据进行的操作。
2、每一个数据流起始于一个或多个source,并终止于一个或多个sink。
下面的图是一个典型的由Flink程序映射为Streaming Dataflow的示意图,env就是运行环境或者是上下文,addSource (new FlinkKafkaConsumer)就是指通过Flink消费Kafka作为数据输入,就是Source。然后将输入的数据开始转换,先进行map对每一条数据进行parse,之后对每个stats做id的聚合,时间窗口的操作,时间窗口聚合函数。addSink就是将处理好的数据继续落地,为其他业务提供数据。

我们的输入、转换、Sink的时候是可以并行的,Flink是支持并行的。比如说,我们对Source可以进行分区,把一个Source拆分成子任务,然后对每个分区进行map。map之后继续进行转换,按照key进行聚合,窗口操作等等。然后再添加到Sink。

3、时间窗口
4、流上的聚合需要由窗口来划定范围,比如“计算过去的5分钟”或者“最后100个元素的和”
5、窗口通常被区分为不同的类型,比如滚动窗口(没有重叠),滑动窗口(有重叠),以及会话窗口(由不活动的间隙所打断)

Flink分布式运行环境
基本架构
1、Flink是基于Master-Slave风格的架构,经典的主从架构
2、Flink集群启动时,会启动一个JobManager进程、至少一个TaskManager进程

JobManager:Flink系统的协调者,它负责接受Flink Job,调度组成Jon的多个Task的执行;收集Job的状态信息,并管理Flink集群中从节点TaskManager TaskManager:实际负责执行计算的Worker,在其上执行Flink Job的一组Task;TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报 Clinet:用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群;Client会将用户提交的Flink程序组装一个JobGraph,并且是以JobGraph的形式提交的
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

基本概念
1、Flink程序的基础构建模块是流(streams)与转换(transformations),流就是指输入,转换就是指对输入的数据进行的操作。
2、每一个数据流起始于一个或多个source,并终止于一个或多个sink。
下面的图是一个典型的由Flink程序映射为Streaming Dataflow的示意图,env就是运行环境或者是上下文,addSource (new FlinkKafkaConsumer)就是指通过Flink消费Kafka作为数据输入,就是Source。然后将输入的数据开始转换,先进行map对每一条数据进行parse,之后对每个stats做id的聚合,时间窗口的操作,时间窗口聚合函数。addSink就是将处理好的数据继续落地,为其他业务提供数据。
我们的输入、转换、Sink的时候是可以并行的,Flink是支持并行的。比如说,我们对Source可以进行分区,把一个Source拆分成子任务,然后对每个分区进行map。map之后继续进行转换,按照key进行聚合,窗口操作等等。然后再添加到Sink。
3、时间窗口
4、流上的聚合需要由窗口来划定范围,比如“计算过去的5分钟”或者“最后100个元素的和”
5、窗口通常被区分为不同的类型,比如滚动窗口(没有重叠),滑动窗口(有重叠),以及会话窗口(由不活动的间隙所打断)
Flink分布式运行环境
基本架构
1、Flink是基于Master-Slave风格的架构,经典的主从架构
2、Flink集群启动时,会启动一个JobManager进程、至少一个TaskManager进程
JobManager:Flink系统的协调者,它负责接受Flink Job,调度组成Jon的多个Task的执行;收集Job的状态信息,并管理Flink集群中从节点TaskManager TaskManager:实际负责执行计算的Worker,在其上执行Flink Job的一组Task;TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报 Clinet:用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群;Client会将用户提交的Flink程序组装一个JobGraph,并且是以JobGraph的形式提交的
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
对于Flink而言底层是Java,Flink给我们提供了Java和Scala两种语言,在开发的过程当中你可以使用java或者Scala,使用Scala语言整体的风格会更加的简洁,可读性更强,所以推荐使用Scala,接下来我们使用的也是Scala写的程序。
Pom.xml
1、引入的依赖Flink1.10.1的版本,Scala是2.12版本

2、因为要做流式处理的开发,所以引入flink-streaming-scala

3、引入Scala-maven-plugin插件,主要用来做编译,在maven项目中把Scala源文件编译成字节码文件

4、引入maven-assembly-plugin插件,可以按照需求把最后生成的项目生成jar包

代码解释及操作
1、批处理:统计以下文本中词出现的次数
确定主程序是WordCount


命令:
mvn compile -Dexec.mainClass="com.songshu.wc.WordCount"
mvn exec:java -Dexec.mainClass="com.songshu.wc.WordCount" -Dexec.classpathScope=runtime -Dmaven.test.skip=true

运行结果:

2、流处理
命令:
mvn clean scala:compile compile -Dexec.mainClass="com.kinginsai.wc.StreamWordCount"
mvn exec:java -Dexec.mainClass="com.kinginsai.wc.StreamWordCount"


3、先将端口号7777启动
命令:nc -l -p 7777
程序运行之后,在输入数据

 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

安装Flink
1、创建集群

2、以root用户登录,进行三台机器的认证
命令:sudo /bin/bash、./initHosts.sh

3、以hadoop用户登录
命令:su – hadoop

4、启动集群
命令:cd /hadoop、./startAll.sh

5、创建安装Flink的目录
命令:mkdir /hadoop/Flink

6、进入该目录下
命令:cd /hadoop/Flink/

7、下载Flink安装包
命令:wget https://archive.apache.org/dist/flink/flink-1.10.1/flink-1.10.1-bin-scala_2.12.tgz

8、解压安装包
命令:tar -xf flink-1.10.1-bin-scala_2.12.tgz

修改配置文件
9、进入配置文件
命令:cd flink-1.10.1/conf/

10、打开文件
命令:vi flink-conf.yaml

11、修改JobManager的主机名为app-11

去掉注释,添加页面管理,修改端口号为9081,避免冲突

12、修改masters文件
命令:vi masters
防止web端口冲突
 修改后:
修改后:

13、修改slaves文件
命令:vi slaves

14、修改环境变量
命令:vi ~/.bashrc
export FLINK_HOME=/hadoop/Flink/flink-1.10.1
export PATH=${FLINK_HOME}/bin:$PATH

15、使环境变量生效
命令:source ~/.bashrc

其他机器的设置
16、创建安装Flink的安装目录
命令:ssh hadoop@app-12 "mkdir /hadoop/Flink"、
ssh hadoop@app-13 "mkdir /hadoop/Flink"

17、返回Flink的安装目录下
命令:cd /hadoop/Flink/

18、拷贝Flink
命令:scp -r -q flink-1.10.1 hadoop@app-12:/hadoop/Flink/、
scp -r -q flink-1.10.1 hadoop@app-13:/hadoop/Flink/

19、拷贝环境变量
命令:scp ~/.bashrc hadoop@app-12:~/、scp ~/.bashrc hadoop@app-13:~/

20、启动Flink
命令:cd flink-1.10.1、bin/start-cluster.sh
启动了两个进程,一个是standalonesession daemon,另一个是taskexecutor daemon

21、打开web控制页面,可以直接看到当前集群的状态


网址:app-11:9081

22、新建new terminal,以root用户登录,安装nc命令
命令:sudo /bin/bash、yum install nmap-ncat.x86_64
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

web控制页面介绍
1、当前集群的状态,3个task,0个运行的。

2、运行的Job和完成的Job都是0个。

3、当前TaskManager的情况,我们的集群是三个TaskManager。

4、JobManager的基本信息

5、提交Job

打包
6、将poml文件中的主程序删除,修改StreamWordCount的host和端口号,为app-11和7777


7、查看Java版本
命令:java -version

8、压缩程序
命令:tar -zcf Flink.tar Flink/

9、拷贝到app-11上
命令:scp Flink.tar 192.168.60.139:/workspace_logs/

10、返回app-11,将程序拷贝到Flink安装目录下
命令:cp /workspace_logs/Flink.tar /hadoop/Flink/

11、解压程序
命令:tar -xf Flink.tar

12、进入到这个程序的目录下
命令:cd Flink

13、程序打包
命令:
mvn clean scala:compile compile package

14、查看打包程序
命令:ls target/

15、将打包好的程序拷贝到Flink安装目录下
命令:cp target/FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar /hadoop/Flink/

提交job
16、返回网页,上传job,找到Workspace目录下的jar包上传



17、在new terminal中启动7777端口号
命令:nc -lk 7777

18、填写主程序和相关的配置信息

19、在Running Jobs中可以查看到信息

20、在7777端口号下输入Hello Word

21、在Task Manager中的studout中可以看到输出结果
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

yarn是在生产模式中比较常见,容器化资源管理平台上的部署。
1、下载支持hadoop版本的jar包
命令:cd /hadoop/Flink/flink-1.10.1/lib/、 wget https://repo1.maven.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.8.3-10.0/flink-shaded-hadoop-2-uber-2.8.3-10.0.jar

2、再将jar包拷贝到另外两台机器上,在相同的位置上
命令:scp -r -q flink-shaded-hadoop-2-uber-2.8.3-10.0.jar app-12:/hadoop/Flink/flink-1.10.1/lib、scp -r -q flink-shaded-hadoop-2-uber-2.8.3-10.0.jar app-13:/hadoop/Flink/flink-1.10.1/lib

3、启动yarn-session
命令:cd ..、
nohup bin/yarn-session.sh -n 3 -s 3 -jm 1024 -tm 1024 -nm test -d 2>&1 >/tmp/yarnsession.log &
JobManager Web是app-11 ,在hadoop集群上的任务名是004

4、使用内部浏览器打开hadoop集群
网址:app-11:8088

5、提交job
命令:flink run -c com.kinginsai.wc.StreamWordCount /hadoop/Flink/Flink-1.0-SNAPSHOT-jar-with-dependencies.jar --host app-11 --port 7777

6、在端口7777中输入字符

7、使用内部浏览器查看结果
网址:app-11:9081
TaskManager 中的stdout查看
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

Flink流处理理论1
Flink流处理理论2
Flink流处理理论3
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
社交网络数据分析案例
数据集介绍
该数据集包含2153471个用户,1143092个场所,1021970个签到,27098490个社交关系以及用户分配给场所的2809581评级;所有这些都是通过公共API从Foursquare应用程序中提取的。所有用户信息均已匿名,即用户地理位置也已匿名。每个用户都由一个id和GeoSpatial位置表示。场地也一样。数据包含在五个文件中:users.dat,containers.dat,checkins.dat,socialgraph.dat和rating.dat。以下是有关所有这些文件的内容和使用的更多详细信息。
文件内容:
-
users.dat:由一组用户组成,因此每个用户都有一个唯一的ID和代表用户家乡位置的地理空间位置(纬度和经度)。
-
events.dat:由一组场所(例如,餐馆)组成,以便每个场所都有唯一的ID和地理空间位置(纬度和经度)。
-
checkins.dat:标记用户在场所的签到(访问)。每个签到都具有唯一的ID以及用户ID和场所ID。
-
socialgraph.dat:包含用户之间存在的社交图边缘(连接)。每个社交关系由两个唯一的ID(first_user_id和second_user_id)表示的两个用户(朋友)组成。
-
rating.dat:包含隐式评分,用于量化用户对特定地点的喜欢程度。
数据集统计分析
- hadoopc2创建hive表,
CREATE DATABASE IF NOT EXISTS test;
USE test;
DROP TABLE IF EXISTS `SOCIALGRAPH`;
CREATE EXTERNAL TABLE IF NOT EXISTS `SOCIALGRAPH` (
firstUserId STRING,
secondUserId STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\|'
LINES TERMINATED BY '\n'
LOCATION '/user/hive/warehouse/test.db/socialgraph'
tblproperties ("skip.header.line.count"="2");
---select trim(firstUserId) as firstUserId, trim(secondUserId) as secondUserId from SOCIALGRAPH;
- hadoopc2(hive --service cli),统计
select count(1) from SOCIALGRAPH;
---27098490
select count(distinct Id) from (select trim(firstUserId) as Id from SOCIALGRAPH union select trim(secondUserId) as Id from SOCIALGRAPH)u;
---1880423
编译scala分析程序
bigdatawithloadeddatac1=>/tools:
- 进入bdcode/Flink, 编译程序
mvn clean scala:compile compile package -Dexec.mainClass="com.kinginsai.wc.SocialGraph"
也可以尝试执行单机版此数据处理程序,
mvn exec:java -Dexec.mainClass="com.kinginsai.wc.SocialGraph"
- cp target/Flink-1.0-SNAPSHOT-jar-with-dependencies.jar 到 /workspace_logs/
bigdatawithloadeddatac1=>/hadoopc1/hadoopc1:
- 集群上执行,
nohup yarn-session.sh -n 3 -s 3 -jm 1024 -tm 1024 -nm test -d 2>&1 >/tmp/yarnsession.log &
nohup flink run -c com.kinginsai.wc.SocialGraph /workspace_logs/Flink-1.0-SNAPSHOT-jar-with-dependencies.jar 1 hdfs://dmcluster/user/hive/warehouse/test.db/socialgraph/socialgraph.dat 50 2>&1 >/tmp/flink.log &
tail -f /tmp/flink.log
- 结果分析





社会网络分析方法


你有没有想过,你的朋友圈里的每一个人都是你的社交网络中的一个节点,而你们之间的互动则是社交网络中的边。这些节点和边构成了一个复杂的网络,而这个网络又会影响你的生活和决策。
这就是社会网络分析的基本概念。社会网络分析是一种研究人际关系和信息传播的方法,它可以帮助我们理解社交网络中的结构和动态,从而更好地预测和干预社会现象。
社会网络分析是近年来一种新兴的社科研究方法,帮助很多学者不断产出优秀的科研成果;有人甚至将“社会网络分析”称为“论文发表神器”,知网上以”社会网络分析“为关键词进行搜索,发文量呈上升的趋势。

社会网络分析已被广泛应用于社会科学的各个领域,如社会学、经济学、管理学、心理学、人类学、图书情报档案学、新闻传播学、教育学、数学、通信科学等学科。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
1.1Flume 定义
Flume是Cloudera提供一个分布式、可靠、高可用的海量日志采集、聚合和传输的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据的简单处理,并写到各种数据接收方的能力。Flume基于流式架构,灵活简单。
大数据主要解决的三件事情:海量数据的存储,传输和计算。每一个框架都有它的定位,Flume就是用于传输的。
官方说明:http://flume.apache.org/
为什么选用Flume? Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。
 1.2Flume基础架构
1.2Flume基础架构
 1.Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。
Agent 主要有 3 个部分组件,Source、Channel、Sink。
2.Source
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种
格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence
generator、syslog、http、legacy。
3.Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储
或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定
义。
4 .Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个Sink 的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel 以及 Kafka Channel。
Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
1.Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。
Agent 主要有 3 个部分组件,Source、Channel、Sink。
2.Source
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种
格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence
generator、syslog、http、legacy。
3.Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储
或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定
义。
4 .Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个Sink 的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel 以及 Kafka Channel。
Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

1.1Flume 定义
Flume是Cloudera提供一个分布式、可靠、高可用的海量日志采集、聚合和传输的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据的简单处理,并写到各种数据接收方的能力。Flume基于流式架构,灵活简单。
大数据主要解决的三件事情:海量数据的存储,传输和计算。每一个框架都有它的定位,Flume就是用于传输的。
官方说明:http://flume.apache.org/
为什么选用Flume? Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。
1.2Flume基础架构
1.Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。
Agent 主要有 3 个部分组件,Source、Channel、Sink。
2.Source
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种
格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence
generator、syslog、http、legacy。
3.Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储
或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定
义。
4 .Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个Sink 的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel 以及 Kafka Channel。
Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
2.1 安装地址
下载地址: http://archive.apache.org/dist/flume/ 安装包地址: http://archive.apache.org/dist/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
2.2 安装部署
一、操作步骤
1.创建RedisC1,C2,C3三台机器
 2.进入C1,进行三台机器的认证
切换到root用户。
命令:
2.进入C1,进行三台机器的认证
切换到root用户。
命令:sudo /bin/bash
 命令:
命令:cd /hadoop/

运行initHost.sh脚本,进行三台机器的认证:
命令:./initHosts.sh
 3. 在app11中操作,切换到hadoop用户,密码Yhf_1018
命令:
3. 在app11中操作,切换到hadoop用户,密码Yhf_1018
命令:su – hadoop 注:输入的密码是不显示出来的。
 4.进入hadoop根目录,并查看目录下的文件。
命令:
4.进入hadoop根目录,并查看目录下的文件。
命令:cd /hadoop/
 5.新建Flume文件夹
命令:
5.新建Flume文件夹
命令:mkdir Flume
 6.将 apache-flume-1.9.0-bin.tar.gz 上传到/hadoop/Flume目录下
命令:
6.将 apache-flume-1.9.0-bin.tar.gz 上传到/hadoop/Flume目录下
命令:cd Flume
wget http://archive.apache.org/dist/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
 7.解压
命令:
7.解压
命令:tar -zxf apache-flume-1.9.0-bin.tar.gz
 8.设置环境变量
命令:
8.设置环境变量
命令:vi ~/.bashrc
运行效果:
 8.设置FLUME_HOME目录和PATH目录,在环境变量中加入
8.设置FLUME_HOME目录和PATH目录,在环境变量中加入
export FLUME_HOME=/hadoop/Flume/apache-flume-1.9.0-bin
export PATH=${FLUME_HOME}/bin:$PATH
输入a或者i进行编辑
 ESC退出编辑,:wq 保存退出
9.需要使用source命令让刚刚的修改过的PATH执行。
命令:
ESC退出编辑,:wq 保存退出
9.需要使用source命令让刚刚的修改过的PATH执行。
命令:source ~/.bashrc
本机的设置完成。需要将本机的设置拷贝到其他机器上。
其他集群的设置
1.首先免密登录到app-12上,进入hadoop目录下创建Flume文件
命令:ssh hadoop@app-12 "cd /hadoop && mkdir Flume"
 2.所有的集群目录都是一样,需要将整个Flume安装包拷贝到其他集群的机器上。
命令:
2.所有的集群目录都是一样,需要将整个Flume安装包拷贝到其他集群的机器上。
命令:scp -r -q apache-flume-1.9.0-bin hadoop@app-12:/hadoop/Flume
注:-r是表示拷贝整个目录。 -q 是静默拷贝。 要返回flume所在的上一级目录。
 3.登录app-12, 查看是否拷贝成功
命令:
3.登录app-12, 查看是否拷贝成功
命令:ssh hadoop@app-12
 退出app-12,命令:
退出app-12,命令:exit
4.将环境变量拷贝到app-12上,进行覆盖拷贝。
命令:scp ~/.bashrc hadoop@app-12:~/
 命令:
命令:ssh hadoop@app-12 "source ~/.bashrc"
app-12完成。同理,在app-13上执行。
5.重复步骤1、2配置app-13
命令:ssh hadoop@app-13 "cd /hadoop && mkdir Flume"

scp -r -q apache-flume-1.9.0-bin hadoop@app-13:/hadoop/Flume
 登录app-13, 查看是否拷贝成功
命令:
登录app-13, 查看是否拷贝成功
命令:ssh hadoop@app-13
 退出app-13,命令:
退出app-13,命令:exit
将环境变量拷贝到app-13上,进行覆盖拷贝。
命令:scp ~/.bashrc hadoop@app-13:~/
 命令:
命令:ssh hadoop@app-13 "source ~/.bashrc"
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

监控端口数据官方案例
实验目的:使用 Flume 监听一个端口,收集该端口数据,并打印到控制台。
实验分析:
 实验步骤:
1.切换到hadoop根目录下
命令:
实验步骤:
1.切换到hadoop根目录下
命令:cd /hadoop/
2.安装 netcat 工具
1)先查看是否装有nc工具
命令:nc –help或 netcat –help
 图示为未装。
安装nc工具
命令:
图示为未装。
安装nc工具
命令:sudo yum install -y nc
 2)给app-12、app-13进行安装
命令:
2)给app-12、app-13进行安装
命令:ssh hadoop@app-12 "cd /hadoop && sudo yum install -y nc"
 命令:
命令:ssh hadoop@app-13 "cd /hadoop && sudo yum install -y nc"
 注:nc可开启一个客户端,也可开启一个服务端,是实现客户端与服务端之间通信的一个工具。
3)开启服务端的命令:
注:nc可开启一个客户端,也可开启一个服务端,是实现客户端与服务端之间通信的一个工具。
3)开启服务端的命令:nc -lk 4444
 被阻塞在这里了。 注:因为服务端没有写地址,默认localhost
被阻塞在这里了。 注:因为服务端没有写地址,默认localhost
4)登录app-12,切换到hadoop用户,密码Yhf_1018
命令:su – hadoop 注:输入的密码是不显示出来的。
 5)客户端连接服务端
命令:
5)客户端连接服务端
命令:nc app-11 44444
 同样被阻塞。
6)向app-11 发送hello
同样被阻塞。
6)向app-11 发送hello
 7)打开app-11,可以发现已接收到
7)打开app-11,可以发现已接收到
 8)在app-11,中输入welcome
8)在app-11,中输入welcome
 9)打开app-12,可以发现已接收到
9)打开app-12,可以发现已接收到
 10)打开app-11,Ctrl+c 结束app-11(服务端)
10)打开app-11,Ctrl+c 结束app-11(服务端)
 再打开app-12,Ctrl+c 结束app-12(客户端),再尝试连接app-11(服务端),发现无法连接。
命令:
再打开app-12,Ctrl+c 结束app-12(客户端),再尝试连接app-11(服务端),发现无法连接。
命令:nc app-11 44444
注:服务端结束以后,客户端不再存在,服务端可以单独存在,没有客户端连,但是服务可以照有,反之不行
 3.创建 Flume Agent 配置文件 flume-netcat-logger.conf(名字自定义,后面启动时会用到)
1)在 flume 目录下创建 job 文件夹并进入 job 文件夹。
命令:
3.创建 Flume Agent 配置文件 flume-netcat-logger.conf(名字自定义,后面启动时会用到)
1)在 flume 目录下创建 job 文件夹并进入 job 文件夹。
命令:cd apache-flume-1.9.0-bin
mkdir job
cd job/
 2)在 job 文件夹下创建 Flume Agent 配置文件 flume-netcat-logger.conf
命令:
2)在 job 文件夹下创建 Flume Agent 配置文件 flume-netcat-logger.conf
命令: vi flume-netcat-logger.conf
 在 flume-netcat-logger.conf 文件中添加如下内容。
添加内容如下:
在 flume-netcat-logger.conf 文件中添加如下内容。
添加内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1




 点击Ecs退出编辑,:wq保存退出
4.返回上一级目录,启动
命令:cd ..
方法一:
点击Ecs退出编辑,:wq保存退出
4.返回上一级目录,启动
命令:cd ..
方法一:
flume-ng agent --conf conf/ --name a1 --conf-file job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
方法二:
flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
 bin/flume-ng:bin目录下可执行文件 后面跟着核心的参数,也就是要启动的agent
参数说明:
--conf conf/ :表示配置文件存储在conf/目录
--name a1 :表示给agent起名为a1
--conf-file job/flume-telnet.conf :flume本次启动读取的配置文件是在job文件夹下的flume-telnet.conf文件。
-Dflume.root.logger==INFO,console :-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error。
运行结果:监控到的是127.0.0.1:44444
bin/flume-ng:bin目录下可执行文件 后面跟着核心的参数,也就是要启动的agent
参数说明:
--conf conf/ :表示配置文件存储在conf/目录
--name a1 :表示给agent起名为a1
--conf-file job/flume-telnet.conf :flume本次启动读取的配置文件是在job文件夹下的flume-telnet.conf文件。
-Dflume.root.logger==INFO,console :-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error。
运行结果:监控到的是127.0.0.1:44444

使用 netcat 工具向本机的 44444 端口发送内容
5.在app-11中重新打开一个终端,使用netcat工具向本机的44444端口发送内容,此时flume充当服务端。
命令:nc localhost 44444
 打印hello
打印hello

6.打开之前的终端(Flume 监听页面)观察接收数据情况
 7.Ctrl+c 关闭监听
7.Ctrl+c 关闭监听
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

实时监控单个追加文件
实验目的:实时监控 Hive 日志,并上传到 HDFS 中
实验分析:

实验步骤:
一、实验前准备
1.新建FlumeSqoopC1,C2,C3

进入C1,进行三台机器认证
切换到root用户。
命令:sudo /bin/bash
 进入hadoop目录下并查看有哪些文件夹。
命令:
进入hadoop目录下并查看有哪些文件夹。
命令:cd /hadoop/
 运行initHost.sh脚本,进行三台机器的认证:./initHosts.sh
命令:
运行initHost.sh脚本,进行三台机器的认证:./initHosts.sh
命令:./initHosts.sh
 1切换到hadoop用户,(密码Yhf_1018 )
命令:
1切换到hadoop用户,(密码Yhf_1018 )
命令:su – hadoop
 2切换到hadoop根目录下
命令:
2切换到hadoop根目录下
命令:cd /hadoop/
 3启动startAll.sh
命令:
3启动startAll.sh
命令:./startAll.sh

这个脚本里包含这三台机器所有的启动命令
进入C2
4.切换到/hadoop/Flume/apache-flume-1.9.0-bin下
命令:cd /hadoop/Flume/apache-flume-1.9.0-bin
 5.新建job文件夹
命令:
5.新建job文件夹
命令:mkdir job
 二、实验
1.创建 flume-file-hdfs.conf 文件(切换到job目录下)
命令:
二、实验
1.创建 flume-file-hdfs.conf 文件(切换到job目录下)
命令: touch flume-file-hdfs.conf
 2.编辑 flume-file-hdfs.conf 文件
命令:
2.编辑 flume-file-hdfs.conf 文件
命令:
vi flume-file-hdfs.conf
 添加如下内容
添加如下内容
a2.sources = r2
a2.sinks = k2
a2.channels = c2
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /hadoop/Hive/apache-hive-3.1.1-bin/tmp/hive.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://dmcluster/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳,默认为false
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件滚动的是文件(区别上面)
a2.sinks.k2.hdfs.rollInterval = 30
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2




 点击Ecs退出编辑,:wq保存退出
点击Ecs退出编辑,:wq保存退出
3.返回上一级,运行Flume
命令:cd ..
flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf
或者flume-ng agent --name a2 --conf-file job/flume-file-hdfs.conf

4.新打开一个终端,到/hadoop/Hive目录下开启hive客户端
命令:hive

5.再新打开一个终端,查看HDFS上是否有新生成的日志文件。
注:在hadoop用户下,命令:su - hadoop 密码:Yhf_1018
HDFS查看命令:hdfs dfs -ls /
 继续查看
继续查看
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

实时监控目录下多个新文件
实验目的:使用 Flume 监听整个目录的文件,并上传至 HDFS
实验分析:
实验步骤:

继续上一个实验。
1.切换到/hadoop/Flume/apache-flume-1.9.0-bin/job 目录
命令:cd /hadoop/Flume/apache-flume-1.9.0-bin/job

2.新建配置文件 flume-dir-hdfs.conf
命令:
touch flume-dir-hdfs.conf
 3.编辑 flume-dir-hdfs.conf 文件
命令:
3.编辑 flume-dir-hdfs.conf 文件
命令:
vi flume-dir-hdfs.conf
 添加以下内容
添加以下内容
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir =
/hadoop/Flume/apache-flume-1.9.0-bin/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp 结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path =hdfs://dmcluster/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
点击Ecs退出编辑,:wq保存退出





 4.新打开一个终端在hadoop用户下,切换到/hadoop/Flume/apache-flume-1.9.0-bin 目录下
命令:
4.新打开一个终端在hadoop用户下,切换到/hadoop/Flume/apache-flume-1.9.0-bin 目录下
命令:cd /hadoop/Flume/apache-flume-1.9.0-bin
5.新建 upload文件
命令:mkdir upload 6.向 upload 文件夹中添加文件
命令:
6.向 upload 文件夹中添加文件
命令:cd upload
touch songshu.log
 7.返回之前的终端,并且返回上一级,运行Flume
命令:
7.返回之前的终端,并且返回上一级,运行Flume
命令:cd ..
flume-ng agent --name a3 --conf-file job/flume-dir-hdfs.conf
 8.打开测试终端,输入查看命令
命令:
8.打开测试终端,输入查看命令
命令:ll
 显示已经上传成功
9.再新建一个songshu.tmp文件
命令:
显示已经上传成功
9.再新建一个songshu.tmp文件
命令:touch songshu.tmp
 10.查看是否上传成功
命令:
10.查看是否上传成功
命令:ll
 提示没有上传成功,因为给过滤掉了。
11.再新建一个songshu.txt文件
命令:
提示没有上传成功,因为给过滤掉了。
11.再新建一个songshu.txt文件
命令:touch songshu.txt 12.查看是否上传成功
命令:
12.查看是否上传成功
命令:ll

 13.在HDFS上查看数据
命令:
13.在HDFS上查看数据
命令:hdfs dfs -ls /flume/
 命令:
命令:hdfs dfs -ls /flume/upload
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

实时监控目录下的多个追加文件
实验目的:使用 Flume 监听整个目录的实时追加文件,并上传至 HDFS 实验分析:


实验步骤:
一、实验前准备步骤
1.切换到/hadoop/Flume/apache-flume-1.9.0-bin
命令:cd /hadoop/Flume/apache-flume-1.9.0-bin

2.新建files目录
命令:mkdir files
 3.切换到files目录下,创建file1.txt,file2.txt
命令:
3.切换到files目录下,创建file1.txt,file2.txt
命令:cd files/
touch file1.txt
touch file2.txt
 继续上一个实验。
二、实验
1.切换到/hadoop/Flume/apache-flume-1.9.0-bin/job 目录
命令:
继续上一个实验。
二、实验
1.切换到/hadoop/Flume/apache-flume-1.9.0-bin/job 目录
命令:cd /hadoop/Flume/apache-flume-1.9.0-bin/job
 2.新建配置文件flume-taildir-hdfs.conf
命令:
2.新建配置文件flume-taildir-hdfs.conf
命令:vi flume-taildir-hdfs.conf
 输入a或者i进入编辑模式
输入a或者i进入编辑模式
添加如下内容:
a4.sources = r4
a4.sinks = k4
a4.channels = c4
# Describe/configure the source
a4.sources.r4.type = TAILDIR
a4.sources.r4.positionFile = /hadoop/Flume/apache-flume-1.9.0-bin /tail_dir.json
a4.sources.r4.filegroups = f1
a4.sources.r4.filegroups.f1 = /hadoop/Flume/apache-flume-1.9.0-bin /files/file.*
# Describe the sink
a4.sinks.k4.type = hdfs
a4.sinks.k4.hdfs.path = hdfs://hadoop102:9000/flume/upload/%Y%m%d/%H
#上传文件的前缀
a4.sinks.k4.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a4.sinks.k4.hdfs.round = true
#多少时间单位创建一个新的文件夹
a4.sinks.k4.hdfs.roundValue = 1
#重新定义时间单位
a4.sinks.k4.hdfs.roundUnit = hour
#是否使用本地时间戳
a4.sinks.k4.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a4.sinks.k4.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a4.sinks.k4.hdfs.fileType = DataStream
#多久生成一个新的文件
a4.sinks.k4.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是 128M
a4.sinks.k4.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a4.sinks.k4.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a4.channels.c4.type = memory
a4.channels.c4.capacity = 1000
a4.channels.c4.transactionCapacity = 100
# Bind the source and sink to the channel
a4.sources.r4.channels = c4
a4.sinks.k4.channel = c4




 点击Ecs退出编辑,:wq保存退出
点击Ecs退出编辑,:wq保存退出
- 返回上一级目录,启动监控文件夹命令
命令:
cd ..flume-ng agent --conf conf/ --name a4 --conf-file job/flume-taildir-hdfs.conf
4.新打开一个命令终端,切换到hadoop用户下
命令:su - hadoop 密码:Yhf_1018
切换到cd /hadoop/Flume/apache-flume-1.9.0-bin/files目录下
命令:cd /hadoop/Flume/apache-flume-1.9.0-bin/files
向file1.txt,file2.txt 追加内容
命令:echo hello >> file1.txt
echo songshu >> file2.txt

5.在HDFS上查看数据
重新打开一个命令终端,再hadoop用户下
命令:hdfs dfs -ls /flume/upload

命令:hdfs dfs -ls /flume/upload/20210201
命令:hdfs dfs -ls /flume/upload/20210201/22

命令:hdfs dfs -cat /flume/upload/20210201/22/upload-.1612190485267
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

4.1Flume 事务

Flume是一个传输工具,在工作中要保证数据尽量不丢失,然而数据在传输过程中要经过source读数据——>再写给channel——>sink再从channel中取数据,在任一环节中都有可能会丢失数据。为保证数据不丢失,在过程中加入“事务”。 三个过程中间包含两个事务,Put事务流程和Take事务。
Put事务流程 •doPut:将批数据先写入临时缓冲区putList •doCommit:检查channel内存队列是否足够合并。 •doRollback:channel内存队列空间不足,回滚数据 Take事务 •doTake:将数据取到临时缓冲区takeList,并将数据发送到HDFS •doCommit:如果数据全部发送成功,则清除临时缓冲区takeList •doRollback:数据发送过程中如果出现异常,rollback将临时缓冲区takeList中的数据channel内存队列。
数据输入端:source Flume流式处理:channel 数据输出端:sink
1.source 从外部读取数据(端口,本地文件:文件夹,单个文件,多个文件。批量上传,断点续传),将读取到的一条一条的数据封装成事件(event)。 2.准备:doPut将批数据先写入临时缓冲区putList。然后再执行doCommit方法。 如果HDFS速度慢,那么sink的写出速度也随之减慢,同时sink从channel中拉取数据的速度也会减慢,那么channel中就会发生内存不够的状况(或者发生其它状况),此时doCommit就会提交异常,所以就会做doRollback回滚工作。 3.因为channel处于被动,所以要自己拉取数据,所以叫take事务。 如果sink拉取数据失败,就要做相应的doRollback回滚动作,数据将回滚到channel中。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

4.2 Flume Agent 内部原理
 1.source接收数据
2.封装事件,然后调用source里的channel processor获取channel。
3.将事件传递给拦截器(可有多个interceptor,形成拦截器链,实现拦截器的复用,更加灵活。拦截器与业务相关性高,那就尽量把条件写在一个里面。因为与业务相干性越高,提供复用的可能性越低。)
4.经过拦截器后又将数据返回,然后传给channel选择器。因为一个source可以绑定多个channel,如何绑定由channel选择器和选择策略控制。
1.source接收数据
2.封装事件,然后调用source里的channel processor获取channel。
3.将事件传递给拦截器(可有多个interceptor,形成拦截器链,实现拦截器的复用,更加灵活。拦截器与业务相关性高,那就尽量把条件写在一个里面。因为与业务相干性越高,提供复用的可能性越低。)
4.经过拦截器后又将数据返回,然后传给channel选择器。因为一个source可以绑定多个channel,如何绑定由channel选择器和选择策略控制。
Channel Selectors 有两 种 类 型 :
ReplicatingChannel Selector(副本channel选择器) (default)和Multiplexing ChannelSelector(多路channel选择器) 。Replicating会将source过来的events发往所有channel,而Multiplexing可 以配置发往哪些Channel。
ReplicatingChannel Selector:
 a1.sources.r1.selector.type = replicating 可以不写,因为是默认的
a1.sources.r1.selector.type = replicating 可以不写,因为是默认的
Multiplexing ChannelSelector:
 在为添加header之前,里面是空的。因为要配合拦截器一起使用,所以要给这个事件加一个头(state),header的数据结构为map<key,value>,所以key为state,value为CZ,US。
在为添加header之前,里面是空的。因为要配合拦截器一起使用,所以要给这个事件加一个头(state),header的数据结构为map<key,value>,所以key为state,value为CZ,US。
拦截器和channel选择器都是在数据写入channel之前要完成的事情。 5.再将事件传回channel列表。 6.根据Channel选择器的选择结果,将事件写入相应channel。在5和6之间做put事务。 7.因为一个channel可以绑定多个sink,如何绑定由sink组决定。
SinkProcessor 共有三 种类型,分别是DefaultSinkProcessor(默认的sink组) 、LoadBalancingSinkProcessor(负载均衡的)和 FailoverSinkProcessor(故障转移的)。DefaultSinkProcessor对应的是单个的Sink ,没有组的概念。 LoadBalancingSinkProcessor 和 FailoverSinkProcessor 对应的是 Sink Group,LoadBalancingSinkProcessor 可以实现负载均衡的功能,FailoverSinkProcessor 可以实现故障转移的功能(有一个active,其他为standby)。
DefaultSinkProcessor

当channel和sink为一一对应的关系的时候可以不用写这个策略。
LoadBalancingSinkProcessor
 Backoff:退避算法,默认是关闭的,要结合processor.selector.maxTimeOut(最大为30000s)
processor.selector:默认是round_robin轮巡,还有 random随机和用户自定义。
FailoverSinkProcessor
Backoff:退避算法,默认是关闭的,要结合processor.selector.maxTimeOut(最大为30000s)
processor.selector:默认是round_robin轮巡,还有 random随机和用户自定义。
FailoverSinkProcessor
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

4.3 Flume 拓扑结构
一、简单串联
这种模式是将多个 flume 顺序连接起来了,从最初的 source 开始到最终 sink 传送的
目的存储系统。此模式不建议桥接过多的 flume 数量,flume 数量过多不仅会影响传输速率,而且一旦传输过程中某个节点 flume 宕机,会影响整个传输系统。可以在同一台机器,也可以跨机器。

二、复制和多路复用
Flume 支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个
channel 中,或者将不同数据分发到不同的 channel 中,sink 可以选择传送到不同的目的
地。利用channel选择器中ReplicatingChannel Selector(副本channel选择器)完成这种功能。

三、负载均衡和故障转移
Flume支持使用将多个sink逻辑上分到一个sink组,sink组配合不同的SinkProcessor
可以实现负载均衡和错误恢复的功能。

四、聚合
这种模式是我们最常见的,也非常实用,日常 web 应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用 flume 的这种组合方式能很好的解决这一问题,每台服务器部署一个 flume 采集日志,传送到一个集中收集日志的flume,再由此 flume 上传到 hdfs、hive、hbase 等,进行日志分析。
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

复制
实验目的:使用 Flume-1 监控文件变动,Flume-1 将变动内容传递给 Flume-2,Flume-2 负责存储到 HDFS。同时 Flume-1 将变动内容传递给 Flume-3,Flume-3 负责输出到 Local FileSystem。
实验分析:

实验步骤:
一、实验前准备
1.新建FlumeSqoopC1,C2,C3
 进入C1,
一、进行三台机器认证
切换到root用户。
命令:
进入C1,
一、进行三台机器认证
切换到root用户。
命令:sudo /bin/bash
 进入hadoop目录下并查看有哪些文件夹。
命令:
进入hadoop目录下并查看有哪些文件夹。
命令:cd /hadoop/
 运行initHost.sh脚本,进行三台机器的认证:./initHosts.sh
命令:
运行initHost.sh脚本,进行三台机器的认证:./initHosts.sh
命令:./initHosts.sh
 二、启动集群
1切换到hadoop用户,(密码Yhf_1018 )命令:
二、启动集群
1切换到hadoop用户,(密码Yhf_1018 )命令:su – hadoop

2切换到hadoop根目录下
命令:cd /hadoop/
 3启动startAll.sh
命令:./startAll.sh
3启动startAll.sh
命令:./startAll.sh
 这个脚本里包含这三台机器所有的启动命令
进入c2,
1.切换到/hadoop/目录下,新建datas文件夹
命令:
这个脚本里包含这三台机器所有的启动命令
进入c2,
1.切换到/hadoop/目录下,新建datas文件夹
命令:cd /hadoop/
mkdir datas
 再新建test文件夹
命令:
再新建test文件夹
命令:mkdir test
 在test目录下新建hive.log
命令:
在test目录下新建hive.log
命令:touch hive.log
 向文件中追加内容:
命令:
向文件中追加内容:
命令:echo hello >> hive.log
echo ssss >> hive.log
2.切换到datas目录下,创建 flume3 文件夹
命令:cd datas
mkdir flume3

3.切换到/hadoop/Flume/apache-flume-1.9.0-bin目录下,新建job文件夹
命令:cd /hadoop/Flume/apache-flume-1.9.0-bin
mkdir job
 二、实验
1.切换到job里
命令:
二、实验
1.切换到job里
命令:cd job
2.创建编辑 flume-file-flume.conf配置文件
配置 1 个接收日志文件的 source 和两个 channel、两个 sink,分别输送给flume-flume-hdfs 和 flume-flume-dir。
命令:vi flume-file-flume.conf
输入a或i进行编辑,在文件中添加以下内容。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 将数据流复制给所有 channel
a1.sources.r1.selector.type = replicating
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /hadoop/test/hive.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
# sink 端的 avro 是一个数据发送者
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = app-12
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = app-12
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
 点击Ecs退出编辑,:wq保存退出
点击Ecs退出编辑,:wq保存退出
3.创建编辑flume-flume-hdfs.conf 配置文件
配置上级 Flume 输出的 Source,输出是到 HDFS 的 Sink。
命令:vi flume-flume-hdfs.conf
输入a或i进行编辑,在文件中添加以下内容。
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
# source 端的 avro 是一个数据接收服务
a2.sources.r1.type = avro
a2.sources.r1.bind =app-12
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://dmcluster/bbb/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k1.hdfs.filePrefix =bbb-
#是否按照时间滚动文件夹
a2.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k1.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是 128M
a2.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a2.sinks.k1.hdfs.rollCount = 0
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 1000
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
点击Ecs退出编辑,:wq保存退出
4.创建编辑flume-flume-dir.conf 配置文件
配置上级 Flume 输出的 Source,输出是到本地目录的 Sink。
命令:vi flume-flume-dir.conf
输入a或i进行编辑,在文件中添加以下内容。
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind =app-12
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /hadoop/datas/flume3
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2

5.执行配置文件
重新开2个命令终端,在hadoop用户下切换到/hadoop/Flume/apache-flume-1.9.0-bin目录下,分别启动对应的 flume 进程:flume-flume-dir,flume-flume-hdfs,flume-file-flume。
命令:cd /hadoop/Flume/apache-flume-1.9.0-bin
flume-ng agent --name a3 --conf-file job/flume-flume-dir.conf
flume-ng agent --name a2 --conf-file job/flume-flume-hdfs.conf
flume-ng agent --name a1 --conf-file job/flume-file-flume.conf
6.检查 HDFS 上数据
命令:hdfs dfs -ls /

hdfs dfs -ls /bbb
 一直想下查看,直到找到bbb-.文件 查看:
一直想下查看,直到找到bbb-.文件 查看:


7.检查/hadoop/datas/flume3 目录中数据
命令:cd /hadoop/datas/flume3
ll
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

负载均衡和故障转移
实验目的:使用 Flume1 监控一个端口,其 sink 组中的 sink 分别对接 Flume2 和 Flume3,采用FailoverSinkProcessor,实现故障转移的功能。
实验分析:

实验步骤:
实验前准备:
安装 netcat 工具
1)先查看是否装有nc工具
命令:nc –help或 netcat –help

图示为未装。
2)安装nc工具
命令:sudo yum install -y nc

切换到/hadoop/Flume/apache-flume-1.9.0-bin 目录下创建job2 文件夹
命令:cd /hadoop/Flume/apache-flume-1.9.0-bin
mkdir job2

开始实验:
1.切换到job2目录下
命令:cd job2
2.创建 f1.conf配置文件
配置 1 个 netcat source 和 1 个 channel、1 个 sink group(2 个 sink),分别输送给 flumeflume-console1 和 flume-flume-console2。
命令:vi f1.conf
输入a或i进行编辑,在文件中添加以下内容。
# Name the components on this agent
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = app-12
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = app-12
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1

3.创建 f2.conf配置文件
配置上级 Flume 输出的 Source,输出是到本地控制台。
命令:vi f2.conf
输入a或i进行编辑,在文件中添加以下内容。
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind =app-12
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = logger
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
4.创建 f3.conf配置文件
配置上级 Flume 输出的 Source,输出是到本地控制台。
命令:vi f3.conf
输入a或i进行编辑,在文件中添加以下内容。
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind =app-12
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
5.执行配置文件
重新开2个命令终端,在hadoop用户下切换到/hadoop/Flume/apache-flume-1.9.0-bin目录下,分别启动对应的 flume 进程:flume-flume-console2,flume-flume-console1,flume-netcatflume。
命令:cd /hadoop/Flume/apache-flume-1.9.0-bin
flume-ng agent --name a3 --conf-file job2/f3.conf -Dflume.root.logger=INFO,console
flume-ng agent --name a2 --conf-file job2/f2.conf -Dflume.root.logger=INFO,console
flume-ng agent --name a1 --conf-file job2/f1.conf
6.使用 netcat 工具向本机的 44444 端口发送内容
命令:nc localhost 44444
 输入hello
7.查看 Flume2 及 Flume3 的控制台打印日志
输入hello
7.查看 Flume2 及 Flume3 的控制台打印日志
 因为f3的优先级比f2要高,所以日志打印在f3
8.将 Flume2 kill,观察 Flume3 的控制台打印情况。
ctrl+c结束
因为f3的优先级比f2要高,所以日志打印在f3
8.将 Flume2 kill,观察 Flume3 的控制台打印情况。
ctrl+c结束
 9.以上为故障转移
10.负载均衡
命令:
9.以上为故障转移
10.负载均衡
命令:cp -r job2/ job3
 因为是针对一个sink组的不同策略,所以只需改动f1.conf
因为是针对一个sink组的不同策略,所以只需改动f1.conf
a1.sinkgroups.g1.processor.type = load_balance #负载均衡
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = random #随机

执行配置文件
flume-ng agent --name a3 --conf-file job3/f3.conf -Dflume.root.logger=INFO,console
flume-ng agent --name a2 --conf-file job3/f2.conf -Dflume.root.logger=INFO,console
flume-ng agent --name a1 --conf-file job3/f1.conf
此时没有优先级的概念,所以日志可能打印在1,2,3任何地方
11.使用 netcat 工具向本机的 44444 端口发送内容
命令:nc localhost 44444

输入hello2

输入hello3 注:使用 jps -ml 查看 Flume 进程。
注:使用 jps -ml 查看 Flume 进程。
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

聚合
实验目的:
app-11 上的 Flume-1 监控文件
/hadoop/test/group.log,app-12 上的 Flume-2 监控某一个端口的数据流,Flume-1与 Flume-2 将数据发送给 app-13 上的 Flume-3,Flume-3 将最终数据打印到控制台
实验分析:

实验步骤:
一、实验前准备
1.新建FlumeSqoopC1,C2,C3

进入C1,
一)进行三台机器认证
切换到root用户。
命令:sudo /bin/bash
 进入hadoop目录下并查看有哪些文件夹。
命令:
进入hadoop目录下并查看有哪些文件夹。
命令:cd /hadoop/ 运行initHost.sh脚本,进行三台机器的认证:./initHosts.sh
命令:
运行initHost.sh脚本,进行三台机器的认证:./initHosts.sh
命令:./initHosts.sh

二)启动集群
1切换到hadoop用户,(密码Yhf_1018 )
命令:su – hadoop
 2切换到hadoop根目录下
命令:
2切换到hadoop根目录下
命令:cd /hadoop/
 3启动startAll.sh
命令:
3启动startAll.sh
命令:./startAll.sh
 这个脚本里包含这三台机器所有的启动命令
三)
1.新建test文件夹,切换到此文件夹下新建group.log文件。
命令:
这个脚本里包含这三台机器所有的启动命令
三)
1.新建test文件夹,切换到此文件夹下新建group.log文件。
命令:mkdir test
cd test
touch group.log
 2.切换到 Flume/apache-flume-1.9.0-bin/目录下,新建job文件夹
命令:
2.切换到 Flume/apache-flume-1.9.0-bin/目录下,新建job文件夹
命令:cd ..
cd Flume/apache-flume-1.9.0-bin/
mkdir job

3.在app-12,app-13的Flume/apache-flume-1.9.0-bin/目录下,新建job文件夹
命令:ssh hadoop@app-12 "cd /hadoop/Flume/apache-flume-1.9.0-bin/ && mkdir job"
ssh hadoop@app-13 "cd /hadoop/Flume/apache-flume-1.9.0-bin/ && mkdir job”

二、开始实验
app-11
1.切换到job目录下
命令:cd job
 2.创建 f1.conf配置文件
配置 Source 用于监控group.log 文件,配置 Sink 输出数据到下一级 Flume。
命令:
2.创建 f1.conf配置文件
配置 Source 用于监控group.log 文件,配置 Sink 输出数据到下一级 Flume。
命令:vi f1.conf
输入a或i进行编辑,在文件中添加以下内容。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /hadoop/test/group.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = app-13
a1.sinks.k1.port = 4141
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3.安装nc工具
命令:sudo yum install -y nc
 安装成功。
app-12
4.免密登录app-12
命令:
安装成功。
app-12
4.免密登录app-12
命令:ssh app-12

切换到/hadoop/Flume/apache-flume-1.9.0-bin/job目录下,创建 f2.conf配置文件
命令:cd /hadoop/Flume/apache-flume-1.9.0-bin/job
vi f2.conf
配置 Source 监控端口 44444 数据流,配置 Sink 数据到下一级 Flume 输入a或i进行编辑,在文件中添加以下内容。
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = netcat
a2.sources.r1.bind = app-12
a2.sources.r1.port = 44444
# Describe the sink
a2.sinks.k1.type = avro
a2.sinks.k1.hostname =app-13
a2.sinks.k1.port = 4141
# Use a channel which buffers events in memory
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
点击Ecs退出编辑,:wq保存退出
5.安装nc工具
命令:
sudo yum install -y nc
app-13
6.免密登录app-13
命令:ssh app-13
切换到/hadoop/Flume/apache-flume-1.9.0-bin/job目录下,创建 f2.conf配置文件
配置 source 用于接收 flume1 与 flume2 发送过来的数据流,最终合并后 sink 到控制台。
命令:cd /hadoop/Flume/apache-flume-1.9.0-bin/job
vi f3.conf

输入a或i进行编辑,在文件中添加以下内容。
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = app-13
a3.sources.r1.port = 4141
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
点击Ecs退出编辑,:wq保存退出
7.安装nc工具
命令:sudo yum install -y nc
8.执行配置文件
在app-11,app-12,app-13中的cd /hadoop/Flume/apache-flume-1.9.0-bin/目录下,分别开启对应配置文件f1.conf、 f2.conf、f3.conf


app-13:
命令:flume-ng agent --name a3 --conf-file job/f3.conf -Dflume.root.logger=INFO,console
app-12:
命令:flume-ng agent --name a2 --conf-file job/f2.conf
app-11:
命令:flume-ng agent --name a1 --conf-file job/f1.conf
9.重新开一个终端,登录app-12
命令:ssh app-12
上向 44444 端口发送数据
命令:nc app-12 44444
输入bcd,回车

10.在 app-11上/hadoop/test 目录下的 group.log 追加内容
命令:cd test
echo abc >> group.log

11.检查app-13 上的数据
 详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰

1.前言
1.1为什么产生数据湖

数据量比较大,越来越不满足处理结构化的数据,比如说数仓,数仓就是处理结构化数据。什么是结构化数据,就是数据成数据库来的,传统型的数据库有:MySQL数据库、Oracle、SQLserver,从这些库里面过来的数据都是结构化数据。日志、json、xml是属于半结构化数据,结构化数据和半结构化数据就是当前数仓所做的功能。数据湖的产生就是为了解决非结构化数据和二进制数据,主要就是处理非结构化数据,非结构化数据主要是:图片、视频、音频。
1.2数据湖的性能特点


1、新增支持特别快的新增和删除的功能
2、要有表的结构信息
3、本身就有小文件管理合并
4、保证语义等
1.3Hudi介绍
Hudi将带来流式处理大数据,提供新数据集,同时比传统批处理效率高一个数据量级。

1.4Hudi特性
1、快速upsert,可插入索引
2、以原子方式操作数据并具有回滚功能
3、写入器之间的快照隔离
4、savepoint用户数据恢复的保存点
5、管理文件大小,使用统计数据布局
6、数据行的异步压缩和柱状数据
7、时间数据跟踪血统
2.数据湖的定义
1、 数据湖需要提供足够用的数据存储能力,这个存储保存了一个企业/组织中的所有数据。
2、 数据湖可以存储海量的任意类型的数据,包括结构化、半结构化和非结构化数据。
3、 数据湖中的数据是原始数据,是业务数据的完整副本。数据湖中的数据保持了他们在业务系统中原来的样子。
4、 数据湖需要具备完善的数据管理能力(完善的元数据),可以管理各类数据相关的要素,包括数据源、数据格式、连接信息、数据schema、权限管理等。
5、 数据湖需要具备多样化的分析能力,包括但不限于批处理、流式计算、交互式分析以及机器学习;同时,还需要提供一定的任务调度和管理能力。
6、 数据湖需要具备完善的数据生命周期管理能力。不光需要存储原始数据,还需要能够保存各类分析处理的中间结果,并完整的记录数据的分析处理过程,能帮助用户完整详细追溯任意一条数据的产生过程。
7、 数据湖需要具备完善的数据获取和数据发布能力。数据湖需要能支撑各种各样的数据源,并能从相关的数据源中获取全量/增量数据;然后规范存储。数据湖能将数据分析处理的结果推送到合适的存储引擎中,满足不同的应用访问需求。
8、 对于大数据的支持,包括超大规模存储以及可扩展的大规模数据处理能力。
综上,个人认为数据湖应该是一种不断演进中、可扩展的大数据存储、处理、分析的基础设施;以数据为导向,实现任意来源、任意速度、任意规模、任意类型数据的全量获取、全量存储、多模式处理与全生命周期管理;并通过与各类外部异构数据源的交互集成,支持各类企业级应用。

上图数据湖基本能力示意
这里需要再特别指出两点:
1)可扩展是指规模的可扩展和能力的可扩展,即数据湖不但要能够随着数据量的增大,提供“足够”的存储和计算能力;还需要根据需要不断提供新的数据处理模式,例如可能一开始业务只需要批处理能力,但随着业务的发展,可能需要交互式的即席分析能力;又随着业务的实效性要求不断提升,可能需要支持实时分析和机器学习等丰富的能力。
2)以数据为导向,是指数据湖对于用户来说要足够的简单、易用,帮助用户从复杂的IT基础设施运维工作中解脱出来,关注业务、关注模型、关注算法、关注数据。数据湖面向的是数据科学家、分析师。目前来看,云原生应该是构建数据湖的一种比较理想的构建方式,后面在“数据湖基本架构”一节会详细论述这一观点。
3.数据湖基本架构
数据湖可以认为是新一代的大数据基础设施。为了更好的理解数据湖的基本架构,我们先来看看大数据基础设施架构的演进过程。
1) 第一阶段:以Hadoop为代表的离线数据处理基础设施。如下图所示,Hadoop是以HDFS为核心存储,以MapReduce(简称MR)为基本计算模型的批量数据处理基础设施。围绕HDFS和MR,产生了一系列的组件,不断完善整个大数据平台的数据处理能力,例如面向在线KV操作的HBase、面向SQL的HIVE、面向工作流的PIG等。同时,随着大家对于批处理的性能要求越来越高,新的计算模型不断被提出,产生了Tez、Spark、Presto等计算引擎,MR模型也逐渐进化成DAG模型。DAG模型一方面,增加计算模型的抽象并发能力:对每一个计算过程进行分解,根据计算过程中的聚合操作点对任务进行逻辑切分,任务被切分成一个个的stage,每个stage都可以有一个或者多个Task组成,Task是可以并发执行的,从而提升整个计算过程的并行能力;另一方面,为减少数据处理过程中的中间结果写文件操作,Spark、Presto等计算引擎尽量使用计算节点的内存对数据进行缓存,从而提高整个数据过程的效率和系统吞吐能力。

如上图. Hadoop体系结构示意
2) 第二阶段:lambda架构。随着数据处理能力和处理需求的不断变化,越来越多的用户发现,批处理模式无论如何提升性能,也无法满足一些实时性要求高的处理场景,流式计算引擎应运而生,例如Storm、Spark Streaming、Flink等。然而,随着越来越多的应用上线,大家发现,其实批处理和流计算配合使用,才能满足大部分应用需求;而对于用户而言,其实他们并不关心底层的计算模型是什么,用户希望无论是批处理还是流计算,都能基于统一的数据模型来返回处理结果,于是Lambda架构被提出,如下图所示。

Lambda架构示意
Lambda架构的核心理念是“流批一体”,如上图所示,整个数据流向自左向右流入平台。进入平台后一分为二,一部分走批处理模式,一部分走流式计算模式。无论哪种计算模式,最终的处理结果都通过服务层对应用提供,确保访问的一致性。
3) 第三阶段:Kappa架构。Lambda架构解决了应用读取数据的一致性问题,但是“流批分离”的处理链路增大了研发的复杂性。因此,有人就提出能不能用一套系统来解决所有问题。目前比较流行的做法就是基于流计算来做。流计算天然的分布式特征,注定了他的扩展性更好。通过加大流计算的并发性,加大流式数据的“时间窗口”,来统一批处理与流式处理两种计算模式。

Kappa架构示意
综上,从传统的hadoop架构往lambda架构,从lambda架构往Kappa架构的演进,大数据平台基础架构的演进逐渐囊括了应用所需的各类数据处理能力,大数据平台逐渐演化成了一个企业/组织的全量数据处理平台。当前的企业实践中,除了关系型数据库依托于各个独立的业务系统;其余的数据,几乎都被考虑纳入大数据平台来进行统一的处理。然而,目前的大数据平台基础架构,都将视角锁定在了存储和计算,而忽略了对于数据的资产化管理,这恰恰是数据湖作为新一代的大数据基础设施所重点关注的方向之一。
大数据基础架构的演进,其实反应了一点:在企业/组织内部,数据是一类重要资产已经成为了共识:
为了更好的利用数据,企业/组织需要对数据资产
1)进行长期的原样存储;
2)进行有效管理与集中治理;
3)提供多模式的计算能力满足处理需求;
4)以及面向业务,提供统一的数据视图、数据模型与数据处理结果。数据湖就是在这个大背景下产生的,除了大数据平台所拥有的各类基础能力之外,数据湖更强调对于数据的管理、治理和资产化能力。
落到具体的实现上,数据湖需要包括一系列的数据管理组件,包括:
1)数据接入;
2)数据搬迁;
3)数据治理;
4)质量管理;
5)资产目录;
6)访问控制;
7)任务管理;
8)任务编排;
9)元数据管理等。如下图所示,给出了一个数据湖系统的参考架构。对于一个典型的数据湖而言,它与大数据平台相同的地方在于它也具备处理超大规模数据所需的存储和计算能力,能提供多模式的数据处理能力;增强点在于数据湖提供了更为完善的数据管理能力,具体体现在:
1) 更强大的数据接入能力。数据接入能力体现在对于各类外部异构数据源的定义管理能力,以及对于外部数据源相关数据的抽取迁移能力,抽取迁移的数据包括外部数据源的元数据与实际存储的数据。
2) 更强大的数据管理能力。管理能力具体又可分为基本管理能力和扩展管理能力。基本管理能力包括对各类元数据的管理、数据访问控制、数据资产管理,是一个数据湖系统所必须的,后面我们会在“各厂商的数据湖解决方案”一节相信讨论各个厂商对于基本管理能力的支持方式。扩展管理能力包括任务管理、流程编排以及与数据质量、数据治理相关的能力。任务管理和流程编排主要用来管理、编排、调度、监测在数据湖系统中处理数据的各类任务,通常情况下,数据湖构建者会通过购买/研制定制的数据集成或数据开发子系统/模块来提供此类能力,定制的系统/模块可以通过读取数据湖的相关元数据,来实现与数据湖系统的融合。而数据质量和数据治理则是更为复杂的问题,一般情况下,数据湖系统不会直接提供相关功能,但是会开放各类接口或者元数据,供有能力的企业/组织与已有的数据治理软件集成或者做定制开发。
3) 可共享的元数据。数据湖中的各类计算引擎会与数据湖中的数据深度融合,而融合的基础就是数据湖的元数据。好的数据湖系统,计算引擎在处理数据时,能从元数据中直接获取数据存储位置、数据格式、数据模式、数据分布等信息,然后直接进行数据处理,而无需进行人工/编程干预。更进一步,好的数据湖系统还可以对数据湖中的数据进行访问控制,控制的力度可以做到“库表列行”等不同级别。

数据湖组件参考架构
还有一点应该指出的是,上图的“集中式存储”更多的是业务概念上的集中,本质上是希望一个企业/组织内部的数据能在一个明确统一的地方进行沉淀。事实上,数据湖的存储应该是一类可按需扩展的分布式文件系统,大多数数据湖实践中也是推荐采用S3/OSS/OBS/HDFS等分布式系统作为数据湖的统一存储。
我们可以再切换到数据维度,从数据生命周期的视角来看待数据湖对于数据的处理方式,数据在数据湖中的整个生命周期如图6所示。理论上,一个管理完善的数据湖中的数据会永久的保留原始数据,同时过程数据会不断的完善、演化,以满足业务的需要。

数据湖中的数据生命周期示意
3.Upsert场景执行流程介绍
对于Hudi Upsert 操作整理了比较核心的几个操作如下图所示

1.开始提交:判断上次任务是否失败,如果失败会触发回滚操作。然后会根据当前时间生成一个事务开始的请求标识元数据。 2.构造HoodieRecord Rdd对象:Hudi 会根据元数据信息构造HoodieRecord Rdd 对象,方便后续数据去重和数据合并。 3.数据去重:一批增量数据中可能会有重复的数据,Hudi会根据主键对数据进行去重避免重复数据写入Hudi 表。 4.数据fileId位置信息获取:在修改记录中可以根据索引获取当前记录所属文件的fileid,在数据合并时需要知道数据update操作向那个fileId文件写入新的快照文件。 5.数据合并:Hudi 有两种模式cow和mor。在cow模式中会重写索引命中的fileId快照文件;在mor 模式中根据fileId 追加到分区中的log 文件。 6.完成提交:在元数据中生成xxxx.commit文件,只有生成commit 元数据文件,查询引擎才能根据元数据查询到刚刚upsert 后的数据。 7.compaction压缩:主要是mor 模式中才会有,他会将mor模式中的xxx.log 数据合并到xxx.parquet 快照文件中去。 8.hive元数据同步:hive 的元素数据同步这个步骤需要配置非必需操作,主要是对于hive 和presto 等查询引擎,需要依赖hive 元数据才能进行查询,所以hive元数据同步就是构造外表提供查询。

介绍完Hudi的upsert运行流程,再来看下Hudi如何进行存储并且保证事务,在每次upsert完成后都会产生commit 文件记录每次重新的快照文件。
例如上图
时间1初始化写入三个分区文件分别是xxx-1.parquet;
时间3场景如果会修改分区1和分区2xxx-1.parquet的数据,那么写入完成后会生成新的快照文件分别是分区1和分区2xxx-3.parquet文件。(上述是COW模式的过程,而对于MOR模式的更新会生成log文件,如果log文件存在并且可追加则继续追加数据)。
时间5修改分区1的数据那么同理会生成分区1下的新快照文件。
可以看出对于Hudi 每次修改都是会在文件级别重新写入数据快照。查询的时候就会根据最后一次快照元数据加载每个分区小于等于当前的元数据的parquet文件。Hudi事务的原理就是通过元数据mvcc多版本控制写入新的快照文件,在每个时间阶段根据最近的元数据查找快照文件。因为是重写数据所以同一时间只能保证一个事务去重写parquet 文件。不过当前Hudi版本加入了并发写机制,原理是Zookeeper分布锁控制或者HMS提供锁的方式, 会保证同一个文件的修改只有一个事务会写入成功。
下面将根据Spark 调用write方法深入剖析upsert操作每个步骤的执行流程。
3.1开始提交&数据回滚
在构造好spark 的rdd 后会调用 df.write.format("hudi") 方法执行数据的写入,实际会调用Hudi源码中的HoodieSparkSqlWriter#write方法实现。在执行任务前Hudi 会创建HoodieWriteClient 对象,并构造HoodieTableMetaClient调用startCommitWithTime方法开始一次事务。在开始提交前会获取hoodie 目录下的元数据信息,判断上一次写入操作是否成功,判断的标准是上次任务的快照元数据有xxx.commit后缀的元数据文件。如果不存在那么Hudi 会触发回滚机制,回滚是将不完整的事务元数据文件删除,并新建xxx.rollback元数据文件。如果有数据写入到快照parquet 文件中也会一起删除。

3.2 构造HoodieRecord Rdd 对象
HoodieRecord Rdd 对象的构造先是通过map 算子提取spark dataframe中的schema和数据,构造avro的GenericRecords Rdd,然后Hudi会在使用map算子封装为HoodierRecord Rdd。对于HoodileRecord Rdd 主要由currentLocation,newLocation,hoodieKey,data 组成。HoodileRecord数据结构是为后续数据去重和数据合并时提供基础。

•currentLocation 当前数据位置信息:只有数据在当前Hudi表中存在才会有,主要存放parquet文件的fileId,构造时默认为空,在查找索引位置信息时被赋予数据。
•newLocation 数据新位置信息:与currentLocation不同不管是否存在都会被赋值,newLocation是存放当前数据需要被写入到那个fileID文件中的位置信息,构造时默认为空,在merge阶段会被赋予位置信息。 •HoodieKey 主键信息:主要包含recordKey 和patitionPath 。recordkey 是由hoodie.datasource.write.recordkey.field 配置项根据列名从记录中获取的主键值。patitionPath 是分区路径。Hudi 会根据hoodie.datasource.write.partitionpath.field 配置项的列名从记录中获取的值作为分区路径。 •data 数据:data是一个泛型对象,泛型对象需要实现HoodieRecordPayload类,主要是实现合并方法和比较方法。默认实现OverwriteWithLatestAvroPayload类,需要配置hoodie.datasource.write.precombine.field配置项获取记录中列的值用于比较数据大小,去重和合并都是需要保留值最大的数据。
3.3 数据去重
在upsert 场景中数据去重是默认要做的操作,如果不进行去重会导致数据重复写入parquet文件中。当然upsert 数据中如果没有重复数据是可以关闭去重操作。配置是否去重参数为hoodie.combine.before.upsert,默认为true开启。

在Spark client调用upsert 操作是Hudi会创建HoodieTable对象,并且调用upsert 方法。对于HooideTable 的实现分别有COW和MOR两种模式的实现。但是在数据去重阶段和索引查找阶段的操作都是一样的。调用HoodieTable#upsert方法底层的实现都是SparkWriteHelper。
在去重操作中,会先使用map 算子提取HoodieRecord中的HoodieatestAvroPayload的实现是保留时间戳最大的记录。这里要注意如果我们配置的是全局类型的索引,map 中的key 值是 HoodieKey 对象中的recordKey。因为全局索引是需要保证所有分区中的主键都是唯一的,避免不同分区数据重复。当然如果是非分区表,没有必要使用全局索引。
3.4 数据位置信息索引查找
对于Hudi 索引主要分为两大类:
•非全局索引:索引在查找数据位置信息时,只会检索当前分区的索引,索引只保证当前分区内数据做upsert。如果记录的分区值发生变更就会导致数据重复。 •全局索引:顾名思义在查找索引时会加载所有分区的索引,用于定位数据位置信息,即使发生分区值变更也能定位数据位置信息。这种方式因为要加载所有分区文件的索引,对查找性能会有影响(HBase索引除外)。

Spark 索引实现主要有如下几种
•布隆索引(BloomIndex) •全局布隆索引(GlobalBloomIndex) •简易索引(SimpleIndex) •简易全局索引(GlobalSimpleIndex) •全局HBase 索引(HbaseIndex) •内存索引(InMemoryHashIndex)。
3.4.1 索引的选择
普通索引:主要用于非分区表和分区不会发生分区列值变更的表。当然如果你不关心多分区主键重复的情况也是可以使用。他的优势是只会加载upsert数据中的分区下的每个文件中的索引,相对于全局索引需要扫描的文件少。并且索引只会命中当前分区的fileid 文件,需要重写的快照也少相对全局索引高效。但是某些情况下我们的设置的分区列的值就是会变那么必须要使用全局索引保证数据不重复,这样upsert 写入速度就会慢一些。其实对于非分区表他就是个分区列值不会变且只有一个分区的表,很适合普通索引,如果非分区表硬要用全局索引其实和普通索引性能和效果是一样的。
全局索引:分区表场景要考虑分区值变更,需要加载所有分区文件的索引比普通索引慢。
布隆索引:加载fileid 文件页脚布隆过滤器,加载少量数据数据就能判断数据是否在文件存在。缺点是有一定的误判,但是merge机制可以避免重复数据写入。parquet文件多会影响索引加载速度。适合没有分区变更和非分区表。主键如果是类似自增的主键布隆索引可以提供更高的性能,因为布隆索引记录的有最大key和最小key加速索引查找。
全局布隆索引:解决分区变更场景,原理和布隆索引一样,在分区表中比普通布隆索引慢。
简易索引:直接加载文件里的数据不会像布隆索引一样误判,但是加载的数据要比布隆索引要多,left join 关联的条数也要比布隆索引多。大多数场景没布隆索引高效,但是极端情况命中所有的parquet文件,那么此时还不如使用简易索引加载所有文件里的数据进行判断。
全局简易索引:解决分区变更场景,原理和简易索引一样,在分区表中比普通简易索引慢。建议优先使用全局布隆索引。
HBase索引:不受分区变跟场景的影响,操作算子要比布隆索引少,在大量的分区和文件的场景中比布隆全局索引高效。因为每条数据都要查询hbase ,upsert数据量很大会对hbase有负载的压力需要考虑hbase集群承受压力,适合微批分区表的写入场景 。在非分区表中数量不大文件也少,速度和布隆索引差不多,这种情况建议用布隆索引。
内存索引:用于测试不适合生产环境
3.5数据合并
COW模式和MOR模式在前面的操作都是一样的,不过在合并的时候Hudi构造的执行器不同。对于COW会根据位置信息中fileId 重写parquet文件,在重写中如果数据是更新会比较parquet文件的数据和当前的数据的大小进行更新,完成更新数据和插入数据。而MOR模式会根据fileId 生成一个log 文件,将数据直接写入到log文件中,如果fileID的log文件已经存在,追加数据写入到log 文件中。与COW 模式相比少了数据比较的工作所以性能要好,但是在log 文件中可能保存多次写有重复数据在读log数据时候就不如cow模式了。还有在mor模式中log文件和parquet 文件都是存在的,log 文件的数据会达到一定条件和parqeut 文件合并。所以mor有两个视图,ro后缀的视图是读优化视图(read-optimized)只查询parquet 文件的数据。rt后缀的视图是实时视图(real-time)查询parquet 和log 日志中的内容。
3.5.1 Copy on Write模式
COW模式数据合并实现逻辑调用BaseSparkCommitActionExecutor#excute方法,实现步骤如下:

1.通过countByKey 算子提取分区路径和文件位置信息并统计条数,用于后续根据分区文件写入的数据量大小评估如何分桶。 2.统计完成后会将结果写入到workLoadProfile 对象的map 中,这个时候已经完成合并数据的前置条件。Hudi会调用saveWorkloadProfileMetadataToInfilght 方法写入infight标识文件到.hoodie元数据目录中。在workLoadProfile的统计信息中套用的是类似双层map数据结构, 统计是到fileid 文件级别。 3.根据workLoadProfile统计信息生成自定义分区 ,这个步骤就是分桶的过程。首先会对更新的数据做分桶,因为是更新数据在合并时要么覆盖老数据要么丢弃,所以不存在parquet文件过于膨胀,这个过程会给将要发生修改的fileId都会添加一个桶。然后会对新增数据分配桶,新增数据分桶先获取分区路径下所有的fileid 文件, 判断数据是否小于100兆。小于100兆会被认为是小文件后续新增数据会被分配到这个文件桶中,大于100兆的文件将不会被分配桶。获取到小文件后会计算每个fileid 文件还能存少数据然后分配一个桶。如果小文件fileId 的桶都分配完了还不够会根据数据量大小分配n个新增桶。最后分好桶后会将桶信息存入一个map 集合中,当调用自定义实现getpartition方法时直接向map 中获取。所以spark在运行的时候一个桶会对应一个分区的合并计算。
4.分桶结束后调用handleUpsertPartition合并数据。首先会获取map 集合中的桶信息,桶类型有两种新增和修改两种。如果桶fileid文件只有新增数据操作,直接追加文件或新建parquet文件写入就好,这里会调用handleInsert方法。如果桶fileid文件既有新增又有修改或只有修改一定会走handUpdate方法。这里设计的非常的巧妙对于新增多修改改少的场景大部分的数据直接可以走新增的逻辑可以很好的提升性能。对于handUpdate方法的处理会先构造HoodieMergeHandle对象初始化一个map集合,这个map集合很特殊拥有存在内存的map集合和存在磁盘的map 集合,这个map集合是用来存放所有需要update数据的集合用来遍历fileid旧文件时查询文件是否存在要不要覆盖旧数据。这里使用内存加磁盘为了避免update桶中数据特别大情况可以将一部分存磁盘避免jvm oom。update 数据会优先存放到内存map如果内存map不够才会存在磁盘map,而内存Map默认大小是1g 。DiskBasedMap 存储是key信息存放的还是record key ,value 信息存放value 的值存放到那个文件上,偏移量是多少、存放大小和时间。这样如果命中了磁盘上map就可以根据value存放的信息去获取hoodieRecord了。
5.构造sparkMergHelper 开始合并数据写入到新的快照文件。在SparkMergHelper 内部会构造一个BoundedInMemoryExecutor 的队列,在这个队列中会构造多个生产者和一个消费者(file 文件一般情况只有一个文件所以生产者也会是一个)。producers 会加载老数据的fileId文件里的数据构造一个迭代器,执行的时候先调用producers 完成初始化后调用consumer。而consumer被调用后会比较数据是否存在ExternalSpillableMap 中如果不存在重新写入数据到新的快照文件,如果存在调用当前的HoodileRecordPayload 实现类combineAndGetUpdateValue 方法进行比较来确定是写入老数据还是新数据,默认比较那个数据时间大。这里有个特别的场景就是硬删除,对于硬删除里面的数据是空的,比较后会直接忽略写入达到数据删除的目的。
3.5.2 Merge on Read模式
在MOR模式中的实现和前面COW模式分桶阶段逻辑相同,这里主要说下最后的合并和COW模式不一样的操作。在MOR合并是调用AbstarctSparkDeltaCommitActionExecutor#execute方法,会构造HoodieAppaendHandle对象。在写入时调用append向log日志文件追加数据,如果日志文件不存在或不可追加将新建log文件。
分桶相关参数与COW模式通用

3.6索引更新

数据写入到log文件或者是parquet 文件,这个时候需要更新索引。简易索引和布隆索引对于他们来说索引在parquet文件中是不需要去更新索引的。这里索引更新只有HBase索引和内存索引需要更新。内存索引是更新通过map 算子写入到内存map上,HBase索引通过map算子put到HBase上。
3.7完成提交
3.7.1 提交&元数据信息归档
上述操作如果都成功且写入时writeStatus中没有任何错误记录,Hudi 会进行完成事务的提交和元数据归档操作,步骤如下
1.sparkRddWriteClient 调用commit 方法,首先会向Hdfs 上提交一个.commit 后缀的文件,里面记录的是writeStatus的信息包括写入多少条数据、fileID快照的信息、Schema结构等等。当commit 文件写入成功就意味着一次upsert 已经成功,Hudi 内的数据就可以查询到。 2.为了不让元数据一直增长下去需要对元数据做归档操作。元数据归档会先创建HoodieTimelineArchiveLog对象,通过HoodieTableMetaClient 获取.hoodie目录下所有的元数据信息,根据这些元数据信息来判断是否达到归档条件。如果达到条件构造HooieLogFormatWrite对象对archived文件进行追加。每个元数据文件会封装成 HoodieLogBlock 对象批量写入。

3.7.2 数据清理
元数据清理后parquet 文件也是要去清理,在Hudi 有专有spark任务去清理文件。因为是通过spark 任务去清理文件也有对应XXX.clean.request、xxx.clean.infight、xxx.clean元数据来标识任务的每个任务阶段。数据清理步骤如下:
1.构造baseCleanPanActionExecutor 执行器,并调用requestClean方法获取元数据生成清理计划对象HoodieCleanPlan。判断HoodieCleanPlan对象满足触发条件会向元数据写入xxx.request 标识,表示可以开始清理计划。 2.生成执行计划后调用baseCleanPanActionExecutor 的继承类clean方法完成执行spark任务前的准备操作,然后向hdfs 写入xxx.clean.inflight对象准备执行spark任务。 3.spark 任务获取HoodieCleanPlan中所有分区序列化成为Rdd并调用flatMap迭代每个分区的文件。然后在mapPartitions算子中调用deleteFilesFunc方法删除每一个分区的过期的文件。最后reduceBykey汇总删除文件的结果构造成HoodieCleanStat对象,将结果元数据写入xxx.clean中完成数据清理。

3.7.3 数据压缩
数据压缩是mor 模式才会有的操作,目的是让log文件合并到新的fileId快照文件中。因为数据压缩也是spark 任务完成的,所以在运行时也对应的xxx.compaction.requet、xxx.compaction.clean、xxx.compaction元数据生成记录每个阶段。数据压缩实现步骤如下:
1.sparkRDDwirteClient 调用compaction方法构造BaseScheduleCompationActionExecutor对象并调用scheduleCompaction方法,计算是否满足数据压缩条件生成HoodieCompactionPlan执行计划元数据。如果满足条件会向hdfs 写入xxx.compation.request元数据标识请求提交spark任务。 2.BaseScheduleCompationActionExecutor会调用继承类SparkRunCompactionExecutor类并调用compact方法构造HoodieSparkMergeOnReadTableCompactor 对象来实现压缩逻辑,完成一切准备操作后向hdfs写入xxx.compation.inflight标识。 3.spark任务执行parallelize加载HooideCompactionPlan 的执行计划,然后调用compact迭代执行每个分区中log的合并逻辑。在 compact会构造HoodieMergelogRecordScanner 扫描文件对象,加载分区中的log构造迭代器遍历log中的数据写入ExtemalSpillableMap。这个ExtemalSpillableMap和cow 模式中内存加载磁盘的map 是一样的。至于合并逻辑是和cow模式的合并逻辑是一样的,这里不重复阐述都是调用cow模式的handleUpdate方法。 4.完成合并操作会构造writeStatus结果信息,并写入xxx.compaction标识到hdfs中完成合并操作。

3.8Hive元数据同步
实现原理比较简单就是根据Hive外表和Hudi表当前表结构和分区做比较,是否有新增字段和新增分区如果有会添加字段和分区到Hive外表。如果不同步Hudi新写入的分区无法查询。在COW模式中只会有ro表(读优化视图,而在mor模式中有ro表(读优化视图)和rt表(实时视图)。
3.9提交成功通知回调
当事务提交成功后向外部系统发送通知消息,通知的方式有两种,一种是发送http服务消息,一种是发送kafka消息。这个通知过程我们可以把清理操作、压缩操作、hive元数据操作,都交给外部系统异步处理或者做其他扩展。也可以自己实现HoodieWriteCommitCallback的接口自定义实现。
4.大数据技术和工具归类

部分术语翻译:
Administration: 管理平台(此处应指大数据管理平台)
Data Security: 数据安全
Data Governance: 数据管控
Data Computing: 数据计算
Data Collection: 数据采集
Data Storage: 数据存储
BI/DATA Visualization: 商务智能可视化/数据可视化
5.数据湖的功能
Data Ingestion(获取数据)
Data Storage(数据存储)
Data Auditing(数据审计)
Data Exploration(数据探索)
Data Lineage(数据继承)
Data Discovery(数据挖掘)
Data Governance(数据管理与处理)
Data Security(数据安全)
Data Quality(数据质量评估)

6.最后
本节篇幅过长,感谢阅读希望对您的学习有所帮助。
1.前言
1.1为什么产生数据湖
数据量比较大,越来越不满足处理结构化的数据,比如说数仓,数仓就是处理结构化数据。什么是结构化数据,就是数据成数据库来的,传统型的数据库有:MySQL数据库、Oracle、SQLserver,从这些库里面过来的数据都是结构化数据。日志、json、xml是属于半结构化数据,结构化数据和半结构化数据就是当前数仓所做的功能。数据湖的产生就是为了解决非结构化数据和二进制数据,主要就是处理非结构化数据,非结构化数据主要是:图片、视频、音频。
1.2数据湖的性能特点
1、新增支持特别快的新增和删除的功能
2、要有表的结构信息
3、本身就有小文件管理合并
4、保证语义等
1.3Hudi介绍
Hudi将带来流式处理大数据,提供新数据集,同时比传统批处理效率高一个数据量级。
1.4Hudi特性
1、快速upsert,可插入索引
2、以原子方式操作数据并具有回滚功能
3、写入器之间的快照隔离
4、savepoint用户数据恢复的保存点
5、管理文件大小,使用统计数据布局
6、数据行的异步压缩和柱状数据
7、时间数据跟踪血统
2.数据湖的定义
1、 数据湖需要提供足够用的数据存储能力,这个存储保存了一个企业/组织中的所有数据。
2、 数据湖可以存储海量的任意类型的数据,包括结构化、半结构化和非结构化数据。
3、 数据湖中的数据是原始数据,是业务数据的完整副本。数据湖中的数据保持了他们在业务系统中原来的样子。
4、 数据湖需要具备完善的数据管理能力(完善的元数据),可以管理各类数据相关的要素,包括数据源、数据格式、连接信息、数据schema、权限管理等。
5、 数据湖需要具备多样化的分析能力,包括但不限于批处理、流式计算、交互式分析以及机器学习;同时,还需要提供一定的任务调度和管理能力。
6、 数据湖需要具备完善的数据生命周期管理能力。不光需要存储原始数据,还需要能够保存各类分析处理的中间结果,并完整的记录数据的分析处理过程,能帮助用户完整详细追溯任意一条数据的产生过程。
7、 数据湖需要具备完善的数据获取和数据发布能力。数据湖需要能支撑各种各样的数据源,并能从相关的数据源中获取全量/增量数据;然后规范存储。数据湖能将数据分析处理的结果推送到合适的存储引擎中,满足不同的应用访问需求。
8、 对于大数据的支持,包括超大规模存储以及可扩展的大规模数据处理能力。
综上,个人认为数据湖应该是一种不断演进中、可扩展的大数据存储、处理、分析的基础设施;以数据为导向,实现任意来源、任意速度、任意规模、任意类型数据的全量获取、全量存储、多模式处理与全生命周期管理;并通过与各类外部异构数据源的交互集成,支持各类企业级应用。
上图数据湖基本能力示意
这里需要再特别指出两点:
1)可扩展是指规模的可扩展和能力的可扩展,即数据湖不但要能够随着数据量的增大,提供“足够”的存储和计算能力;还需要根据需要不断提供新的数据处理模式,例如可能一开始业务只需要批处理能力,但随着业务的发展,可能需要交互式的即席分析能力;又随着业务的实效性要求不断提升,可能需要支持实时分析和机器学习等丰富的能力。
2)以数据为导向,是指数据湖对于用户来说要足够的简单、易用,帮助用户从复杂的IT基础设施运维工作中解脱出来,关注业务、关注模型、关注算法、关注数据。数据湖面向的是数据科学家、分析师。目前来看,云原生应该是构建数据湖的一种比较理想的构建方式,后面在“数据湖基本架构”一节会详细论述这一观点。
3.数据湖基本架构
数据湖可以认为是新一代的大数据基础设施。为了更好的理解数据湖的基本架构,我们先来看看大数据基础设施架构的演进过程。
1) 第一阶段:以Hadoop为代表的离线数据处理基础设施。如下图所示,Hadoop是以HDFS为核心存储,以MapReduce(简称MR)为基本计算模型的批量数据处理基础设施。围绕HDFS和MR,产生了一系列的组件,不断完善整个大数据平台的数据处理能力,例如面向在线KV操作的HBase、面向SQL的HIVE、面向工作流的PIG等。同时,随着大家对于批处理的性能要求越来越高,新的计算模型不断被提出,产生了Tez、Spark、Presto等计算引擎,MR模型也逐渐进化成DAG模型。DAG模型一方面,增加计算模型的抽象并发能力:对每一个计算过程进行分解,根据计算过程中的聚合操作点对任务进行逻辑切分,任务被切分成一个个的stage,每个stage都可以有一个或者多个Task组成,Task是可以并发执行的,从而提升整个计算过程的并行能力;另一方面,为减少数据处理过程中的中间结果写文件操作,Spark、Presto等计算引擎尽量使用计算节点的内存对数据进行缓存,从而提高整个数据过程的效率和系统吞吐能力。
如上图. Hadoop体系结构示意
2) 第二阶段:lambda架构。随着数据处理能力和处理需求的不断变化,越来越多的用户发现,批处理模式无论如何提升性能,也无法满足一些实时性要求高的处理场景,流式计算引擎应运而生,例如Storm、Spark Streaming、Flink等。然而,随着越来越多的应用上线,大家发现,其实批处理和流计算配合使用,才能满足大部分应用需求;而对于用户而言,其实他们并不关心底层的计算模型是什么,用户希望无论是批处理还是流计算,都能基于统一的数据模型来返回处理结果,于是Lambda架构被提出,如下图所示。
Lambda架构示意
Lambda架构的核心理念是“流批一体”,如上图所示,整个数据流向自左向右流入平台。进入平台后一分为二,一部分走批处理模式,一部分走流式计算模式。无论哪种计算模式,最终的处理结果都通过服务层对应用提供,确保访问的一致性。
3) 第三阶段:Kappa架构。Lambda架构解决了应用读取数据的一致性问题,但是“流批分离”的处理链路增大了研发的复杂性。因此,有人就提出能不能用一套系统来解决所有问题。目前比较流行的做法就是基于流计算来做。流计算天然的分布式特征,注定了他的扩展性更好。通过加大流计算的并发性,加大流式数据的“时间窗口”,来统一批处理与流式处理两种计算模式。
Kappa架构示意
综上,从传统的hadoop架构往lambda架构,从lambda架构往Kappa架构的演进,大数据平台基础架构的演进逐渐囊括了应用所需的各类数据处理能力,大数据平台逐渐演化成了一个企业/组织的全量数据处理平台。当前的企业实践中,除了关系型数据库依托于各个独立的业务系统;其余的数据,几乎都被考虑纳入大数据平台来进行统一的处理。然而,目前的大数据平台基础架构,都将视角锁定在了存储和计算,而忽略了对于数据的资产化管理,这恰恰是数据湖作为新一代的大数据基础设施所重点关注的方向之一。
大数据基础架构的演进,其实反应了一点:在企业/组织内部,数据是一类重要资产已经成为了共识:
为了更好的利用数据,企业/组织需要对数据资产
1)进行长期的原样存储;
2)进行有效管理与集中治理;
3)提供多模式的计算能力满足处理需求;
4)以及面向业务,提供统一的数据视图、数据模型与数据处理结果。数据湖就是在这个大背景下产生的,除了大数据平台所拥有的各类基础能力之外,数据湖更强调对于数据的管理、治理和资产化能力。
落到具体的实现上,数据湖需要包括一系列的数据管理组件,包括:
1)数据接入;
2)数据搬迁;
3)数据治理;
4)质量管理;
5)资产目录;
6)访问控制;
7)任务管理;
8)任务编排;
9)元数据管理等。如下图所示,给出了一个数据湖系统的参考架构。对于一个典型的数据湖而言,它与大数据平台相同的地方在于它也具备处理超大规模数据所需的存储和计算能力,能提供多模式的数据处理能力;增强点在于数据湖提供了更为完善的数据管理能力,具体体现在:
1) 更强大的数据接入能力。数据接入能力体现在对于各类外部异构数据源的定义管理能力,以及对于外部数据源相关数据的抽取迁移能力,抽取迁移的数据包括外部数据源的元数据与实际存储的数据。
2) 更强大的数据管理能力。管理能力具体又可分为基本管理能力和扩展管理能力。基本管理能力包括对各类元数据的管理、数据访问控制、数据资产管理,是一个数据湖系统所必须的,后面我们会在“各厂商的数据湖解决方案”一节相信讨论各个厂商对于基本管理能力的支持方式。扩展管理能力包括任务管理、流程编排以及与数据质量、数据治理相关的能力。任务管理和流程编排主要用来管理、编排、调度、监测在数据湖系统中处理数据的各类任务,通常情况下,数据湖构建者会通过购买/研制定制的数据集成或数据开发子系统/模块来提供此类能力,定制的系统/模块可以通过读取数据湖的相关元数据,来实现与数据湖系统的融合。而数据质量和数据治理则是更为复杂的问题,一般情况下,数据湖系统不会直接提供相关功能,但是会开放各类接口或者元数据,供有能力的企业/组织与已有的数据治理软件集成或者做定制开发。
3) 可共享的元数据。数据湖中的各类计算引擎会与数据湖中的数据深度融合,而融合的基础就是数据湖的元数据。好的数据湖系统,计算引擎在处理数据时,能从元数据中直接获取数据存储位置、数据格式、数据模式、数据分布等信息,然后直接进行数据处理,而无需进行人工/编程干预。更进一步,好的数据湖系统还可以对数据湖中的数据进行访问控制,控制的力度可以做到“库表列行”等不同级别。
数据湖组件参考架构
还有一点应该指出的是,上图的“集中式存储”更多的是业务概念上的集中,本质上是希望一个企业/组织内部的数据能在一个明确统一的地方进行沉淀。事实上,数据湖的存储应该是一类可按需扩展的分布式文件系统,大多数数据湖实践中也是推荐采用S3/OSS/OBS/HDFS等分布式系统作为数据湖的统一存储。
我们可以再切换到数据维度,从数据生命周期的视角来看待数据湖对于数据的处理方式,数据在数据湖中的整个生命周期如图6所示。理论上,一个管理完善的数据湖中的数据会永久的保留原始数据,同时过程数据会不断的完善、演化,以满足业务的需要。
数据湖中的数据生命周期示意
3.Upsert场景执行流程介绍
对于Hudi Upsert 操作整理了比较核心的几个操作如下图所示
1.开始提交:判断上次任务是否失败,如果失败会触发回滚操作。然后会根据当前时间生成一个事务开始的请求标识元数据。 2.构造HoodieRecord Rdd对象:Hudi 会根据元数据信息构造HoodieRecord Rdd 对象,方便后续数据去重和数据合并。 3.数据去重:一批增量数据中可能会有重复的数据,Hudi会根据主键对数据进行去重避免重复数据写入Hudi 表。 4.数据fileId位置信息获取:在修改记录中可以根据索引获取当前记录所属文件的fileid,在数据合并时需要知道数据update操作向那个fileId文件写入新的快照文件。 5.数据合并:Hudi 有两种模式cow和mor。在cow模式中会重写索引命中的fileId快照文件;在mor 模式中根据fileId 追加到分区中的log 文件。 6.完成提交:在元数据中生成xxxx.commit文件,只有生成commit 元数据文件,查询引擎才能根据元数据查询到刚刚upsert 后的数据。 7.compaction压缩:主要是mor 模式中才会有,他会将mor模式中的xxx.log 数据合并到xxx.parquet 快照文件中去。 8.hive元数据同步:hive 的元素数据同步这个步骤需要配置非必需操作,主要是对于hive 和presto 等查询引擎,需要依赖hive 元数据才能进行查询,所以hive元数据同步就是构造外表提供查询。
介绍完Hudi的upsert运行流程,再来看下Hudi如何进行存储并且保证事务,在每次upsert完成后都会产生commit 文件记录每次重新的快照文件。
例如上图
时间1初始化写入三个分区文件分别是xxx-1.parquet;
时间3场景如果会修改分区1和分区2xxx-1.parquet的数据,那么写入完成后会生成新的快照文件分别是分区1和分区2xxx-3.parquet文件。(上述是COW模式的过程,而对于MOR模式的更新会生成log文件,如果log文件存在并且可追加则继续追加数据)。
时间5修改分区1的数据那么同理会生成分区1下的新快照文件。
可以看出对于Hudi 每次修改都是会在文件级别重新写入数据快照。查询的时候就会根据最后一次快照元数据加载每个分区小于等于当前的元数据的parquet文件。Hudi事务的原理就是通过元数据mvcc多版本控制写入新的快照文件,在每个时间阶段根据最近的元数据查找快照文件。因为是重写数据所以同一时间只能保证一个事务去重写parquet 文件。不过当前Hudi版本加入了并发写机制,原理是Zookeeper分布锁控制或者HMS提供锁的方式, 会保证同一个文件的修改只有一个事务会写入成功。
下面将根据Spark 调用write方法深入剖析upsert操作每个步骤的执行流程。
3.1开始提交&数据回滚
在构造好spark 的rdd 后会调用 df.write.format("hudi") 方法执行数据的写入,实际会调用Hudi源码中的HoodieSparkSqlWriter#write方法实现。在执行任务前Hudi 会创建HoodieWriteClient 对象,并构造HoodieTableMetaClient调用startCommitWithTime方法开始一次事务。在开始提交前会获取hoodie 目录下的元数据信息,判断上一次写入操作是否成功,判断的标准是上次任务的快照元数据有xxx.commit后缀的元数据文件。如果不存在那么Hudi 会触发回滚机制,回滚是将不完整的事务元数据文件删除,并新建xxx.rollback元数据文件。如果有数据写入到快照parquet 文件中也会一起删除。
3.2 构造HoodieRecord Rdd 对象
HoodieRecord Rdd 对象的构造先是通过map 算子提取spark dataframe中的schema和数据,构造avro的GenericRecords Rdd,然后Hudi会在使用map算子封装为HoodierRecord Rdd。对于HoodileRecord Rdd 主要由currentLocation,newLocation,hoodieKey,data 组成。HoodileRecord数据结构是为后续数据去重和数据合并时提供基础。
•currentLocation 当前数据位置信息:只有数据在当前Hudi表中存在才会有,主要存放parquet文件的fileId,构造时默认为空,在查找索引位置信息时被赋予数据。
•newLocation 数据新位置信息:与currentLocation不同不管是否存在都会被赋值,newLocation是存放当前数据需要被写入到那个fileID文件中的位置信息,构造时默认为空,在merge阶段会被赋予位置信息。 •HoodieKey 主键信息:主要包含recordKey 和patitionPath 。recordkey 是由hoodie.datasource.write.recordkey.field 配置项根据列名从记录中获取的主键值。patitionPath 是分区路径。Hudi 会根据hoodie.datasource.write.partitionpath.field 配置项的列名从记录中获取的值作为分区路径。 •data 数据:data是一个泛型对象,泛型对象需要实现HoodieRecordPayload类,主要是实现合并方法和比较方法。默认实现OverwriteWithLatestAvroPayload类,需要配置hoodie.datasource.write.precombine.field配置项获取记录中列的值用于比较数据大小,去重和合并都是需要保留值最大的数据。
3.3 数据去重
在upsert 场景中数据去重是默认要做的操作,如果不进行去重会导致数据重复写入parquet文件中。当然upsert 数据中如果没有重复数据是可以关闭去重操作。配置是否去重参数为hoodie.combine.before.upsert,默认为true开启。
在Spark client调用upsert 操作是Hudi会创建HoodieTable对象,并且调用upsert 方法。对于HooideTable 的实现分别有COW和MOR两种模式的实现。但是在数据去重阶段和索引查找阶段的操作都是一样的。调用HoodieTable#upsert方法底层的实现都是SparkWriteHelper。
在去重操作中,会先使用map 算子提取HoodieRecord中的HoodieatestAvroPayload的实现是保留时间戳最大的记录。这里要注意如果我们配置的是全局类型的索引,map 中的key 值是 HoodieKey 对象中的recordKey。因为全局索引是需要保证所有分区中的主键都是唯一的,避免不同分区数据重复。当然如果是非分区表,没有必要使用全局索引。
3.4 数据位置信息索引查找
对于Hudi 索引主要分为两大类:
•非全局索引:索引在查找数据位置信息时,只会检索当前分区的索引,索引只保证当前分区内数据做upsert。如果记录的分区值发生变更就会导致数据重复。 •全局索引:顾名思义在查找索引时会加载所有分区的索引,用于定位数据位置信息,即使发生分区值变更也能定位数据位置信息。这种方式因为要加载所有分区文件的索引,对查找性能会有影响(HBase索引除外)。
Spark 索引实现主要有如下几种
•布隆索引(BloomIndex) •全局布隆索引(GlobalBloomIndex) •简易索引(SimpleIndex) •简易全局索引(GlobalSimpleIndex) •全局HBase 索引(HbaseIndex) •内存索引(InMemoryHashIndex)。
3.4.1 索引的选择
普通索引:主要用于非分区表和分区不会发生分区列值变更的表。当然如果你不关心多分区主键重复的情况也是可以使用。他的优势是只会加载upsert数据中的分区下的每个文件中的索引,相对于全局索引需要扫描的文件少。并且索引只会命中当前分区的fileid 文件,需要重写的快照也少相对全局索引高效。但是某些情况下我们的设置的分区列的值就是会变那么必须要使用全局索引保证数据不重复,这样upsert 写入速度就会慢一些。其实对于非分区表他就是个分区列值不会变且只有一个分区的表,很适合普通索引,如果非分区表硬要用全局索引其实和普通索引性能和效果是一样的。
全局索引:分区表场景要考虑分区值变更,需要加载所有分区文件的索引比普通索引慢。
布隆索引:加载fileid 文件页脚布隆过滤器,加载少量数据数据就能判断数据是否在文件存在。缺点是有一定的误判,但是merge机制可以避免重复数据写入。parquet文件多会影响索引加载速度。适合没有分区变更和非分区表。主键如果是类似自增的主键布隆索引可以提供更高的性能,因为布隆索引记录的有最大key和最小key加速索引查找。
全局布隆索引:解决分区变更场景,原理和布隆索引一样,在分区表中比普通布隆索引慢。
简易索引:直接加载文件里的数据不会像布隆索引一样误判,但是加载的数据要比布隆索引要多,left join 关联的条数也要比布隆索引多。大多数场景没布隆索引高效,但是极端情况命中所有的parquet文件,那么此时还不如使用简易索引加载所有文件里的数据进行判断。
全局简易索引:解决分区变更场景,原理和简易索引一样,在分区表中比普通简易索引慢。建议优先使用全局布隆索引。
HBase索引:不受分区变跟场景的影响,操作算子要比布隆索引少,在大量的分区和文件的场景中比布隆全局索引高效。因为每条数据都要查询hbase ,upsert数据量很大会对hbase有负载的压力需要考虑hbase集群承受压力,适合微批分区表的写入场景 。在非分区表中数量不大文件也少,速度和布隆索引差不多,这种情况建议用布隆索引。
内存索引:用于测试不适合生产环境
3.5数据合并
COW模式和MOR模式在前面的操作都是一样的,不过在合并的时候Hudi构造的执行器不同。对于COW会根据位置信息中fileId 重写parquet文件,在重写中如果数据是更新会比较parquet文件的数据和当前的数据的大小进行更新,完成更新数据和插入数据。而MOR模式会根据fileId 生成一个log 文件,将数据直接写入到log文件中,如果fileID的log文件已经存在,追加数据写入到log 文件中。与COW 模式相比少了数据比较的工作所以性能要好,但是在log 文件中可能保存多次写有重复数据在读log数据时候就不如cow模式了。还有在mor模式中log文件和parquet 文件都是存在的,log 文件的数据会达到一定条件和parqeut 文件合并。所以mor有两个视图,ro后缀的视图是读优化视图(read-optimized)只查询parquet 文件的数据。rt后缀的视图是实时视图(real-time)查询parquet 和log 日志中的内容。
3.5.1 Copy on Write模式
COW模式数据合并实现逻辑调用BaseSparkCommitActionExecutor#excute方法,实现步骤如下:
1.通过countByKey 算子提取分区路径和文件位置信息并统计条数,用于后续根据分区文件写入的数据量大小评估如何分桶。 2.统计完成后会将结果写入到workLoadProfile 对象的map 中,这个时候已经完成合并数据的前置条件。Hudi会调用saveWorkloadProfileMetadataToInfilght 方法写入infight标识文件到.hoodie元数据目录中。在workLoadProfile的统计信息中套用的是类似双层map数据结构, 统计是到fileid 文件级别。 3.根据workLoadProfile统计信息生成自定义分区 ,这个步骤就是分桶的过程。首先会对更新的数据做分桶,因为是更新数据在合并时要么覆盖老数据要么丢弃,所以不存在parquet文件过于膨胀,这个过程会给将要发生修改的fileId都会添加一个桶。然后会对新增数据分配桶,新增数据分桶先获取分区路径下所有的fileid 文件, 判断数据是否小于100兆。小于100兆会被认为是小文件后续新增数据会被分配到这个文件桶中,大于100兆的文件将不会被分配桶。获取到小文件后会计算每个fileid 文件还能存少数据然后分配一个桶。如果小文件fileId 的桶都分配完了还不够会根据数据量大小分配n个新增桶。最后分好桶后会将桶信息存入一个map 集合中,当调用自定义实现getpartition方法时直接向map 中获取。所以spark在运行的时候一个桶会对应一个分区的合并计算。
4.分桶结束后调用handleUpsertPartition合并数据。首先会获取map 集合中的桶信息,桶类型有两种新增和修改两种。如果桶fileid文件只有新增数据操作,直接追加文件或新建parquet文件写入就好,这里会调用handleInsert方法。如果桶fileid文件既有新增又有修改或只有修改一定会走handUpdate方法。这里设计的非常的巧妙对于新增多修改改少的场景大部分的数据直接可以走新增的逻辑可以很好的提升性能。对于handUpdate方法的处理会先构造HoodieMergeHandle对象初始化一个map集合,这个map集合很特殊拥有存在内存的map集合和存在磁盘的map 集合,这个map集合是用来存放所有需要update数据的集合用来遍历fileid旧文件时查询文件是否存在要不要覆盖旧数据。这里使用内存加磁盘为了避免update桶中数据特别大情况可以将一部分存磁盘避免jvm oom。update 数据会优先存放到内存map如果内存map不够才会存在磁盘map,而内存Map默认大小是1g 。DiskBasedMap 存储是key信息存放的还是record key ,value 信息存放value 的值存放到那个文件上,偏移量是多少、存放大小和时间。这样如果命中了磁盘上map就可以根据value存放的信息去获取hoodieRecord了。
5.构造sparkMergHelper 开始合并数据写入到新的快照文件。在SparkMergHelper 内部会构造一个BoundedInMemoryExecutor 的队列,在这个队列中会构造多个生产者和一个消费者(file 文件一般情况只有一个文件所以生产者也会是一个)。producers 会加载老数据的fileId文件里的数据构造一个迭代器,执行的时候先调用producers 完成初始化后调用consumer。而consumer被调用后会比较数据是否存在ExternalSpillableMap 中如果不存在重新写入数据到新的快照文件,如果存在调用当前的HoodileRecordPayload 实现类combineAndGetUpdateValue 方法进行比较来确定是写入老数据还是新数据,默认比较那个数据时间大。这里有个特别的场景就是硬删除,对于硬删除里面的数据是空的,比较后会直接忽略写入达到数据删除的目的。
3.5.2 Merge on Read模式
在MOR模式中的实现和前面COW模式分桶阶段逻辑相同,这里主要说下最后的合并和COW模式不一样的操作。在MOR合并是调用AbstarctSparkDeltaCommitActionExecutor#execute方法,会构造HoodieAppaendHandle对象。在写入时调用append向log日志文件追加数据,如果日志文件不存在或不可追加将新建log文件。
分桶相关参数与COW模式通用
3.6索引更新
数据写入到log文件或者是parquet 文件,这个时候需要更新索引。简易索引和布隆索引对于他们来说索引在parquet文件中是不需要去更新索引的。这里索引更新只有HBase索引和内存索引需要更新。内存索引是更新通过map 算子写入到内存map上,HBase索引通过map算子put到HBase上。
3.7完成提交
3.7.1 提交&元数据信息归档
上述操作如果都成功且写入时writeStatus中没有任何错误记录,Hudi 会进行完成事务的提交和元数据归档操作,步骤如下
1.sparkRddWriteClient 调用commit 方法,首先会向Hdfs 上提交一个.commit 后缀的文件,里面记录的是writeStatus的信息包括写入多少条数据、fileID快照的信息、Schema结构等等。当commit 文件写入成功就意味着一次upsert 已经成功,Hudi 内的数据就可以查询到。 2.为了不让元数据一直增长下去需要对元数据做归档操作。元数据归档会先创建HoodieTimelineArchiveLog对象,通过HoodieTableMetaClient 获取.hoodie目录下所有的元数据信息,根据这些元数据信息来判断是否达到归档条件。如果达到条件构造HooieLogFormatWrite对象对archived文件进行追加。每个元数据文件会封装成 HoodieLogBlock 对象批量写入。
3.7.2 数据清理
元数据清理后parquet 文件也是要去清理,在Hudi 有专有spark任务去清理文件。因为是通过spark 任务去清理文件也有对应XXX.clean.request、xxx.clean.infight、xxx.clean元数据来标识任务的每个任务阶段。数据清理步骤如下:
1.构造baseCleanPanActionExecutor 执行器,并调用requestClean方法获取元数据生成清理计划对象HoodieCleanPlan。判断HoodieCleanPlan对象满足触发条件会向元数据写入xxx.request 标识,表示可以开始清理计划。 2.生成执行计划后调用baseCleanPanActionExecutor 的继承类clean方法完成执行spark任务前的准备操作,然后向hdfs 写入xxx.clean.inflight对象准备执行spark任务。 3.spark 任务获取HoodieCleanPlan中所有分区序列化成为Rdd并调用flatMap迭代每个分区的文件。然后在mapPartitions算子中调用deleteFilesFunc方法删除每一个分区的过期的文件。最后reduceBykey汇总删除文件的结果构造成HoodieCleanStat对象,将结果元数据写入xxx.clean中完成数据清理。
3.7.3 数据压缩
数据压缩是mor 模式才会有的操作,目的是让log文件合并到新的fileId快照文件中。因为数据压缩也是spark 任务完成的,所以在运行时也对应的xxx.compaction.requet、xxx.compaction.clean、xxx.compaction元数据生成记录每个阶段。数据压缩实现步骤如下:
1.sparkRDDwirteClient 调用compaction方法构造BaseScheduleCompationActionExecutor对象并调用scheduleCompaction方法,计算是否满足数据压缩条件生成HoodieCompactionPlan执行计划元数据。如果满足条件会向hdfs 写入xxx.compation.request元数据标识请求提交spark任务。 2.BaseScheduleCompationActionExecutor会调用继承类SparkRunCompactionExecutor类并调用compact方法构造HoodieSparkMergeOnReadTableCompactor 对象来实现压缩逻辑,完成一切准备操作后向hdfs写入xxx.compation.inflight标识。 3.spark任务执行parallelize加载HooideCompactionPlan 的执行计划,然后调用compact迭代执行每个分区中log的合并逻辑。在 compact会构造HoodieMergelogRecordScanner 扫描文件对象,加载分区中的log构造迭代器遍历log中的数据写入ExtemalSpillableMap。这个ExtemalSpillableMap和cow 模式中内存加载磁盘的map 是一样的。至于合并逻辑是和cow模式的合并逻辑是一样的,这里不重复阐述都是调用cow模式的handleUpdate方法。 4.完成合并操作会构造writeStatus结果信息,并写入xxx.compaction标识到hdfs中完成合并操作。
3.8Hive元数据同步
实现原理比较简单就是根据Hive外表和Hudi表当前表结构和分区做比较,是否有新增字段和新增分区如果有会添加字段和分区到Hive外表。如果不同步Hudi新写入的分区无法查询。在COW模式中只会有ro表(读优化视图,而在mor模式中有ro表(读优化视图)和rt表(实时视图)。
3.9提交成功通知回调
当事务提交成功后向外部系统发送通知消息,通知的方式有两种,一种是发送http服务消息,一种是发送kafka消息。这个通知过程我们可以把清理操作、压缩操作、hive元数据操作,都交给外部系统异步处理或者做其他扩展。也可以自己实现HoodieWriteCommitCallback的接口自定义实现。
4.大数据技术和工具归类
部分术语翻译:
Administration: 管理平台(此处应指大数据管理平台)
Data Security: 数据安全
Data Governance: 数据管控
Data Computing: 数据计算
Data Collection: 数据采集
Data Storage: 数据存储
BI/DATA Visualization: 商务智能可视化/数据可视化
5.数据湖的功能
Data Ingestion(获取数据)
Data Storage(数据存储)
Data Auditing(数据审计)
Data Exploration(数据探索)
Data Lineage(数据继承)
Data Discovery(数据挖掘)
Data Governance(数据管理与处理)
Data Security(数据安全)
Data Quality(数据质量评估)
6.最后
本节篇幅过长,感谢阅读希望对您的学习有所帮助。
创建Hudi
1、创建Hudi


2、在app-11上进行三台机器的认证和启动集群 命令:
sudo /bin/bash
cd /hadoop
./initHosts.sh
su – hadoop
cd /hadoop/
./startAll.sh

通过Spark-shell启动
3、Hudi是高度耦合Spark的,也就是说操作Hudi是依赖Spark。我们的Hudi是在app-13上,打开app-13并以hadoop用户登录。
命令:su - hadoop

4、通过Spark-shell启动
命令:spark-shell --packages org.apache.hudi:hudi-spark-bundle_2.11:0.6.0,org.apache.spark:spark-avro_2.11:2.4.0 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
注:首先指定一个packages包,引用Hudi对Spark支持的jar包,在spark原生包中是没有的,需要通过maven下载下来,下载的这个包后面会有一个版本信息,这个版本信息就是当前的Spark版本信息2.4.0;在指定一个conf需要将Spark的序列方式改成Kryo,Hudi只支持Kryo。
第一次启动的时候速度会比较慢,需要下载spark包。

演示操作
5、导入包 命令:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._

6、设置表名、写出的路径以及本身生成的类 命令:
val tableName = "hudi_trips_cow"
val basePath = "hdfs://dmcluster/tmp/hudi_trips_cow"
val dataGen = new DataGenerator

7、生成一些新的行程,将其加载到DataFrame中,然后将DataFrame写入Hudi表中 命令:
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)

8、查询数据 命令:
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()


9、更新数据 命令:
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)

10、再次查询数据 命令:
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()

11、增量查询 命令:
spark.
read.
format("hudi").
load(basePath + "/*/*/*/*").
createOrReplaceTempView("hudi_trips_snapshot")
val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
val beginTime = commits(commits.length - 2) // commit time we are interested in
// incrementally query data
val tripsIncrementalDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
load(basePath)
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental where fare > 20.0").show()

教师环境
有一些案例的可视化制作结果在学生的环境中被去掉了,如新冠疫苗研发案例,而在教师版本的环境中保留了

教师可以在后台控制学生的devfile权限,详细设置方法参考《高校版管理后台使用手册》。
- 启动mysql,并创建mysql数据源连接,显示名称设置为she

- 允许数据源she上传数据




如果数据源不允许数据源上传数据,则当上传数据时会弹出错误信息如下,

- 上传数据
superset以Dataset名称作为唯一索引,因此不能重名,尽管两个Dataset来源于不同数据源,

详细操作过程参见以下视频,
- 选择对应Dataset,按"Travel Class"分类计算总的cost(SUM(Cost))


详细操作过程参见以下视频,
作业
1、完成案例研究-新冠疫苗研发可视化,其中左上角的markdown chart中的文字可以自己随便输入。
2、通过前面课程学习,请推理分析superset主要使用什么语言编写的?这里的重点是推理分析,而不是上网查询,因为上网查询很容易得出结论,在我们的课程视频讲解中有很多细节隐含了这个问题的答案。此外,需要注意,这个问题中使用“主要”这个定语,因为很多大型软件系统使用多种编程语言协同开发,但通常最核心部分使用的语言决定了这个软件系统特点。
安装视频教程
相关资源
1、solr下载地址:https://archive.apache.org/dist/lucene/solr/7.7.3/solr-7.7.3.tgz
编译视频教程
编译步骤
1、创建solr集群,谨记先不要启动集群;集群创建完成后进入solrC2节点
2、如果当前用户不是root,则sudo /bin/bash 切换到root用户下
3、在root用户下,su - hadoop,切换到hadoop用户下,因为hadoop环境配套的jdk、maven、git等工具均在hadoop用户下安装而root用户下没有配置相应的环境变量
4、mkdir /tmp/atlas
5、cd /tmp/atlas
6、wget --no-check-certificate https://dlcdn.apache.org/atlas/2.1.0/apache-atlas-2.1.0-sources.tar.gz
7、tar -xf apache-atlas-2.1.0-sources.tar.gz
8、cd apache-atlas-sources-2.1.0
9、export MAVEN_OPTS="-Xms4g -Xmx4g"
10、sed -i 's@1.8.0-151@1.8.0-131@' pom.xml
如果不安装上面步骤修改pom.xml,则会出现如下错误信息:
[WARNING] Rule 1: org.apache.maven.plugins.enforcer.RequireJavaVersion failed with message:
** JAVA VERSION ERROR ** Java 8 (Update 151) or above is required.
11、mvn clean -DskipTests package -Pdist
拷贝编译结果
12、在hadoop用户下,mkdir /hadoop/Atlas
13、cd distro/target/
14、cp apache-atlas-2.1.0-server.tar.gz /hadoop/Atlas/
15、cp apache-atlas-2.1.0-hive-hook.tar.gz /hadoop/Atlas/
不修改pom.xml中jdk版号出现的错误信息
编译过程录屏
安装配置视频教程
创建solr索引视频教程
启动atlas视频教程
安装步骤
1、solrC1节点,启动整个集群
2、solrC2节点,在hadoop用户下,cd /hadoop/Atlas
3、tar -xf apache-atlas-2.1.0-server.tar.gz
4、cd apache-atlas-2.1.0
5、修改conf/atlas-application.properties
1)HBase相关配置
atlas.graph.storage.hostname=app-11:2181,app-12:2181,app-13:2181
2)Solr相关配置
atlas.graph.index.search.solr.zookeeper-url=app-11:2181,app-12:2181,app-13:2181
3)Kafka相关配置
atlas.notification.embedded=false
atlas.kafka.data=/hadoop/Kafka/kafka_2.11-2.2.0/kafka-logs
atlas.kafka.zookeeper.connect=app-11:2181,app-12:2181,app-13:2181
atlas.kafka.bootstrap.servers=app-11:9092,app-12:9092,app-13:9092
4)Atlas Server相关配置
atlas.rest.address=http://app-12:21000
atlas.server.run.setup.on.start=false
atlas.audit.hbase.zookeeper.quorum=app-11:2181,app-12:2181,app-13:2181
5)增加Hive相关配置
#Apache Atlas Hook & Bridge for Apache Hive
atlas.hook.hive.synchronous=false
atlas.hook.hive.numRetries=3
atlas.hook.hive.queueSize=10000
atlas.cluster.name=primary
6、修改atlas-env.sh
增加
export HBASE_CONF_DIR=/hadoop/HBase/hbase-2.2.0/conf
7、集成Hive
1)在/hadoop/Hive/apache-hive-3.1.1-bin/conf/hive-site.xml中增加
<property><name>hive.exec.post.hooks</name><value>org.apache.atlas.hive.hook.HiveHook</value></property>
2)拷贝atlas-application.properties到hive的conf目录下
cp /hadoop/Atlas/apache-atlas-2.1.0/conf/atlas-application.properties /hadoop/Hive/apache-hive-3.1.1-bin/conf/
3)解压hive-hook到atlas-2.1.0目录下
tar -xf /hadoop/Atlas/apache-atlas-2.1.0-hive-hook.tar.gz -C /hadoop/Atlas/apache-atlas-2.1.0/ --strip-components 1
4)拷贝hive-hook的所有jar包到hive的lib目录下
cp -r /hadoop/Atlas/apache-atlas-2.1.0/hook/hive/* /hadoop/Hive/apache-hive-3.1.1-bin/lib/
8、创建solr索引
/hadoop/Solr/solr-7.7.3/bin/solr create -c vertex_index -d /hadoop/Atlas/apache-atlas-2.1.0/conf/solr -shards 3 -replicationFactor 2
/hadoop/Solr/solr-7.7.3/bin/solr create -c edge_index -d /hadoop/Atlas/apache-atlas-2.1.0/conf/solr -shards 3 -replicationFactor 2
/hadoop/Solr/solr-7.7.3/bin/solr create -c fulltext_index -d /hadoop/Atlas/apache-atlas-2.1.0/conf/solr -shards 3 -replicationFactor 2
9、启动Atlas
nohup /bin/python /hadoop/Atlas/apache-atlas-2.1.0/bin/atlas_start.py > /hadoop/Atlas/apache-atlas-2.1.0/startAtlas.log 2>&1 &
启动atlas过程录屏
注意事项
如果直接创建而不是通过自己编译源码、手动安装部署方式创建的atlas集群,仍需要数据初次导入建表操作
1)创建临时库
CREATE DATABASE IF NOT EXISTS youtube;
USE youtube;
2)创建表
DROP TABLE IF EXISTS `userid`;
CREATE EXTERNAL TABLE IF NOT EXISTS `userid` (
id STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
LOCATION '/user/hive/warehouse/youtube.db/data/userid.txt';
DROP TABLE IF EXISTS `users`;
CREATE EXTERNAL TABLE IF NOT EXISTS `users` (
id STRING,
uploads INT,
watches INT,
friends INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
LOCATION '/user/hive/warehouse/youtube.db/data/user.txt';
3)数据加载
insert into table userid select id from users;
4)创建表
DROP TABLE IF EXISTS `users2`;
CREATE EXTERNAL TABLE IF NOT EXISTS `users2` (
id STRING,
uploads INT,
watches INT,
friends INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
LOCATION '/user/hive/warehouse/youtube.db/data/user2.txt';
5)再次数据加载
insert into table userid select id from users2;作业
1、根据架构原理、安装与配置、数据初次导入、数据血缘关系管理章节,总结分析atlas server与hook运行机制。
Linux操作系统和Python语言快速入门
详细学习内容可观看Spark快速大数据处理扫一扫~~~或者引擎搜索Spark余海峰
网站操作提示
1. 操作提示
对于使用微信点击链接的方式访问的用户
-
点击红色框的图标可以展开/关闭左侧导航栏。
-
在绿色导航栏中触摸滑动可以看见更多导航菜单。
-
这里提及的地址 http://she.kinginsai.com、http://she-she.dev.kinginsai.com 均为She平台C端版本地址,对于部署了She平台的高校用户,请使用私有部署的地址。
-
由于微信可能会有网页缓存,可以点击页面刷新获取最新内容。手册、课程平台等会不定期更新,如果您的微信页面缓存时间正好在更新周期内、则可能浏览的是过期的页面内容。
关于视频清晰度问题
所有视频都是高清的,由于网络等综合原因,可能有时打开课程、手册中的视频时清晰度非常差,此时请反复调节视频播放的清晰度以获取高清界面,如高清->标清->高清。
学苑网课中心
松鼠学苑发展历程

主营业务

She教研解决方案
1、远端浏览器,从Google、GitHub、Maven等获取技术资源不再有羁绊。
2、基于Devfile的、一键式、无差别构建,基于账号的隔离独享环境,基于浏览器的全新开发模式,让你和你的 小伙伴的软件工程环境精准的一致,而且能随心所欲的创建一个新的属于你的环境。
3、全系列、分步骤镜像,让你的大数据能够从任一成功阶段继续,从裸Linux到Zookeeper、Hadoop、Tez、 Hive、Spark、Oozie、HBase,到Kafka、Flink、Ambari,All in One的Jupyter,最新版本的TensorFlow, 使用你擅长的任一语言,Python、Java、Scala、R、Julia。
4、无需任何配置,只要bind任一端口,你的应用便自动地expose出去,自动配置域名。
She平台架构

She是构建在docker/k8s之上、用于软件开发调试的大数据平台,平 台本身是架构在大数据集群之上的分布式系统,包括三层:计算资源管 理层、She核心调度层、应用层,应用层集合了所有课程环境,Devfile 和Workspace是其中两个核心概念:
1.Devfile是开展某项软件类开发任务所需环境的定义,那么将这个草稿 建设起来的就是Workspace,即Workspace是物理的、而Devfile是逻辑 的、是静态的:Workspace包括了物理上运行的各容器或物理机实体、端 口、命名等一干看得见摸得着的资源,所以Devfile定义了某个实训任务 的资源需求情况,如CPU、GPU、Memory、Disk等,而运行中的Work space的则实际占有了这些资源,因此,从这个意义上看,具体的实训 任务决定了She平台的硬件配置需求。
2.Devfile是She平台的预置环境,即其对应的Workspace中已经安装了 一系列版本号确定的工具,这些工具集的选择是根据这项开发任务的通 用需求而定的,是通用的;但是我们可以根据需要卸载、升级、安装相 应工具。
HFS三节点集群拓扑结构
为了降低实训成本,我们以三节点为例搭建HFS集群,但这个集群理论上可以水平扩展到10万点的规模。